
一、Spring 的 DAO 理念
DAO(Data Access Object)是用于访问数据的对象,虽然在大多数情况下将数据保存在数据库中,但这并不是唯一的选择,也可以将数据存储到文件中或 LDAP 中。DAO 不但屏蔽了数据存储的最终介质的不同,也屏蔽了具体的实现技术的不同。
早期,JDBC 是访问数据库的主流选择。近几年,数据持久化技术获得了长足的发展,Hibernate、MyBatis、JPA、JDO 成为持久层中争放异彩的实现技术。只要为数据访问定义好 DAO 接口,并使用具体的技术实现 DAO 接口的功能,就可以在不同的实现技术间平滑地切换。
下图是一个典型的 DAO 应用实例,在 UserDao 中定义访问 User 数据对象的接口方法,业务层通过 UserDao 操作数据,并使用具体的持久化技术实现 UserDao 接口方法,这样业务层和具体的持久化技术就实现了解耦。
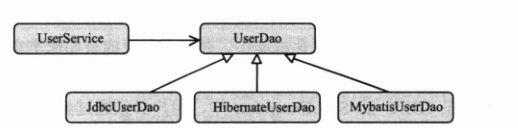
提供 DAO 层的抽象可以带来一些好处:首先,可以很容易地构造模拟对象,方便单元测试的开展;其次,在使用切面时会有更多的选择,既可以使用 JDK 动态代理,又可以使用 CGLib 动态代理。
Spring 本质上希望以统一的方式整合底层的持久化技术,即以统一的方式进行调用及事务管理,避免让具体的实现侵入到业务层的代码中。由于每种持久化技术都有各自的异常体系,所以 Spring 提供了统一的异常体系,使不同异常体系的阻抗得以消弭,方便定义出和具体实现技术无关的 DAO 接口,以及整合到相同的事务管理体系中。
二、统一的异常体系
统一的异常体系是整合不同的持久化技术的关键。Spring 提供了一套和实现技术无关的、面向 DAO 层语义的异常体系,并通过转换器将不同持久化技术的异常转换成 Spring 的异常。
1.Spring 的 DAO 异常体系
在很多正统 API 或框架中,检查型异常被过多地使用,以至在使用 API 时,代码里充斥着大量样板式的代码。在很多情况下,除在 try/catch 中记录异常信息外,并没有做多少实质性的工作。引发异常的问题往往是不可恢复的,如数据连接失败、SQL 语句存在语法错误等。强制捕捉的检查型异常除限制开发人员的自由外,并没有提供什么有价值的东西。因此,Spring 的异常体系都是建立在运行期异常的基础上的,开发者可以根据需要捕捉感兴趣的异常。
JDK 的很多 API 之所以难用,一个很大的原因就是检查型异常的泛滥,如 JavaMail、EJB、JDBC 等。使用这些 API,一堆堆异常处理的代码喧宾夺主地侵入到业务代码中,破坏了代码的整洁和优雅。
Spring 在 org.springframework.dao 包中提供了一套完备优雅的 DAO 异常体系,这些异常都继承于 DataAccessException,而 DataAccessException 本身又继承于 NestedRuntimeException,NestedRuntimeException 异常以嵌套的方式封装了源异常。因此,虽然不同持久化技术的特定异常被转换到 Spring 的 DAO 异常体系中,但原始的异常信息并不会丢失;只要用户愿意,就可以方便地通过 getCause() 方法获取原始的异常信息。
Spring 的 DAO 异常体系并不和具体的实现技术相关,它从 DAO 概念的抽象层面定义了异常的目录树。在所有的持久化框架中,并没有发现拥有如此丰富语义的异常体系的框架。Spring 的这种设计无疑是独具匠心的,它使得开发人员关注某一特定语义的异常变得很容易。在 JDBC 的 SQLException 中,用户必须通过异常的 getErrorCode() 或 getSQLState() 方法获取错误代码,然后根据这些代码判断错误原因。这种过于底层的 API 不但带来了代码编程上的难度,而且也使代码的移植变得困难,因为 getErrorCode() 方法是数据库相关的。
Spring 以分类手法建立了异常分类目录,对于大部分应用来说,这个异常分类目录对异常类型的划分具有适当的颗粒度。一方面,使开发者从底层细如针麻的技术细节中脱离出来;另一方面,可以从这个语义丰富的异常体系中选择感兴趣的异常加以处理。
下图列出了那些位于 Spring DAO 异常体系第一层次的异常类,每个异常类下可能拥有众多的子异常类。
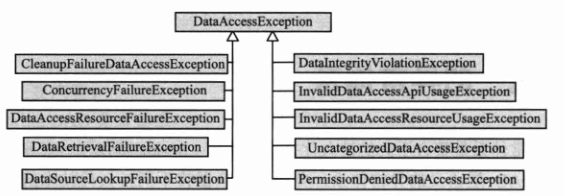
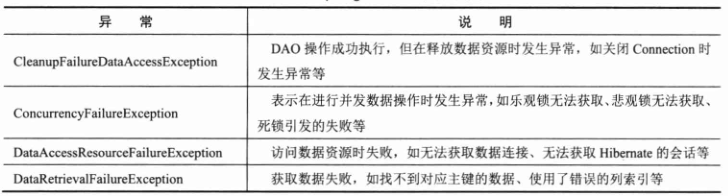
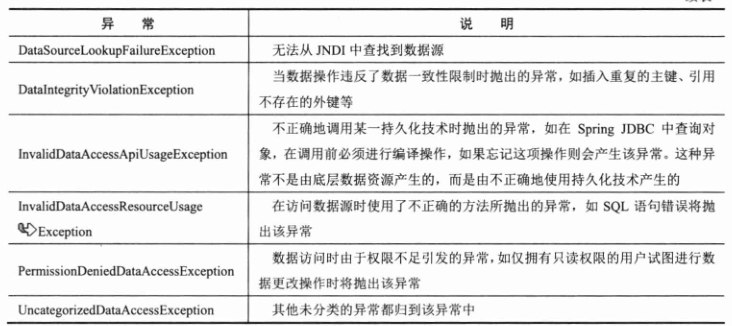
Spring DAO异常体系类非常丰富,这里仅列出 DataAccessException 异常类下的子类。可以很容易地通过异常类的名字了解异常所代表的语义。下面通过下表对这些异常进行简单的描述。
为了进一步细化错误的问题域,Spring 对一级异常类进行了子类的细分,如 InvalidDataAccessResourceUsageException 就拥有十多个子类,下面是其中的两个子类,如下图所示。
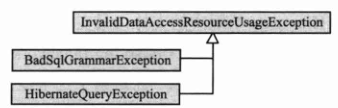
对于 InvalidDataAccessResourceUsageException 异常,不同的持久化技术均有对应的子异常类。如 BadSqlGrammarException 对应 JDBC 实现技术的 SQL 语句语法错误异常,而 HibernateQueryException 对应 Hibemate 实现技术的查询语法异常。
Spring 的这个异常体系具有高度的可扩展性,当 Spring 需要对一种新的持久化技术提供支持时,只要为其定义一个对应的子异常就可以了,这种更改完全满足设计模式中的“开一闭原则”。
虽然 Spring 定义了如此丰富的异常类,但作为开发人员,仅需对感兴趣的异常进行处理即可。假设某个项目要求在发生乐观锁异常时,尝试再次获取乐观锁,而不是直接返回错误;那么,只需在代码中显式捕捉 ConcunencyFailureException 异常,然后在 catch 代码块中编写满足需求的逻辑即可。其他众多的异常则可以简单地交由框架自动处理,如发生运行期异常时自动回滚事务。
2.JDBC的异常转换器
传统的 JDBC API 在发生几乎所有的数据操作问题时都会抛出相同的 SQLException,它将异常的细节性信息封装在异常属性中。所以,如果希望了解异常的具体原因,则必须分析异常对象的信息。
SQLException 拥有两个代表异常具体原因的属性:错误码和 SQL 状态码。前者是数据库相关的,可通过 getErrorCode() 方法返回,其值的类型是 int;而后者是一个标准的错误代码,可通过 getSQLState() 方法返回,是一个 String 类型的值,由 5 个字符组成。
Spring 根据错误码和 SQL 状态码信息将 SQLException 译成 Spring DAO 的异常体系所对应的异常。在 org.springframework.jdbc.support 包中定义了 SQLExceptionTranslator 接口,该接口的两个实现类 SQLErrorCodeSQLExceptionTranslator 和 SQLStateSQLExceptionTranslator 分别负责处理 SQLException 中错误码和 SQL 状态码的翻译工作。将 SQLException 翻译成 SpringDAO 异常体系的工作是比较困难的,但 Spring 框架替我们完成了这项艰巨的工作并保证了转换的正确性,我们有充分的理由依赖这个转换的正确性。
3.其他持久化技术的异常转换器
由于各种框架级的持久化技术都拥有一个语义明确的异常体系,所以将这些异常转换为 Spring DAO 的体系相对轻松一些。下面将学习不同持久化技术的异常转换器。
Spring4.0 移除了对 Hibernate 低版本的支持,只支持 Hibernate3.6 之后的版本。另外,Spring4.0 移除了对 TopLink 的支持。在 org.springframework.orm 包中,分别为 Spring 所支持的 ORM 持久化技术定义了一个子包,在这些子包中提供相应 ORM 技术的整合类。Spring 为 各种 ORM 持久化技术所提供的异常转换器在下表说明。

这些工具类除了具有异常转换的功能,在进行事务管理时,还提供了从事务上下文中返回相同会话的功能。
Spring 也支持 MyBatis ORM 持久化技术,由于 MyBatis 抛出的异常是和 JDBC 相同的 SQLException 异常,所以直接采用和 JDBC 相同的异常转换器。
三、统一数据访问模板
到一个餐馆用餐,大抵会经历这样一个流程:进入餐馆-->迎宾小姐问候并引到适合的位置-->拿起菜单点菜-->用餐-->埋单-->离开餐馆。之所以我们喜欢时不时到餐馆用餐,就是因为我们只要点菜-->用餐-->埋单就可以了,幕后的烹饪制作、刷锅洗盘等工作完全不用关心,一切已经由餐馆服务人员按照服务流程按部就班、有条不紊地执行了。衡量一个餐馆服务质量好坏的一个重要标准是我们无须关心他们所负责的流程:不用催问菜为什么还没有上好(不但快而且服务态度佳),不用关心盘子为什么不干净(不但干净而且已经进行了消毒)。
从某种角度看,与其说餐馆为我们提供了服务,还不如说我们参与到餐馆的流程中:不管什么顾客点的菜都由相同的厨师烹制,不管什么顾客都按单付钱。在幕后,餐馆拥有一个服务模板,模板中定义的流程可以用于应付所有的顾客,只要为顾客提供几个专有需求(点的菜可不一样,座位可以自由选择),其他一切都按模板化的方式处理。
在直接使用具体的持久化技术时,大多需要处理整个流程,并没有享受餐馆用餐式的便捷。Spring 为支持的持久化技术分别提供了模板访问的方式,降低了使用各种持久化技术的难度,因此可以大幅度地提高开发效率。
1.使用模板和回调机制
下面是一段使用 JDBC 进行数据访问操作的简单代码,我们已经尽可能地简化了整个过程的处理,但以下步骤都是不可或缺的,如下面代码所示。
public void saveCustomer(Customer customer)throws Exception{
Connection con = null;
PreparedStatement stmt = null;
try{
//①获取资源
con = getConnection();
//②启动事务
con.setAutoCommit(false);
//③具体的数据访问操作和处理
stmt = con.prepareStatment("insert into CUSTMOERS(ID,NAME) values(?,?)");
stmt.setLong(1,customerId);
stmt.setString(2,customer.getName());
stmt.execute();
...
stmt.execute();
//④提交事务
con.commit();
}catch(Exception e){
try{
//⑤回滚事务
con.rollback();
}catch(SQLException sqlex){
sqlex.printStackTrace(System.out);
}
throw e;
}finally{
//⑥释放资源
try{
stmt.close();
con.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
如上述代码所示,JDBC 数据访问操作按以下流程进行:
(1)准备资源。
(2)启动事务。
(3)在事务中执行具体的数据访问操作。
(4)提交/回滚事务。
(5)关闭资源,处理异常。
按照传统的方式,在编写任何带事务的数据访问程序时,都需要重复编写上面的代码,而其中只有粗体部分所示的代码是业务相关的,其他代码都是在例行公事,因而导致大量八股文式的代码充斥着整个程序。
Spring 将这个相同的数据访问流程固化到模板类中,并将数据访问中固定和变化的部分分开,同时保证模板类是线程安全的,以便多个数据访问线程共享同一个模板实例。固定的部分在模板类中已经准备好,而变化的部分通过回调接口开放出来,用于定义具体数据访问和结果返回的操作。下图描述了模板类拆分固定和变化部分的逻辑。
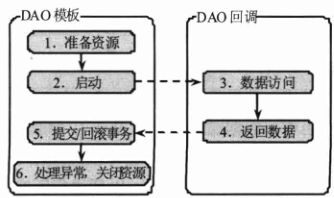
这样,只要编写好回调接口,并调用模板类进行数据访问,就可以得到预想的结果:数据访问成功执行,前置和后置的样板化工作也按顺序正确执行,在提高开发效率的同时保证了资源使用的正确性,彻底消除了因忘记进行资源释放而引起的资源泄露问题。
2.Spring 为不同持久化技术所提供的模板类
Spring 为各种支持的持久化技术都提供了简化操作的模板和回调,在回调中编写具体的数据操作逻辑,使用模板执行数据操作,在 Spring 中,这是典型的数据操作模式。下面来了解一下 Spring 为不同的持久化技术所提供的模板类,如下表所示。

如果直接使用模板类,则一般需要在 DAO 中定义一个模板对象并提供数据资源。
Spring 为每种持久化技术都提供了支持类,支持类中已经完成了这样的功能。这样,只需扩展这些支持类,就可以直接编写实际的数据访问逻辑,因此更加方便。
不同持久化技术的支持类如下表所示。
这些支持类都继承于 dao.support.DaoSupport 类,DaoSupport 类实现了 ImtializingBean接口,在 afterPropertiesSet() 接口方法中检查模板对象和数据源是否被正确设置,否则将抛出异常。
所有的支持类都是 abstract 的,其目的是希望被继承使用,而非直接使用。












