
作者 | 声东 阿里云售后技术专家
文章来源:Docker,点击查看原文。
以我的经验来讲,理解 Kubernetes 集群服务的概念,是比较不容易的一件事情。尤其是当我们基于似是而非的理解,去排查服务相关问题的时候,会非常不顺利。
这体现在,对于新手来说,ping 不通服务的 IP 地址这样基础的问题,都很难理解;而就算对经验很丰富的工程师来说,看懂服务相关的 iptables 配置,也是有相当的挑战的。
今天这边文章,我来深入解释一下 Kubernetes 集群服务的原理与实现,便于大家理解。
Kubernetes 集群服务的本质是什么
概念上来讲,Kubernetes 集群的服务,其实就是负载均衡、或反向代理。这跟阿里云的负载均衡产品,有很多类似的地方。和负载均衡一样,服务有它的 IP 地址以及前端端口;服务后边会挂载多个容器组 Pod 作为其“后端服务器”,这些“后端服务器”有自己的 IP 以及监听端口。
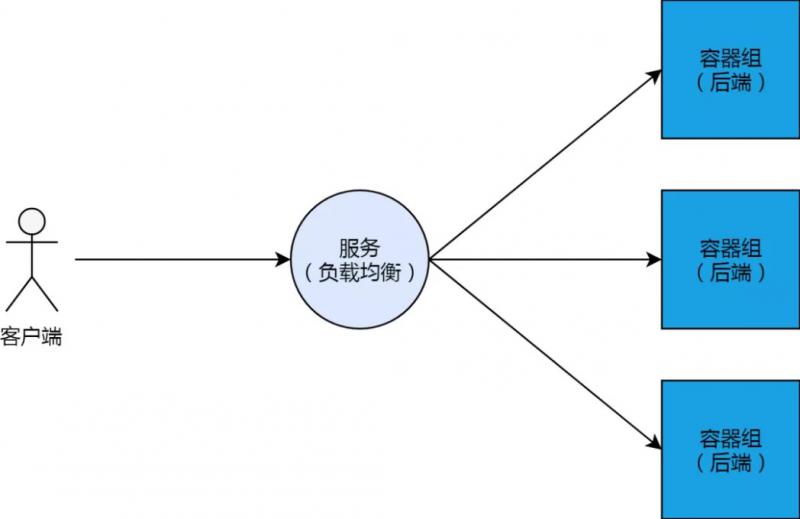
当这样的负载均衡和后端的架构,与 Kubernetes 集群结合的时候,我们可以想到的最直观的实现方式,就是集群中某一个节点专门做负载均衡(类似 LVS)的角色,而其他节点则用来负载后端容器组。
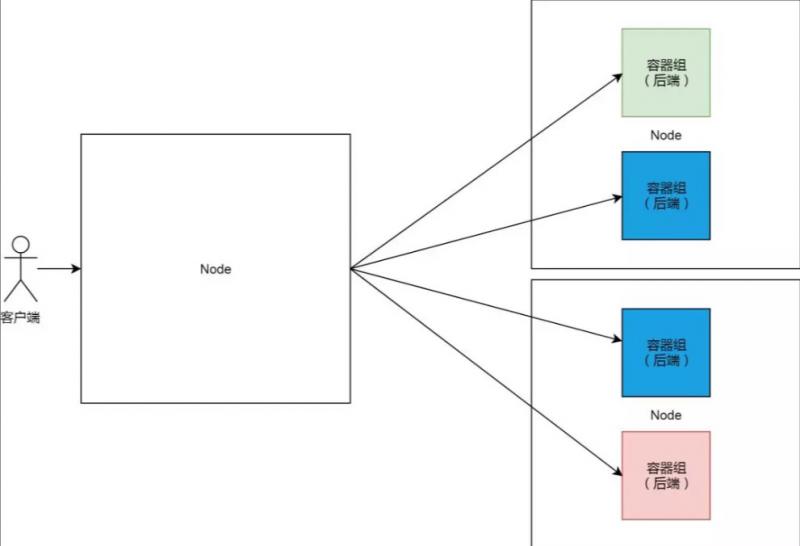
这样的实现方法,有一个巨大的缺陷,就是单点问题。Kubernetes 集群是 Google 多年来自动化运维实践的结晶,这样的实现显然与其智能运维的哲学相背离的。
自带通信员
边车模式(Sidecar)是微服务领域的核心概念。边车模式,换一句通俗一点的说法,就是自带通信员。熟悉服务网格的同学肯定对这个很熟悉了。但是可能比较少人注意到,其实 Kubernetes 集群原始服务的实现,也是基于 Sidecar 模式的。
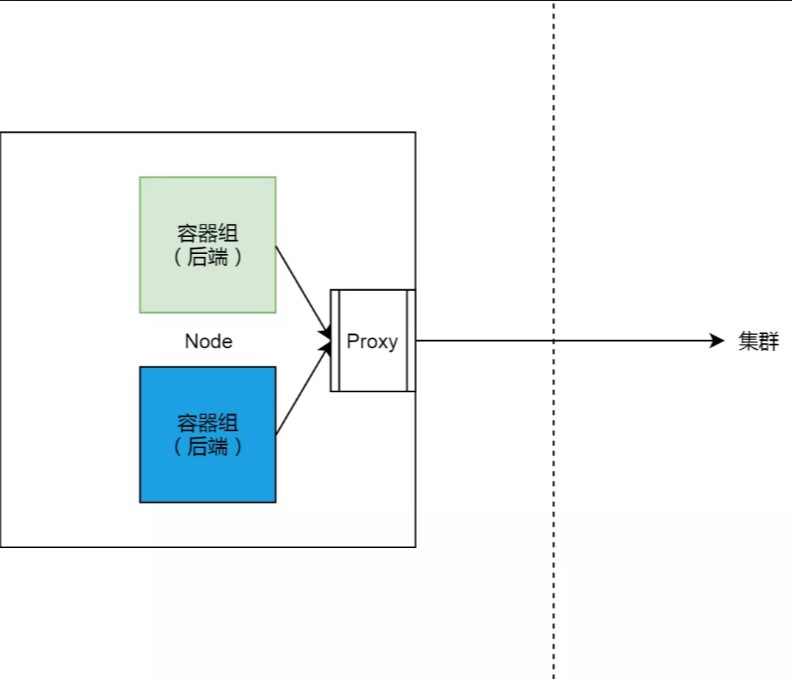
在 Kubernetes 集群中,服务的实现,实际上是为每一个集群节点上,部署了一个反向代理 Sidecar。而所有对集群服务的访问,都会被节点上的反向代理转换成对服务后端容器组的访问。基本上来说,节点和这些 Sidecar 的关系如下图所示。
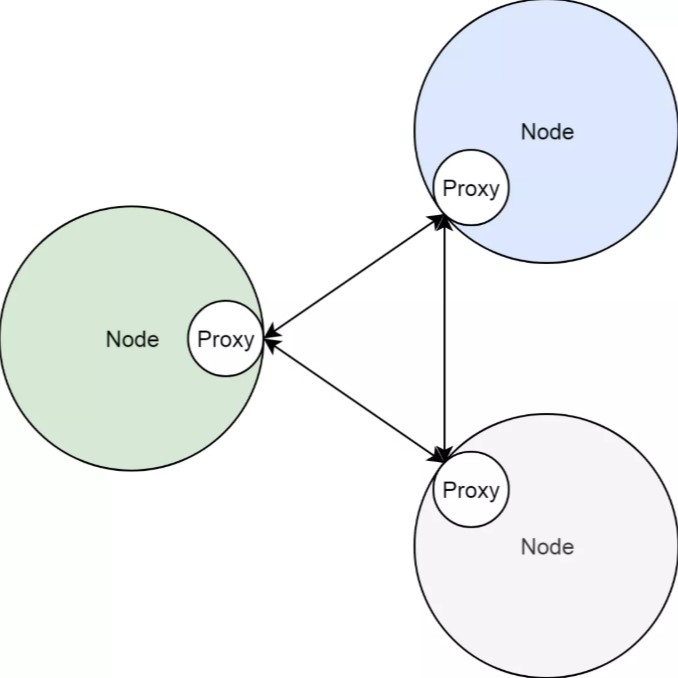
把服务照进现实
前边两节,我们看到了,Kubernetes 集群的服务,本质上是负载均衡,即反向代理;同时我们知道了,在实际实现中,这个反向代理,并不是部署在集群某一个节点上,而是作为集群节点的边车,部署在每个节点上的。
在这里把服务照进反向代理这个现实的,是 Kubernetes 集群的一个控制器,即 kube-proxy。关于 Kubernetes 集群控制器的原理,请参考我另外一篇关于控制器的文章。简单来说,kube-proxy 作为部署在集群节点上的控制器,它们通过集群 API Server 监听着集群状态变化。当有新的服务被创建的时候,kube-proxy 则会把集群服务的状态、属性,翻译成反向代理的配置。
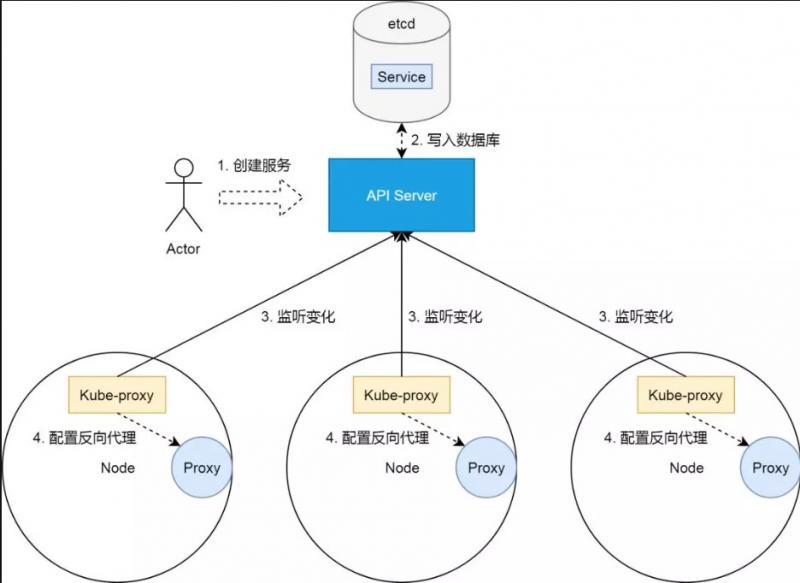
那剩下的问题,就是反向代理,即上图中 Proxy 的实现。
一种实现
Kubernetes 集群节点实现服务反向代理的方法,目前主要有三种,即 userspace、iptables 以及 IPVS。今天我们只深入分析 iptables 的方式,底层网络基于阿里云 Flannel 集群网络。
过滤器框架
现在,我们来设想一种场景。我们有一个屋子。这个屋子有一个入水管和出水管。从入水管进入的水,是不能直接饮用的,因为有杂质。而我们期望,从出水管流出的水,可以直接饮用。为了达到目的,我们切开水管,在中间加一个杂质过滤器。

过了几天,我们的需求变了,我们不止要求从屋子里流出来的水可以直接饮用,我们还希望水是热水。所以我们不得不再在水管上增加一个切口,然后增加一个加热器。
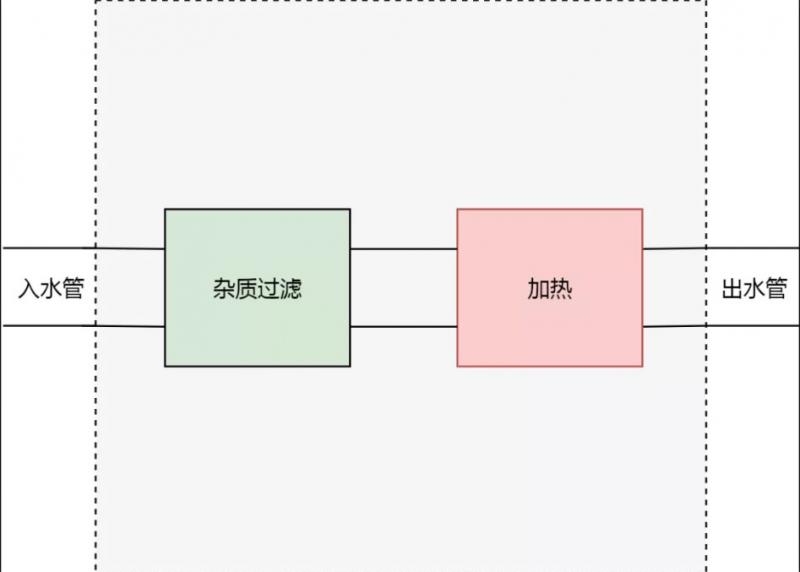
很明显,这种切开水管,增加新功能的方式是很丑陋的。因为需求可能随时会变,我们甚至很难保证,在经过一年半载之后,这跟水管还能找得到可以被切开的地方。
所以我们需要重新设计。首先我们不能随便切开水管,所以我们要把水管的切口固定下来。以上边的场景为例,我们确保水管只能有一个切口位置。其次,我们抽象出对水的两种处理方式:物理变化和化学变化。
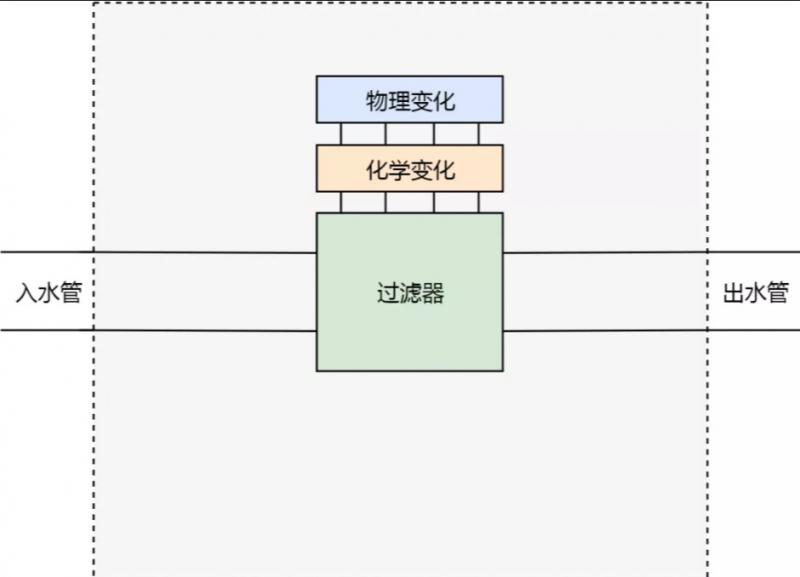
基于以上的设计,如果我们需要过滤杂质,就可以在化学变化这个功能模块里增加一条过滤杂质的规则;如果我们需要增加温度的话,就可以在物理变化这个功能模块里增加一条加热的规则。
以上的过滤器框架,显然比切水管的方式,要优秀很多。设计这个框架,我们主要做了两件事情,一个是固定水管切口位置,另外一个是抽象出两种水处理方式。
理解这两件事情之后,我们可以来看下 iptables,或者更准确的说法,netfilter 的工作原理。netfilter 实际上就是一个过滤器框架。netfilter 在网络包收发及路由的管道上,一共切了 5 个口,分别是 PREROUTING,FORWARD,POSTROUTING,INPUT 以及 OUTPUT;同时 netfilter 定义了包括 nat、filter 在内的若干个网络包处理方式。
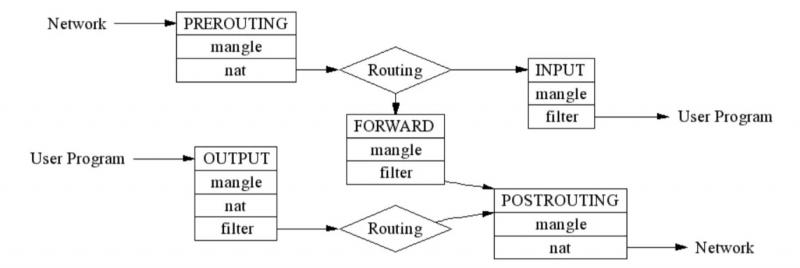
需要注意的是,routing 和 forwarding 很大程度上增加了以上 netfilter 的复杂程度,如果我们不考虑 routing 和 forwarding,那么 netfilter 会变得跟我们的水质过滤器框架一样简单。
节点网络大图
现在我们看一下 Kubernetes 集群节点的网络全貌。横向来看,节点上的网络环境,被分割成不同的网络命名空间,包括主机网络命名空间和 Pod 网络命名空间;纵向来看,每个网络命名空间包括完整的网络栈,从应用到协议栈,再到网络设备。
在网络设备这一层,我们通过 cni0 虚拟网桥,组建出系统内部的一个虚拟局域网。Pod 网络通过 veth 对连接到这个虚拟局域网内。cni0 虚拟局域网通过主机路由以及网口 eth0 与外部通信。
在网络协议栈这一层,我们可以通过编程 netfilter 过滤器框架,来实现集群节点的反向代理。
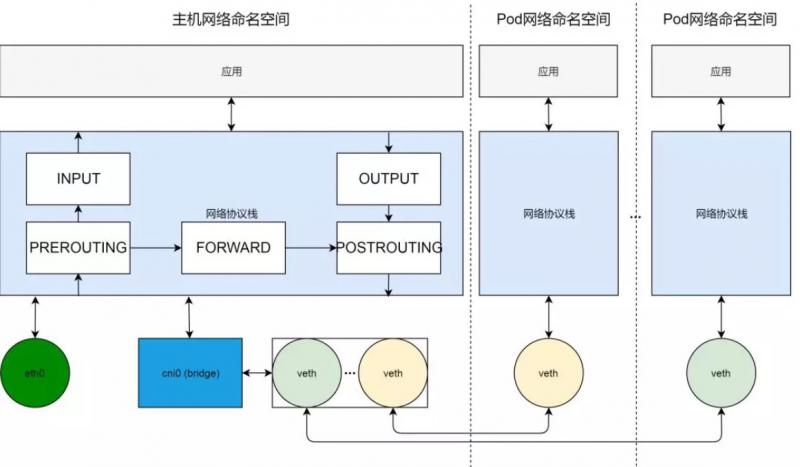
实现反向代理,归根结底,就是做 DNAT,即把发送给集群服务 IP 和端口的数据包,修改成发给具体容器组的 IP 和端口。
参考 netfilter 过滤器框架的图,我们知道,在 netfilter 里,可以通过在 PREROUTING,OUTPUT 以及 POSTROUGING 三个位置加入 NAT 规则,来改变数据包的源地址或目的地址。
因为这里需要做的是 DNAT,即改变目的地址,这样的修改,必须在路由(ROUTING)之前发生以保证数据包可以被路由正确处理,所以实现反向代理的规则,需要被加到 PREROUTING 和 OUTPUT 两个位置。
其中,PREOURTING 的规则,用来处理从 Pod 访问服务的流量。数据包从 Pod 网络 veth 发送到 cni0 之后,进入主机协议栈,首先会经过 netfilter PREROUTING 来做处理,所以发给服务的数据包,会在这个位置做 DNAT。经过 DNAT 处理之后,数据包的目的地址变成另外一个 Pod 的地址,从而经过主机路由,转发到 eth0,发送给正确的集群节点。
而添加在 OUTPUT 这个位置的 DNAT 规则,则用来处理从主机网络发给服务的数据包,原理也是类似,即经过路由之前,修改目的地址,以方便路由转发。
升级过滤器框架
在过滤器框架一节,我们看到 netfilter 是一个过滤器框架。netfilter 在数据“管到”上切了 5 个口,分别在这 5 个口上,做一些数据包处理工作。虽然固定切口位置以及网络包处理方式分类已经极大的优化了过滤器框架,但是有一个关键的问题,就是我们还是得在管道上做修改以满足新的功能。换句话说,这个框架没有做到管道和过滤功能两者的彻底解耦。
为了实现管道和过滤功能两者的解耦,netfilter 用了表这个概念。表就是 netfilter 的过滤中心,其核心功能是过滤方式的分类(表),以及每种过滤方式中,过滤规则的组织(链)。
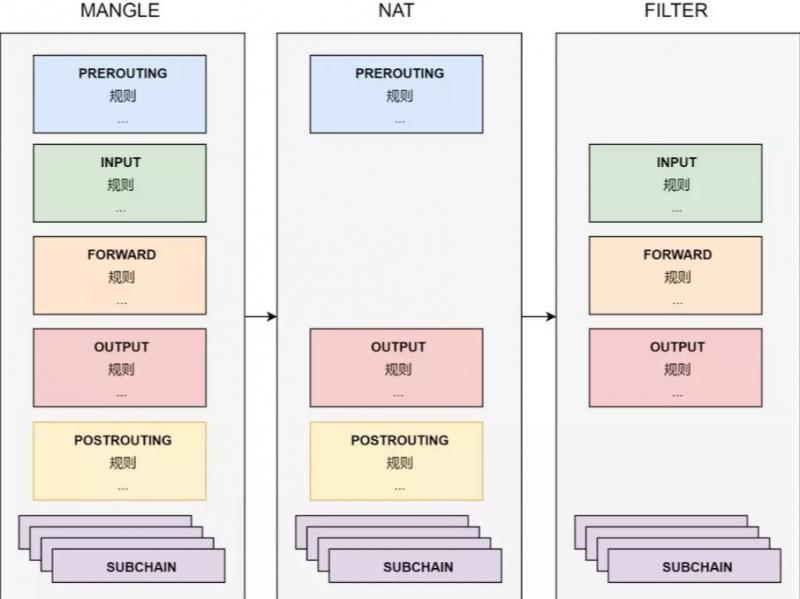
把过滤功能和管道解耦之后,所有对数据包的处理,都变成了对表的配置。而管道上的5个切口,仅仅变成了流量的出入口,负责把流量发送到过滤中心,并把处理之后的流量沿着管道继续传送下去。
如上图,在表中,netfilter 把规则组织成为链。表中有针对每个管道切口的默认链,也有我们自己加入的自定义链。默认链是数据的入口,默认链可以通过跳转到自定义链来完成一些复杂的功能。这里允许增加自定义链的好处是显然的。为了完成一个复杂过滤功能,比如实现 Kubernetes 集群节点的反向代理,我们可以使用自定义链来模块化我们规则。
用自定义链实现服务的反向代理
集群服务的反向代理,实际上就是利用自定义链,模块化地实现了数据包的 DNAT 转换。KUBE-SERVICE 是整个反向代理的入口链,其对应所有服务的总入口;KUBE-SVC-XXXX 链是具体某一个服务的入口链,KUBE-SERVICE 链会根据服务 IP,跳转到具体服务的 KUBE-SVC-XXXX 链;而 KUBE-SEP-XXXX 链代表着某一个具体 Pod 的地址和端口,即 endpoint,具体服务链 KUBE-SVC-XXXX 会以一定算法(一般是随机),跳转到 endpoint 链。

而如前文中提到的,因为这里需要做的是 DNAT,即改变目的地址,这样的修改,必须在路由之前发生以保证数据包可以被路由正确处理。所以 KUBE-SERVICE 会被 PREROUTING 和 OUTPUT 两个默认链所调用。
总结
通过这篇文章,大家应该对 Kubernetes 集群服务的概念以及实现,有了更深层次的认识。我们基本上需要把握三个要点:
- 服务本质上是负载均衡;
- 服务负载均衡的实现采用了与服务网格类似的 Sidecar 的模式,而不是 LVS 类型的独占模式;
- kube-proxy 本质上是一个集群控制器。除此之外,我们思考了过滤器框架的设计,并在此基础上,理解使用 iptables 实现的服务负载均衡的原理。
原文链接:https://yq.aliyun.com/articles/710873
“ 阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”











