

导读:为了解决大数据、AI 等数据密集型应用在云原生计算存储分离场景下,存在的数据 访问延时高、联合分析难、多维管理杂等痛点问题,南京大学 PASALab、阿里巴巴、Alluxio 在 2020 年 9 月份联合发起了开源项目 Fluid。
Fluid 是云原生环境下数据密集型应用的高效支撑平台,项目自开源发布以来吸引了众多相关方向领域专家和工程师的关注,在大家的积极反馈下社区的开发工作进展迅速。近期 Fluid 0.3 版本正式发布,主要新增了三项重要功能,分别是:
- 实现通用数据存储加速,提供 Kubernetes 数据卷访问加速功能
- 加强数据访问安全保护,提供面向数据集的细粒度权限控制功能
- 简化用户复杂参数配置,提供原生化系统内部参数配置优化功能
这三大主要功能的开发需求来自众多社区用户的生产实际反馈,此外 Fluid v0.3 还进行了一些 bug 修复和文档更新,欢迎使用体验 Fluid v0.3!感谢为此版本做出贡献的社区小伙伴,我们会继续广泛关注和采纳社区建议,推动 Fluid 项目的发展,期待听到大家更多的反馈!
下文是本次新版本发布功能的进一步介绍。
1. 支持 Kubernetes 数据卷访问加速
尽管之前版本的 Fluid 已经支持诸多底层存储系统(如 HDFS、OSS 等),但在实际生产环境中,企业内部的存储系统往往更加多样,因存储系统不兼容而无法对接 Fluid 的情况仍然存在。例如用户使用 Lustre 分布式文件系统,由于之前的 Fluid 所使用的分布式缓存引擎尚不兼容 Lustre 系统,因此该用户将无法正常使用 Fluid。
为了提升 Fluid 在云原生数据访问加速场景的通用性,Fluid v0.3. 增加了对数据卷 Persistent Volume Claim (PVC) 和主机目录(Host Path)挂载的加速支持,从而为各类存储系统与 Fluid 的对接提供了一种通用化加速方案:无论使用哪一种底层存储系统,只要该存储系统可被映射为 Kubernetes 原生的数据卷 PVC 资源对象或者集群节点上的主机目录,那么它就可以通过 Fluid 享受到如分布式数据缓存、数据亲和性调度等功能特性带来的优势。其基本概念如下图所示:
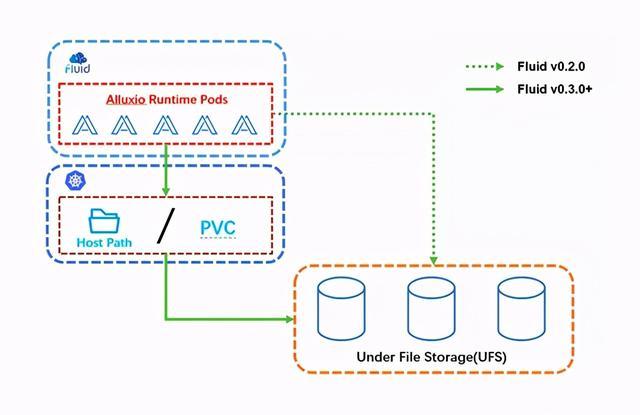
具体使用方法非常简单,用户只需在 mountPoint 中指定 pvc://nfs-imagenet,其中 nfs-imagenet 是 Kubernetes 集群中已有数据卷。
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: fluid-imagenet
spec:
mounts:
- mountPoint: pvc://nfs-imagenet
name: nfs-imagenet
我们通过 TensorFlow Benchmark 训练 ResNet-50 模型为测试场景,验证了 PVC 访问加速能力,以下是速度提升结果:
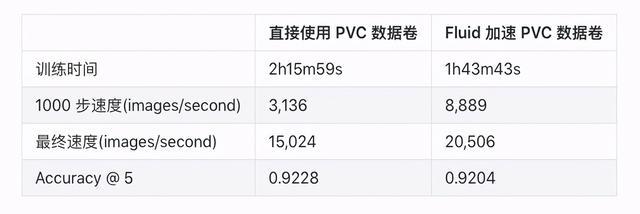
从评估结果来看,Fluid 所提供的分布式缓存能力都能够提升整个训练任务的速度,缩短整体训练时间超过 20%。
2. 数据集的访问权限控制
很多提供机器学习平台服务的企业存在多用户共享存储系统情况和场景。出于安全性考虑,机器学习平台服务提供商需要进行严格的访问权限控制以保障用户之间的数据隔离性,即任何未经授权的用户不得随意访问他人数据集。
Fluid 在 v0.3 中提供了对上述场景的支持:多用户共享的底层存储系统挂载到 Fluid 后,Fluid 暴露出的文件权限信息(如所属用户、文件模式等)将与底层存储系统保持一致,即实现了文件从底层存储系统到部署 Fluid 的节点的透传。这也就意味着底层存储系统中的访问权限控制同样将在部署 Fluid 的各个节点上生效,以此保证用户之间的数据隔离性不被破坏。
除此以外,Fluid v0.3 还提供了数据集“临时借用”的功能特性。“临时借用”指的是某用户需要拥有临时访问所属另一个用户的某个数据集的权限。在 Fluid v0.3 中,管理员可通过灵活的配置在部署 Fluid 的节点上完成数据集所有权的转换,以赋予指定用户“临时借用”他人数据集的能力,这能够帮助集群管理员实现更细粒度和灵活的数据集权限管理。
3. 默认参数配置优化
Fluid 提供了很多参数配置供用户定制化自己的应用,在 Fluid 0.3 版本之前,用户需要根据实际环境和业务目标完全自行进行手工配置,然而手工完成配置优化工作对于大部分用户而言是比较困难且工作量繁重的。
Fluid v0.3 内置了大量面向 Alluxio 和 Fuse 等内部组件的默认参数配置优化,用户不再需要将大量精力放在参数配置调优上。根据我们经验优化后的默认参数设置能够在大部分 Fluid 常见使用场景下获得较好性能。
总结
Fluid v0.3 主要解决社区用户在实际生产环境中反馈的问题和需求。对主机目录和 PVC 挂载的支持为兼容不同的底层存储系统给出了一个通用的解决方案;数据集的访问权限控制让 Fluid 能够真正满足多用户共享的实际生产环境的需求;优化后的默认参数配置增加了 Fluid 的易用性,并在多数场景下保持性能的稳定。
作者 | 顾荣 南京大学 PASALab
本文为阿里云原创内容,未经允许不得转载。












