

线上问题不同于开发期间的 bug,与运行时环境、压力、并发情况、具体的业务相关。对于线上的问题利用线上环境可用的工具,收集必要信息 对定位问题十分重要。
1
服务上常见问题
所有 Java 服务的线上问题从系统表象来看归结起来总共有四方面:CPU、内存、磁盘、网络。例如 CPU 使用率峰值突然飚高、内存溢出(泄露)、磁盘满了、网络流量异常、FullGC 等等问题。基于这些现象我们可以将线上问题分成两大类: 系统异常、业务服务异常。
- 系统异常
常见的系统异常现象包括: CPU 占用率过高、CPU上下文切换频率次数较高、磁盘满了、磁盘 I/O 过于频繁、系统可用内存长期处于较低值(导致 oom killer)、网络流量异常(连接数过多)等等。这些问题可以通过 top(cpu)、free(内存)、df(磁盘)、dstat(网络流量)、strace(底层系统调用)、pstack、vmstat、等工具获取系统异常现象数据。
常见的业务服务异常现象包括: PV 量过高、服务调用耗时异常、线程死锁、多线程并发问题、频繁进行 Full GC、异常安全攻击扫描等
2
问题定位
我们一般会采用排除法,从外部排查到内部排查的方式来定位线上服务问题。
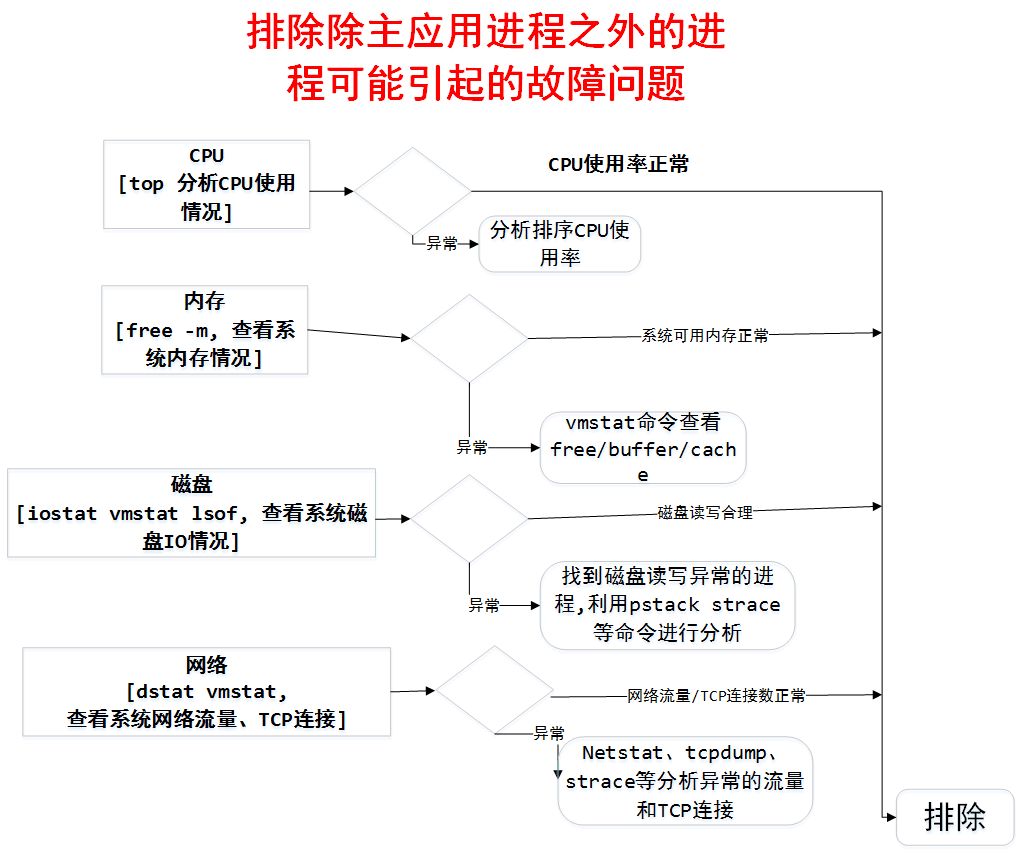
首先我们要排除其他进程(除主进程之外)可能引起的故障问题
其次排除业务应用可能引起的故障问题
最后可以考虑是否为运营商或者云服务提供商所引起的故障
定位流程
- 系统异常排查流程
- 业务应用排查流程
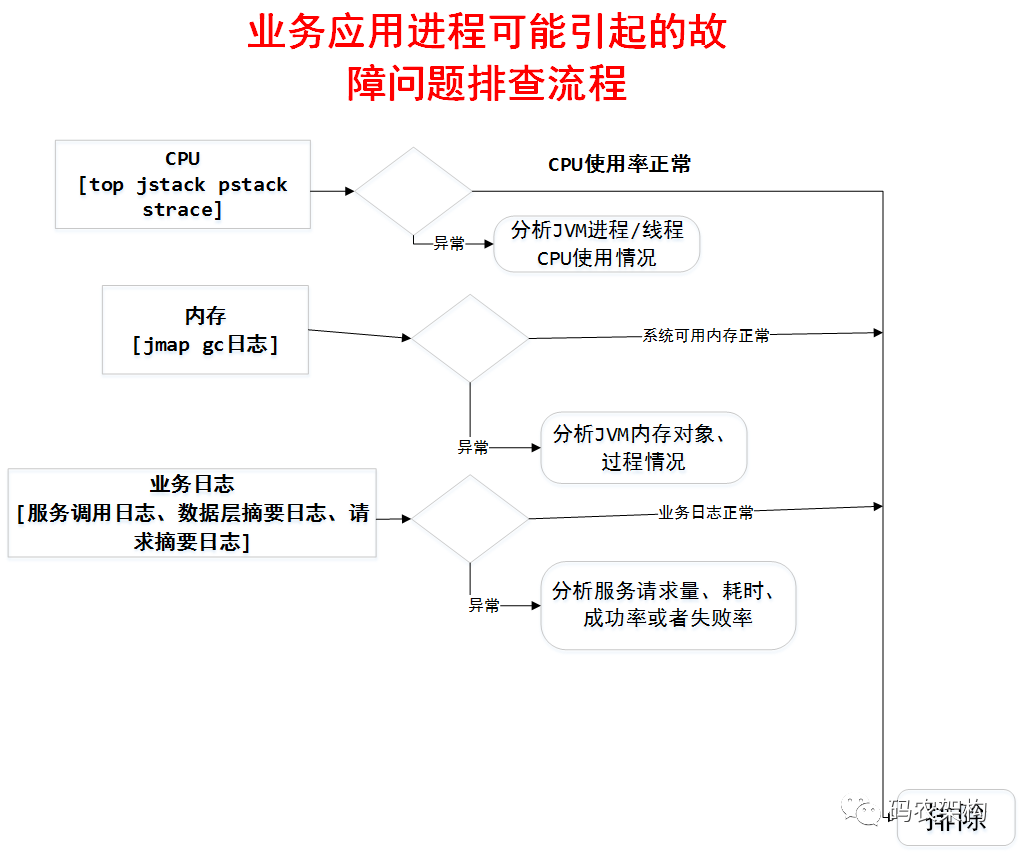
Linux常见的性能分析工具
Linux 常用的性能分析工具使用包括 : top(cpu)、df(磁盘)、free(内存)、、dstat(网络流量)、vmstat、pstack、strace(底层系统调用)等。
- CPU
CPU 是系统重要的监控指标,能够分析系统的整体运行状况。监控指标一般包括运行队列、_CPU_使用率和上下文切换等。
_top命令是_Linux_下常用的 CPU 性能分析工具,能够实时显示系统中各个进程的资源占用状况,常用于服务端性能分析_。
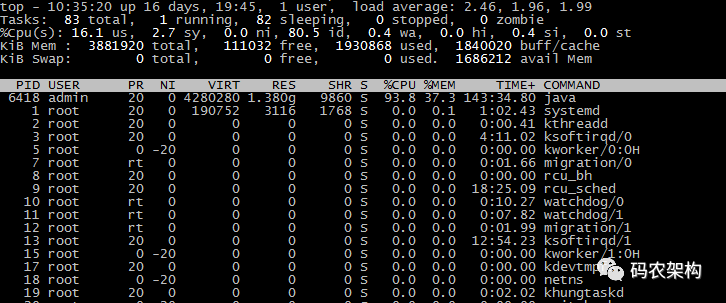
top 命令显示了各个进程 CPU 使用情况,一般 CPU 使用率从高到低排序展示输出。其中 Load Average 显示最近1分钟、5分钟和15分钟的系统平均负载,上图各值为2.46,1.96,1.99。
我们一般会关注 CPU 使用率最高的进程,正常情况下就是我们的应用主进程。第七行以下:各进程的状态监控。
PID : 进程idUSER : 进程所有者PR : 进程优先级NI : nice值。负值表示高优先级,正值表示低优先级VIRT : 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RESRES : 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATASHR : 共享内存大小,单位kbS : 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程%CPU : 上次更新到现在的CPU时间占用百分比%MEM : 进程使用的物理内存百分比TIME+ : 进程使用的CPU时间总计,单位1/100秒COMMAND : 进程名称
- 内存
内存是排查线上问题的重要参考依据,内存问题很多时候是引起 CPU 使用率较高的见解因素。
系统内存:free 是显示的当前内存的使用,-m 的意思是M字节来显示内容。
free -m

部分参数说明:
total 内存总数: 3790M used 已经使用的内存数: 1880M free 空闲的内存数: 118M shared 当前已经废弃不用,总是0 buffers Buffer 缓存内存数: 1792M
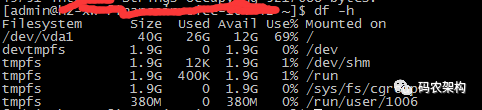
- 磁盘
磁盘满了很多时候会连带引起系统服务不可用等问题
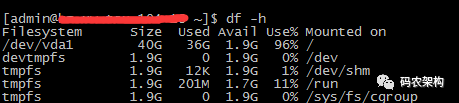
df -h
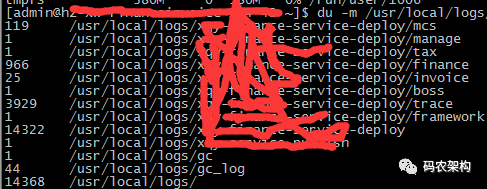
du -m /path
- 网络
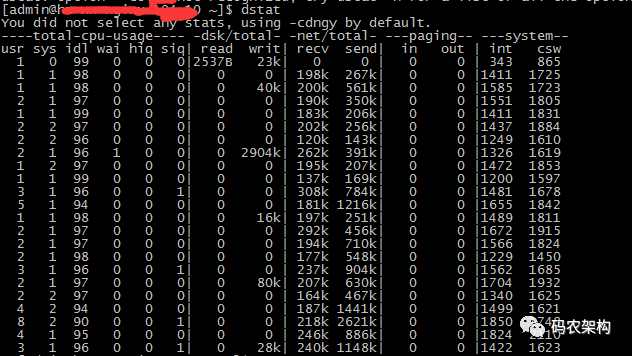
dstat 命令可以集成了 vmstat、iostat、netstat 等等工具能完成的任务。
dstat -c cpu情况 -d 磁盘读写 -n 网络状况 -l 显示系统负载 -m 显示形同内存状况 -p 显示系统进程信息 -r 显示系统IO情况
- 其它
vmstat:
vmstat 2 10 -t
vmstat 是 Virtual Meomory Statistics(虚拟内存统计)的缩写, 是实时系统监控工具。该命令通过使用 knlist 子程序和 /dev/kmen 伪设备驱动器访问这些数据,输出信息直接打印在屏幕。
使用 vmstat 2 10 -t命令,查看 io 的情况 (第一个参数是采样的时间间隔数单位是秒,第二个参数是采样的次数)。
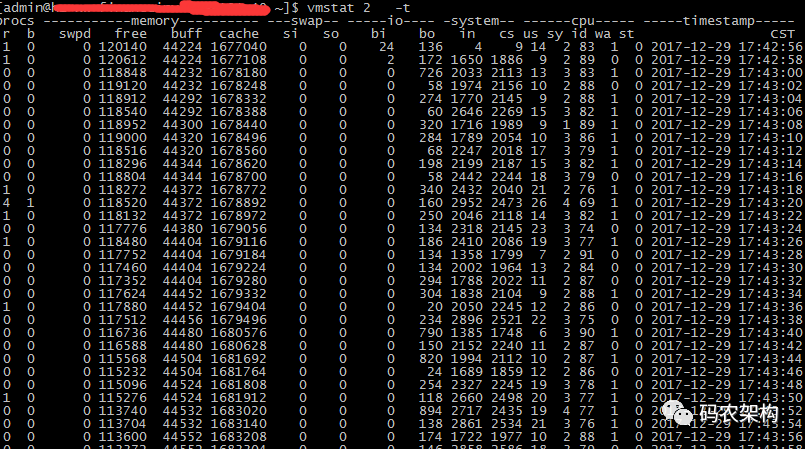
r 表示运行队列(就是说多少个进程真的分配到CPU),b 表示阻塞的进程。 swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。free 空闲的物理内存的大小,我的机器内存总共4G,剩余120M左右。buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用40多Mcache 文件缓存si列表示由磁盘调入内存,也就是内存进入内存交换区的数量;so列表示由内存调入磁盘,也就是内存交换区进入内存的数量一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示系统内存不足,需要考虑是否增加系统内存。 bi 从块设备读入数据的总量(读磁盘)(每秒kb)bo 块设备写入数据的总量(写磁盘)(每秒kb)随机磁盘读写的时候,这两个值越大((超出1024k),能看到cpu在IO等待的值也会越大这里设置的bi+bo参考值为1000,如果超过1000,而且wa值比较大,则表示系统磁盘IO性能瓶颈。in 每秒CPU的中断次数,包括时间中断cs(上下文切换Context Switch)
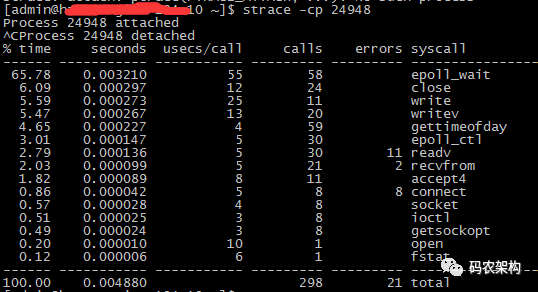
strace:strace常用来跟踪进程执行时的系统调用和所接收的信号。
strace -cp tidstrace -T -p tid -T 显示每一调用所耗的时间. -p pid 跟踪指定的进程pid. -v 输出所有的系统调用.一些调用关于环境变量,状态,输入输出等调用由于使用频繁,默认不输出. -V 输出strace的版本信息.
JVM 定位问题工具
在 JDK 安装目录的 bin 目录下默认提供了很多有价值的命令行工具。每个小工具体积基本都比较小,因为这些工具只是 jdk\lib\tools.jar 的简单封装。
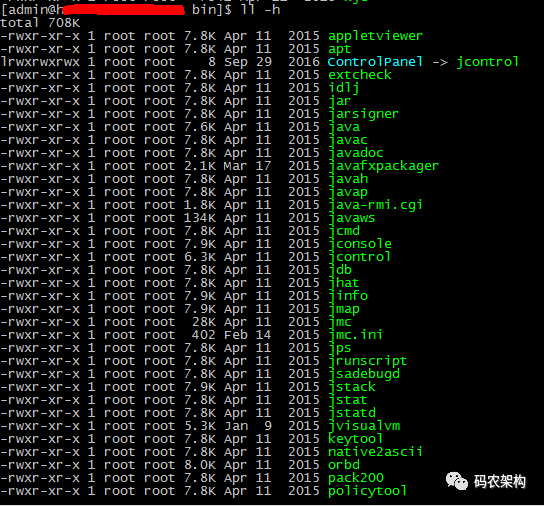
其中,定位排查问题时最为常用命令包括:jps(进程)、jmap(内存)、jstack(线程)、jinfo(参数)等。
jps:查询当前机器所有JAVA进程信息
jmap:输出某个 Java 进程内存情况(如产生那些对象及数量等)
jstack:打印某个 Java 线程的线程栈信息
jinfo:用于查看 jvm 的配置参数
jps 命令
jps 用于输出当前用户启动的所有进程 ID,当线上发现故障或者问题时,能够利用 jps 快速定位对应的 Java 进程 ID。
jps -l -m-m -l -l参数用于输出主启动类的完整路径

当然,我们也可以使用 Linux 提供的查询进程状态命令,例如:
ps -ef | grep tomcat
我们也能快速获取 Tomcat 服务的进程 id。
jmap 命令
jmap -heap pid 输出当前进程JVM堆新生代、老年代、持久代等请情况,GC使用的算法等信息jmap -histo:live {pid} | head -n 10 输出当前进程内存中所有对象包含的大小jmap -dump:format=b,file=/usr/local/logs/gc/dump.hprof {pid} 以二进制输出档当前内存的堆情况,然后可以导入MAT等工具进行
JMap(Java Memory Map)可以输出所有内存中对象的工具,甚至可以将 VM 中的 heap,以二进制输出成文本。
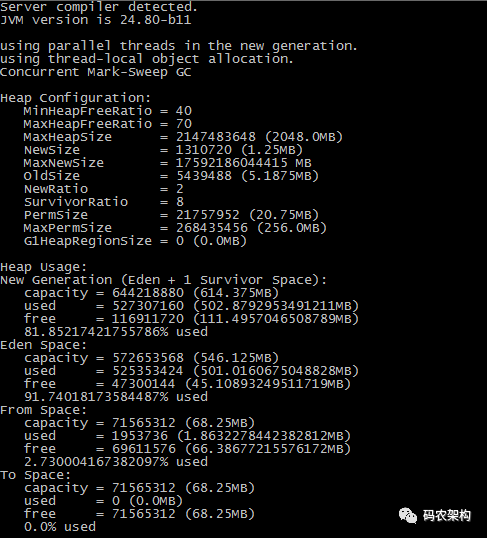
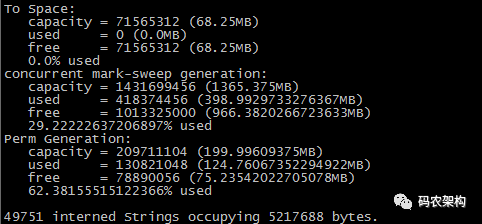
jmap -heap pid:
jmap -heap pid 输出当前进程JVM堆新生代、老年代、持久代等请情况,GC使用的算法等信息
jmap 可以查看 JVM 进程的内存分配与使用情况,使用 的 GC 算法等信息。
jmap -histo:live {pid} | head -n 10:
jmap -histo:live {pid} | head -n 10 输出当前进程内存中所有对象包含的大小
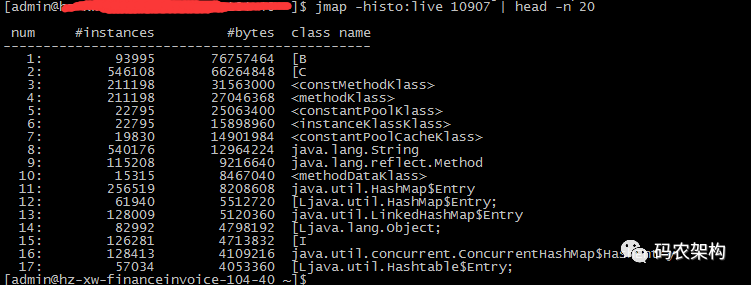
输出当前进程内存中所有对象实例数(instances)和大小(bytes),如果某个业务对象实例数和大小存在异常情况,可能存在内存泄露或者业务设计方面存在不合理之处。
jmap -dump:
jmap -dump:format=b,file=/usr/local/logs/gc/dump.hprof {pid}
-dump:formate=b,file= 以二进制输出当前内存的堆情况至相应的文件,然后可以结合 MAT 等内存分析工具深入分析当前内存情况。
一般我们要求给 JVM 添加参数 -XX:+Heap Dump On Out Of Memory Error OOM 确保应用发生 OOM 时 JVM 能够保存并 dump 出当前的内存镜像。当然如果你决定手动 dump 内存时,dump 操作占据一定 CPU 时间片、内存资源、磁盘资源等,因此会带来一定的负面影响。
此外,dump 的文件可能比较大,一般我们可以考虑使用zip命令对文件进行压缩处理,这样在下载文件时能减少带宽的开销。在下载 dump 文件完成之后,由于 dump 文件较大可将 dump 文件备份至制定位置或者直接删除,以释放磁盘在这块的空间占用。
jstack 命令
printf '%x\n' tid --> 10进制至16进制线程ID(navtive线程) %d 10进制jstack pid | grep tid -C 30 --color ps -mp 8278 -o THREAD,tid,time | head -n 40
某 Java 进程 CPU 占用率高,我们想要定位到其中 CPU 占用率最高的线程。
(1) 利用 top 命令可以查出占 CPU 最高的线程 pid
top -Hp {pid}
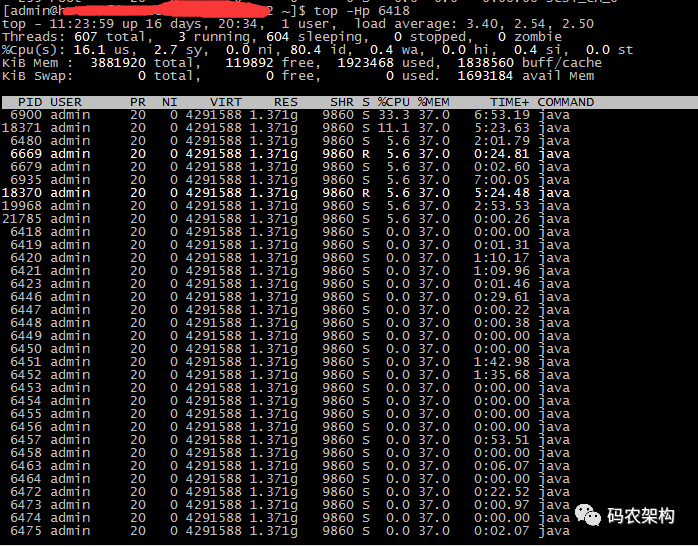
(2) 占用率最高的线程 ID 为 6900,将其转换为16进制形式(因为 java native 线程以16进制形式输出)
printf '%x\n' 6900

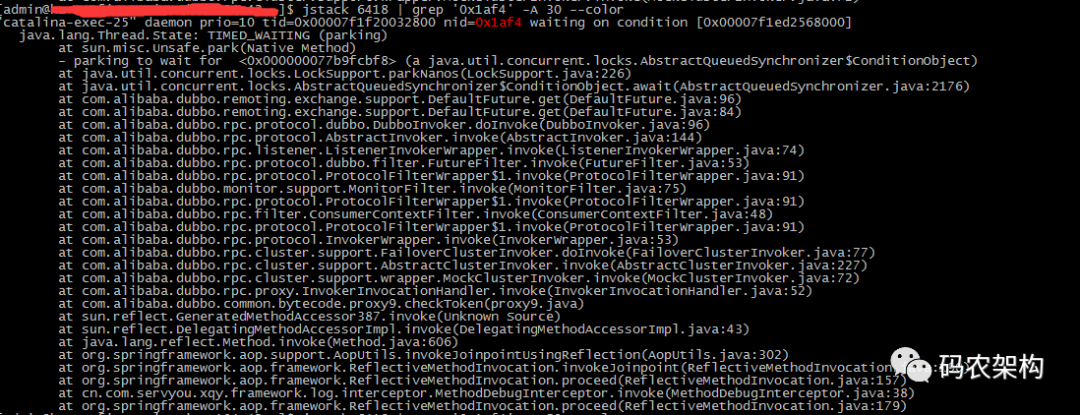
(3) 利用 jstack 打印出 Java 线程调用栈信息
jstack 6418 | grep '0x1af4' -A 50 --color
jinfo 命令
查看某个JVM参数值jinfo -flag ReservedCodeCacheSize 28461jinfo -flag MaxPermSize 28461
jstat 命令
jstat -gc pidjstat -gcutil
pgrep -u admin java
3
日志分析
GC日志分析
- GC 日志详细分析
Java 虚拟机 GC 日志是用于定位问题重要的日志信息,频繁的 GC 将导致应用吞吐量下降、响应时间增加,甚至导致服务不可用。
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/usr/local/gc/gc.log -XX:+UseConcMarkSweepGC
我们可以在 Java 应用的启动参数中增加**-XX:+PrintGCDetails **可以输出 GC 的详细日志,例外还可以增加其他的辅助参数,如 -Xloggc 制定 GC 日志文件地址。如果你的应用还没有开启该参数,下次重启时请加入该参数。
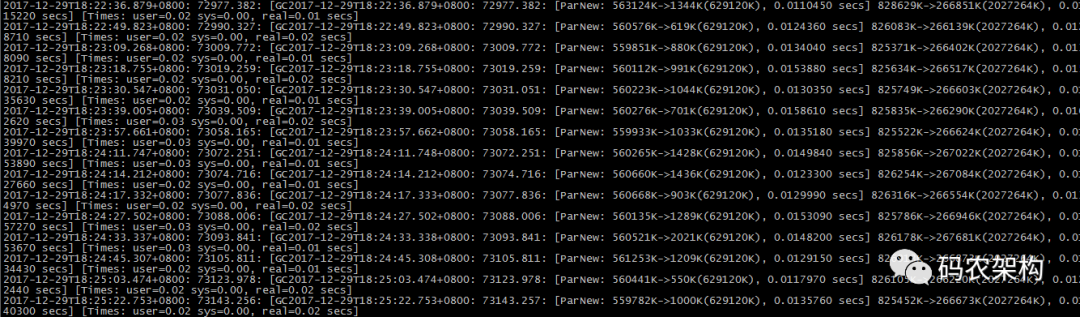
上图为线上某应用在平稳运行状态下的GC日志截图。
2017-12-29T18:25:22.753+0800: 73143.256: [GC2017-12-29T18:25:22.753+0800: 73143.257: [ParNew: 559782K->1000K(629120K), 0.0135760 secs] 825452K->266673K(2027264K), 0.0140300 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
[2017-12-29T18:25:22.753+0800: 73143.256] : 自JVM启动73143.256秒时发生本次GC.[ParNew: 559782K->1000K(629120K), 0.0135760 secs] : 对新生代进行的GC,使用ParNew收集器,559782K是新生代回收前的大小,1000K是新生代回收后大小,629120K是当前新生代分配的内存总大小, 0.0135760 secs表示本次新生代回收耗时 0.0135760秒[825452K->266673K(2027264K), 0.0140300 secs]:825452K是回收堆内存大小,266673K是回收堆之后内存大小,2027264K是当前堆内存总大小,0.0140300 secs表示本次回收共耗时0.0140300秒[Times: user=0.02 sys=0.00, real=0.02 secs] : 用户态耗时0.02秒,系统态耗时0.00,实际耗时0.02秒
无论是 minor GC 或者是 Full GC,我们主要关注 GC 回收实时耗时, 如 real=0.02secs,即 stop the world 时间,如果该时间过长,则严重影响应用性能。
- CMS GC 日志分析
Concurrent Mark Sweep(CMS)是老年代垃圾收集器,从名字(Mark Sweep)可以看出,CMS 收集器就是“标记-清除”算法实现的,分为六个步骤:
初始标记(STW initial mark)
并发标记(Concurrent marking)
并发预清理(Concurrent precleaning)
重新标记(STW remark)
并发清理(Concurrent sweeping)
并发重置(Concurrent reset)
其中初始标记(STW initial mark) 和 重新标记(STW remark)需要“Stop the World”。
初始标记 :在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法 STW(Stop The Word)。这个过程从垃圾回收的"根对象"开始,只扫描到能够和"根对象"直接关联的对象,并作标记。所以这个过程虽然暂停了整个 JVM,但是很快就完成了。
并发标记 :这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。
并发预清理 :并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段"重新标记"的工作,因为下一个阶段会 Stop The World。
重新标记 :这个阶段会暂停虚拟机,收集器线程扫描在 CMS 堆中剩余的对象。扫描从"跟对象"开始向下追溯,并处理对象关联。
并发清理 :清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。
并发重置 :这个阶段,重置 CMS 收集器的数据结构,等待下一次垃圾回收。
CMS 使得在整个收集的过程中只是很短的暂停应用的执行,可通过在 JVM 参数中设置 -XX:UseConcMarkSweepGC 来使用此收集器,不过此收集器仅用于 old 和 Perm(永生)的对象收集。CMS 减少了 stop the world 的次数,不可避免地让整体 GC 的时间拉长了。
Full GC 的次数说的是 stop the world 的次数,所以一次 CMS 至少会让 Full GC 的次数+2,因为 CMS Initial mark 和 remark 都会 stop the world,记做2次。而 CMS 可能失败再引发一次 Full GC。
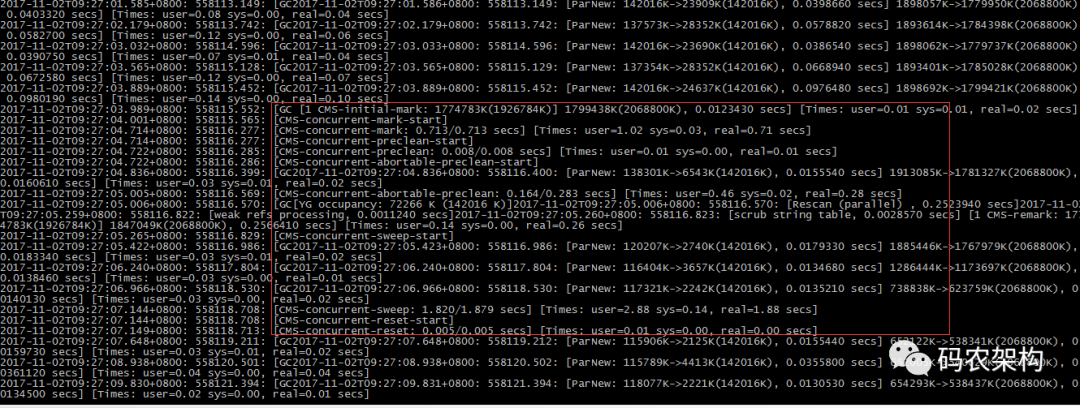
上图为线上某应用在进行 CMS GC 状态下的 GC 日志截图。
2017-11-02T09:27:03.989+0800: 558115.552: [GC [1 CMS-initial-mark: 1774783K(1926784K)] 1799438K(2068800K), 0.0123430 secs] [Times: user=0.01 sys=0.01, real=0.02 secs] 2017-11-02T09:27:04.001+0800: 558115.565: [CMS-concurrent-mark-start]2017-11-02T09:27:04.714+0800: 558116.277: [CMS-concurrent-mark: 0.713/0.713 secs] [Times: user=1.02 sys=0.03, real=0.71 secs] 2017-11-02T09:27:04.714+0800: 558116.277: [CMS-concurrent-preclean-start]2017-11-02T09:27:04.722+0800: 558116.285: [CMS-concurrent-preclean: 0.008/0.008 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] 2017-11-02T09:27:04.722+0800: 558116.286: [CMS-concurrent-abortable-preclean-start]2017-11-02T09:27:04.836+0800: 558116.399: [GC2017-11-02T09:27:04.836+0800: 558116.400: [ParNew: 138301K->6543K(142016K), 0.0155540 secs] 1913085K->1781327K(2068800K), 0.0160610 secs] [Times: user=0.03 sys=0.01, real=0.02 secs] 2017-11-02T09:27:05.005+0800: 558116.569: [CMS-concurrent-abortable-preclean: 0.164/0.283 secs] [Times: user=0.46 sys=0.02, real=0.28 secs] 2017-11-02T09:27:05.006+0800: 558116.570: [GC[YG occupancy: 72266 K (142016 K)]2017-11-02T09:27:05.006+0800: 558116.570: [Rescan (parallel) , 0.2523940 secs]2017-11-02T09:27:05.259+0800: 558116.822: [weak refs processing, 0.0011240 secs]2017-11-02T09:27:05.260+0800: 558116.823: [scrub string table, 0.0028570 secs] [1 CMS-remark: 1774783K(1926784K)] 1847049K(2068800K), 0.2566410 secs] [Times: user=0.14 sys=0.00, real=0.26 secs] 2017-11-02T09:27:05.265+0800: 558116.829: [CMS-concurrent-sweep-start]2017-11-02T09:27:05.422+0800: 558116.986: [GC2017-11-02T09:27:05.423+0800: 558116.986: [ParNew: 120207K->2740K(142016K), 0.0179330 secs] 1885446K->1767979K(2068800K), 0.0183340 secs] [Times: user=0.03 sys=0.01, real=0.02 secs] 2017-11-02T09:27:06.240+0800: 558117.804: [GC2017-11-02T09:27:06.240+0800: 558117.804: [ParNew: 116404K->3657K(142016K), 0.0134680 secs] 1286444K->1173697K(2068800K), 0.0138460 secs] [Times: user=0.03 sys=0.00, real=0.01 secs] 2017-11-02T09:27:06.966+0800: 558118.530: [GC2017-11-02T09:27:06.966+0800: 558118.530: [ParNew: 117321K->2242K(142016K), 0.0135210 secs] 738838K->623759K(2068800K), 0.0140130 secs] [Times: user=0.03 sys=0.00, real=0.02 secs] 2017-11-02T09:27:07.144+0800: 558118.708: [CMS-concurrent-sweep: 1.820/1.879 secs] [Times: user=2.88 sys=0.14, real=1.88 secs] 2017-11-02T09:27:07.144+0800: 558118.708: [CMS-concurrent-reset-start]2017-11-02T09:27:07.149+0800: 558118.713: [CMS-concurrent-reset: 0.005/0.005 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
如果你已掌握 CMS 的垃圾收集过程,那么上面的 GC 日志你应该很容易就能看的懂,这里我就不详细展开解释说明了。
此外 CMS 进行垃圾回收时也有可能会发生失败的情况。
异常情况有:
伴随 prommotion failed,然后 Full GC:
[prommotion failed:存活区内存不足,对象进入老年代,而此时老年代也仍然没有内存容纳对象,将导致一次Full GC]
伴随 concurrent mode failed,然后 Full GC:
[concurrent mode failed:CMS回收速度慢,CMS完成前,老年代已被占满,将导致一次Full GC]
频繁 CMS GC:
[内存吃紧,老年代长时间处于较满的状态]
业务日志
业务日志除了关注系统异常与业务异常之外,还要关注服务执行耗时情况,耗时过长的服务调用如果没有熔断等机制,很容易导致应用性能下降或服务不可用,服务不可用很容易导致雪崩。
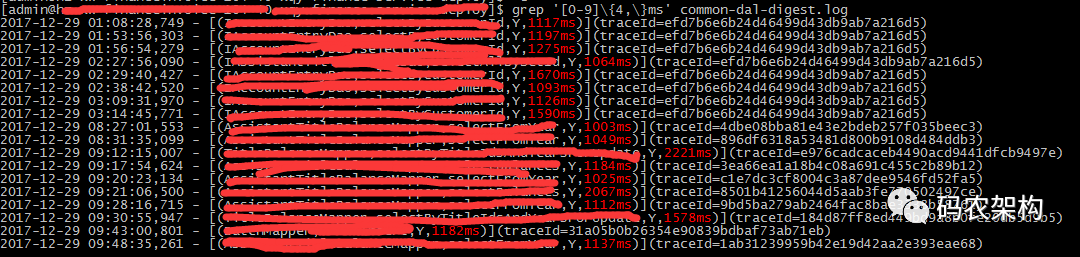
上面是某一接口的调用情况,虽然大部分调用没有发生异常,但是执行耗时相对比较长。
grep '[0-9]{3,}ms' *.log
找出调用耗时大于3位数的dao方法,把3改成4就是大于4位数
互联网应用目前几乎采用分布式架构,但不限于服务框架、消息中间件、分布式缓存、分布式存储等等。那么这些应用日志如何聚合起来进行分析呢? 首先,你需要一套分布式链路调用跟踪系统,通过在系统线程上线文间透传 traceId 和 rpcId,将所有日志进行聚合,例如淘宝的鹰眼,spring cloud zipkin等等



本文分享自微信公众号 - 码农架构(iByteCoding)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











