
摘要: 阿里云Elasticsearch提供100%兼容开源Elasticsearch的功能,以及Security、Machine Learning、Graph、APM等商业功能,致力于数据分析、数据搜索等场景服务。与开源社区背后商业公司Elastic战略合作,为客户提供企业级权限管控、安全监控告警、自动报表生成等场景服务。本文中,阿里云产品专家沐泽为大家介绍了阿里云Elasticsearch产品的相关情况。
产品介绍
Elasticsearch(简称ES)是2010年推出的一款开源产品,本质上是一个实时的分布式实时搜索与分析引擎。随着这些年来Elasticsearch生态的演进,逐渐发展成为ELK即Elasticsearch、Logstash、Kibana的生态。Elasticsearch属于搜索引擎,Logstash负责数据的采集、转化以及输出,Kibana则提供了强大的数据可视化功能。对于Elasticsearch而言,其在DB-Engines中的开源数据库排行榜中位列第一。可以看出,Elasticsearch受到了广泛的认可,并且也有大量的开发者正在使用。
阿里云Elasticsearch提供了全托管的Elasticsearch服务,并且100%兼容开源版本,并且对于内核进行了针对性优化,提供了商业功能(原‘X-Pack’),即开即用,高可用服务,弹性伸缩,按需付费。在下图中,在阿里云Elasticsearch的可靠性、安全性、系统托管等方面与友商的产品进行了对比。在可靠性方面,阿里云Elasticsearch具有99.9%的数据可靠性,并且会定时地向OSS进行数据备份,方便用户在数据出现问题的时候进行恢复。此外,通过同城多活,提供了较强的容灾能力。在开源差异部分,阿里云Elasticsearch也做了大量的工作。在内核性能优化部分,不仅做了存储与计算分离,还提供了ECS本身的调优。在Index Build服务部分,Elasticsearch本身支持高并发的数据写入加速,这样会使得数据的写入和查询相互影响,阿里云Elasticsearch则通过Index Build服务离线地构建索引,并将原生索引切换成比较小的片并与线上索引进行Merge,这样就避免了用户线上集群的I/O开销,在一定场景下保障了高并发写入场景下的查询服务的稳定性。在智能运维方面,阿里云Elasticsearch提供了EU智能运维系统,能够帮助用户运维和监控集群并且进行智能分析,方便用户更好地了解集群的健康状况,并且还提供了预警以及改进建议等功能。此外,阿里云Elasticsearch近期还集成了阿里达摩院的NLP分词器和分析器,能够更好地完成业务的分析和检索任务。在商业插件部分,X-Pack服务本身集成在Elasticsearch和Kibana里面的。以往这样的商业版插件包对于用户而言,需要付费使用,阿里云Elasticsearch通过这样的方式为用户提供了很多功能,如认证授权、权限管理、报表可视化以及机器学习等。总体来看,相比友商的ES方案以及用户自建ES,阿里云Elasticsearch的价格也具有较强的优势,并且具有更加丰富的产品能力,同时也具有比较高的性价比。
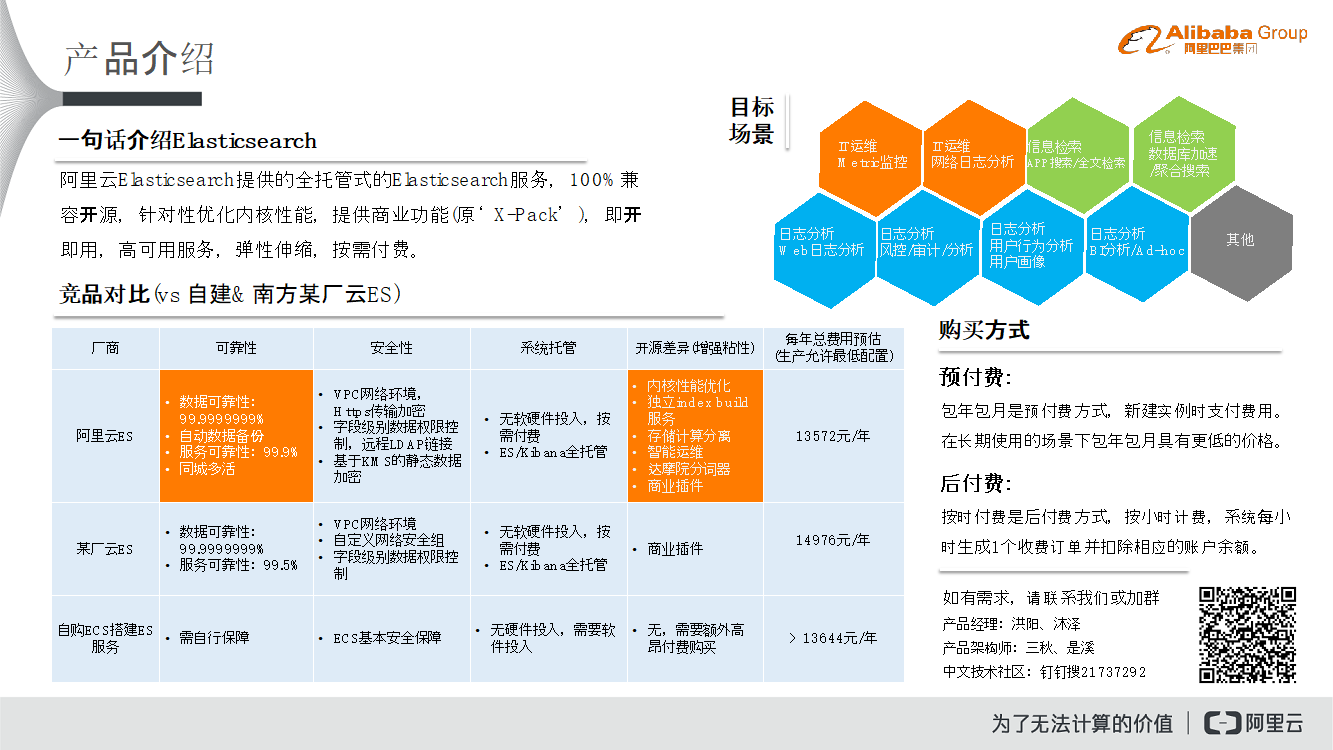
基于以上的目标能力,阿里云Elasticsearch也具有非常丰富的目标场景,主要集中在IT运维、信息检索以及日志分析等方面。在IT运维方面,用户可以做Metric监控、网络日志分析等相关工作。信息检索方面,不仅支持APP检索,也可以用于数据库加速以及聚合搜索等场景。在日志分析方面,可以用于Web日志分析、风控/审计/分析、用户行为分析/用户画像以及BI分析和Ad-hoc等场景下。最后,阿里云Elasticsearch的主要购买方式就是包年包月预付费和按量后付费两种。
产品输出形式
对于阿里云Elasticsearch产品的输出形式而言,主要在公共云和专有云这两个方面。在公共云上,阿里云Elasticsearch支持了金融云、零售云以及菜鸟云,并且在日本站和国际站进行了售卖。在专有云方面,8月底的时候阿里云Elasticsearch也提供了轻量PaaS独立输出,并且可以在企业版On ECS和企业版On物理机上进行部署。
产品架构
在产品架构部分,阿里云Elasticsearch部署在ECS网段,相当于购买了大量的ECS服务器拉起了ES镜像。对用户而言,可以购买很多的ES集群,每个ES集群中都会有很多的Node,每个Node就是一台ECS。整个ECS部署在系统方VPC内,并且支持跨可用区的同城容灾能力,也就是说在同一个区域下面,可以在不同的可用区内部署服务,通过阿里云VPC和用户VPC之间的IP映射使得每个集群的Node分布在不同的可用区之内。
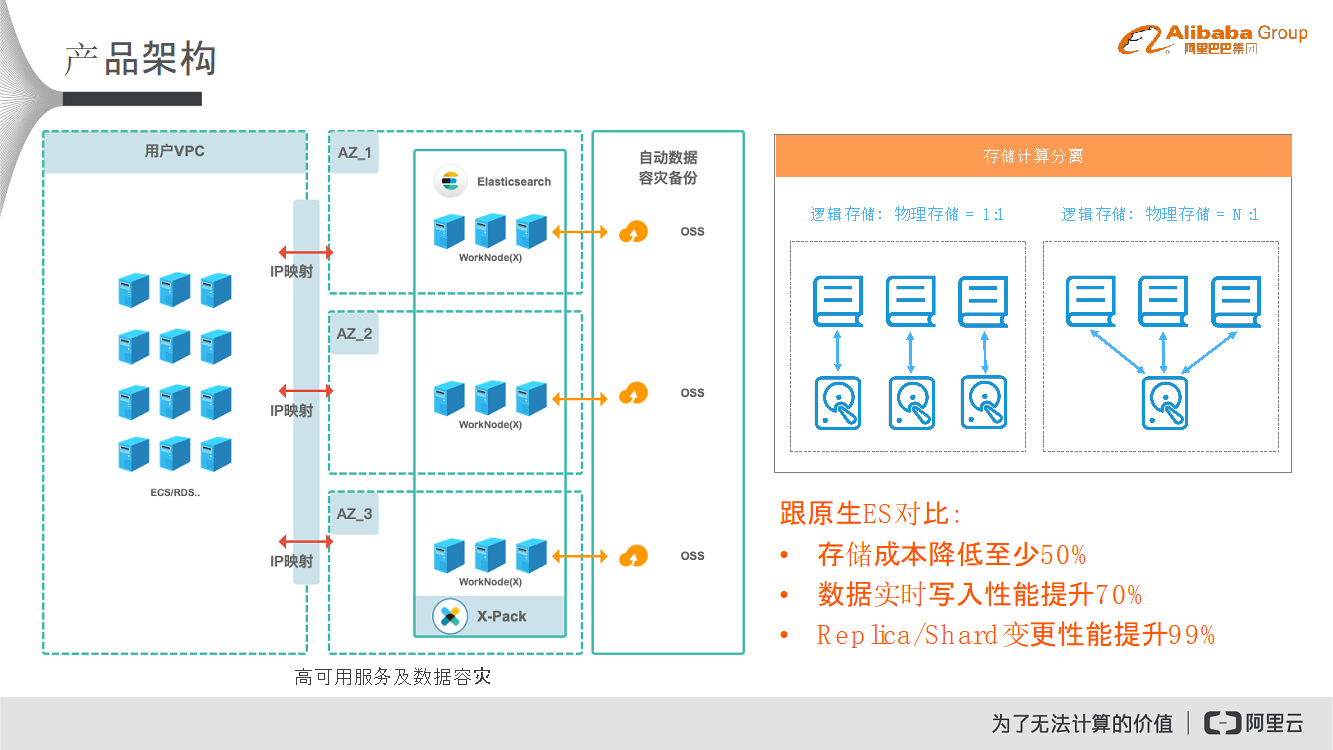
除此之外,在保证容灾方面,用户的数据节点会定时地向OSS做快照备份,当用户的数据出现问题的时候,可以快速地通过OSS实现数据恢复。整体的数据存储类型支持高效云盘、SSD云盘以及本地磁盘。在存储计算分离方面,阿里云Elasticsearch近期也在内核方面进行了优化。本身Elasticsearch索引为了方便存储需要做分片,为了提升查询效率,每个分片会有多个副本,但是这样属于用空间换时间的方式,因此会造成大量的数据冗余,为用户带来很高的存储成本。另外一方面,为了提升查询效率,用户在写入数据的时候,就会增加更多的内存开销,进而造成写入速度较慢。在这样的背景之下,阿里云Elasticsearch做了存储与计算分离的内核优化,将用户数据的多个副本进行分片映射到同一块的物理介质之上,与原生的ES相比,阿里云Elasticsearch的存储成本降低至少50%,数据写入实时性能提升70%,Replica/Shard变更性能提升99%,以上这些能力都是开源版本的ES所不具备的。
公共云可售卖区域
目前,阿里云Elasticsearch除了美东、英国和迪拜三个区域还没有部署售卖之外,在全球范围内的其他阿里云数据中心都已经部署售卖了,未来也会在更多的区域进行开放。
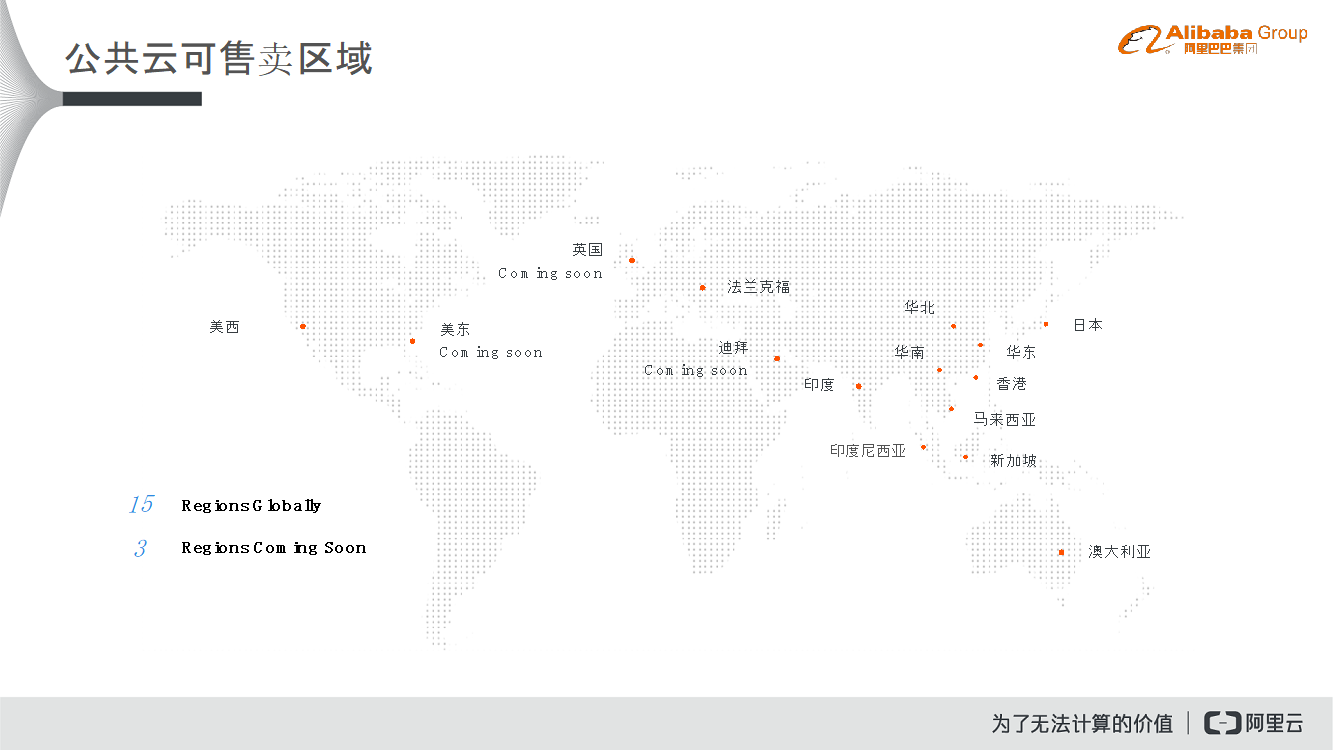
金融持久化数据审计方案
这里介绍一个实际案例,这是阿里云为一家信用卡结算公司设计的金融持久化数据库审计方案。该客户存在金融数据监管需求,因此数据需要存储的时间较长,因此造成数据量非常大。因此,阿里云提供了金融持久化数据库审计方案中为用户提供了一个三层的数据存储方案,用户近期的Hot Data会在第一层ECS存储大约2个月的时间,当变成Warm Data或者更老的数据之后,就会存储到下层的ECS或者OSS之上,这样一方面保障了用户在使用阿里云Elasticsearch时的数据查询时效性,使得其不会被大数据量所影响,另外一方面也大大降低了用户的存储成本。
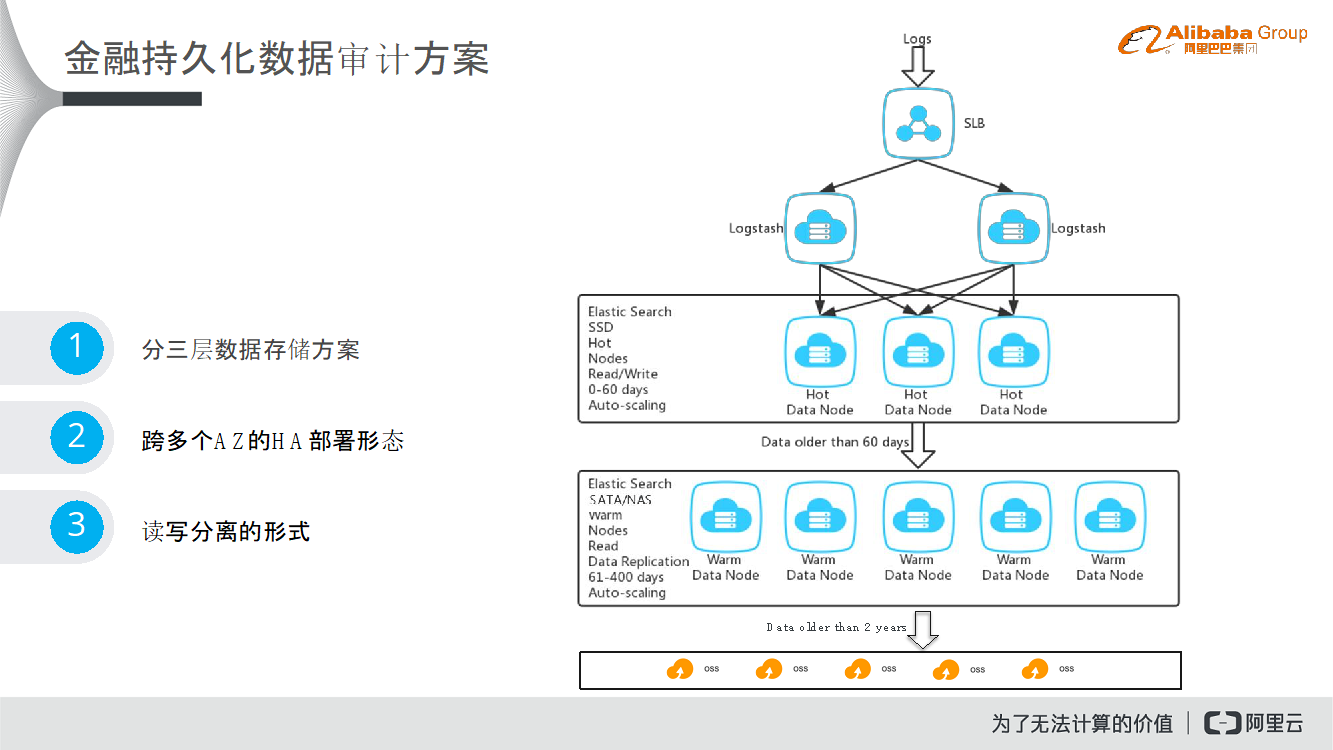
场景示例-日志分析
这里针对于日志分析场景进行更进一步的介绍。在日志分析方面,会采集用户在网站/游戏/应用内的行为日志数据,分为离线和在线两个部分分别投递给Hadoop及Elasticsearch,以满足用户(离线部分)标签、画像的加工,和(在线部分)用户行为实时统计和状态查询。阿里云Elasticsearch在日志分析场景下提供了很多对应的能力,面向日志分析场景,提供聚合搜索、实时查询、增量数据快速索引归档等分析必备能力。除此之外,阿里云Elasticsearch基于X-Pack服务提供了基于LBS的地理位置搜索、可视化分析报表、数据可视化展现等高级分析能力。进一步可以实现用户留存分析,浏览路径分析,基于地理围栏的用户画像,用户标签体系等数据查询、统计以及分析场景。
Elasticsearch如何处理日志
日志数据的来源有很多,比如日志文件、数据库、传感器以及Web API等,而利用这些日志数据实现日志搜索和日志分析会存在很多常见的需求,主要包括五点,即集中收集与存储、日志搜索、分析聚合及可视化、安全、角色管理以及可伸缩性。

在集中收集与存储日志数据方面,阿里云Elasticsearch会对于常规日志数据进行采集,包括日志文件、日志系统、网络拥堵等其他常见的日志数据。阿里云Elasticsearch通过收集和汇拢数据以及离线Hadoop数据迁移能够比较快捷地集中日志数据并存储到Elasticsearch中构建索引。
在日志搜索方面,阿里云Elasticsearch能够支持全文检索、元数据搜索、指标/标签搜索以及地理位置搜索等。
在分析聚合和可视化方面,当数据聚合到阿里云Elasticsearch里面去之后,可以通过sum、average、min/max等聚合函数实现聚合分析,并且可以通过X-Pack实现机器学习分析,也可以借助Kibana实现在线数据可视化。并且在阿里云Elasticsearch中,用户可以直接通过Kibana控制台实现配置以及可视化面板的创建。
在安全和角色管理方面,阿里云Elasticsearch提供了RBAC的用户权限以及TLS/SSL交互式安全协议,并且能够实现实时监控和触发告警,能够帮助用户进行实时预防。此外,基于X-Pack的商业功能能够提供自动数据报表以及触发式报表等服务,帮助用户更好地进行数据管理和查询。
在可伸缩性方面,阿里云Elasticsearch能够支持弹性扩容,因为ES的节点是对等的,因此能够实现快速拷贝和弹性扩容,实现不同规模下的数据管理。
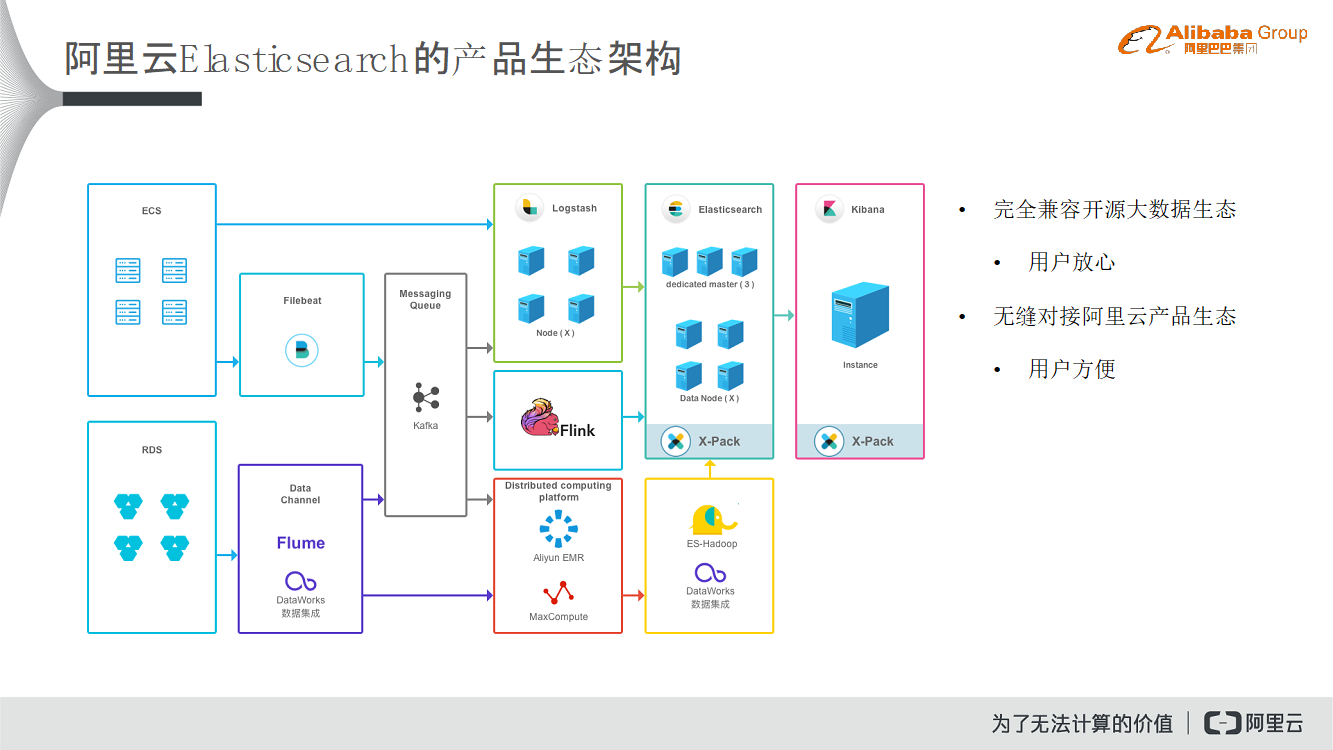
阿里巴巴Elasticsearch的产品生态架构
数据会从RDS等数据存储中过来,通过Flume、EMR、MaxCompute等下游计算引擎进行加工和处理,完成画像或者标签的工作,最后索引到Elasticsearch中去。阿里云Elasticsearch是兼容整个大数据生态的,并且也能够无缝地对接整个阿里云的产品生态,进而非常方便地完成数据的处理工作。此外,还可以通过Kibana可以帮助用户更好地实现数据的可视化管理。
本文为云栖社区原创内容,未经允许不得转载。











