
读写锁
同一用户并发读取同一条数据,不会出现什么问题,因为读取不会修改数据,但是如果某个用户正在读取某张表,而同一时刻另一用户正在修改这张表的id为1的数据,会产生什么后果?
答案是不确定的,读的用户可能会报错退出,也可能读到不一致的数据。
解决这类经典问题的就是并发控制。在处理并发读写的时候,可以通过实现一个由两种类型的锁组成锁系统来解决问题。这两种锁就是读锁(共享锁)和写锁(排他锁)。
读锁(共享锁)是读取操作创建的锁。其他用户可以并发读取数据,但任何事务都不能对数据进行修改(获取数据上的排他锁),直到已释放所有共享锁。
如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获准共享锁的事务只能读数据,不能修改数据。
写锁(排他锁)如果事务T对数据A加上排他锁后,则其他事务不能再对A加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据。
事务可以通过以下语句给sql加共享锁和排他锁:
共享锁:select …… lock in share mode;
排他锁:select …… for update;
共享锁:

排它锁:
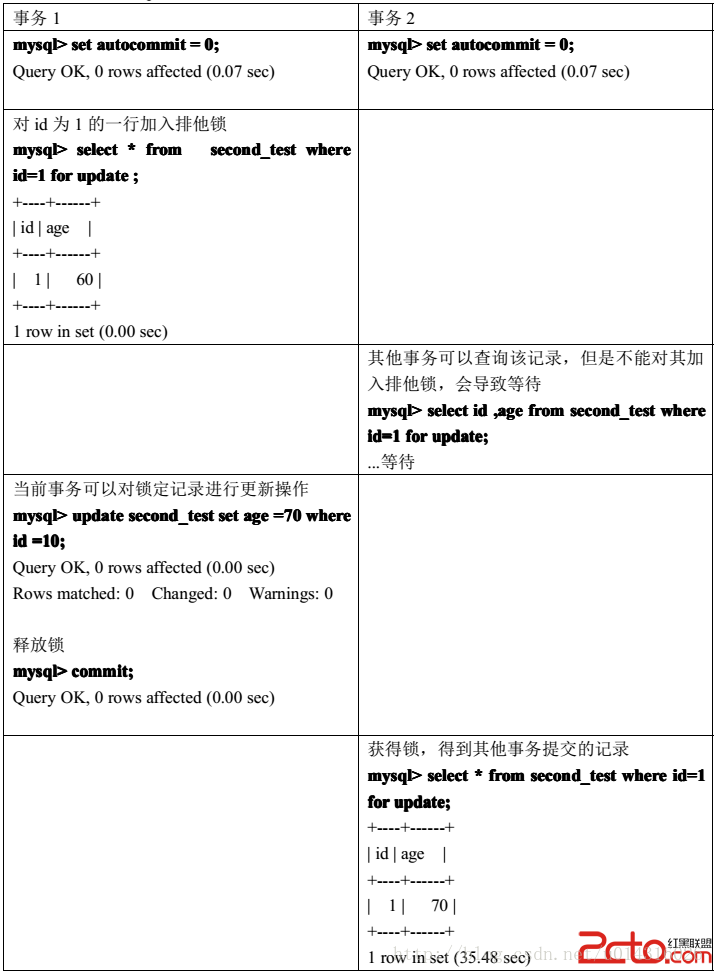
读锁和写锁都是行级锁,InnoDB的行锁是通过给索引上的索引项加锁来实现的,如果没有索引,InnoDB将通过隐藏的聚簇索引来对记录加锁,InnoDB行锁分为3中情形:
1. Record Lock:对索引项加锁。
2. Gap Lock:对索引项之间的“间隙”、第一条记录前的“间隙”或最后一条记录后的“间隙”加锁。
3. Next-key Lock:前两种的结合,对记录及其前面的间隙加锁。
InnoDB这种行锁的实现特点意味着,如果不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,实际效果跟锁表一样。
事务
– ACID –
原子性(Atomicity):整个事务操作要么全部成功,要么全部失败。
一致性(Consistency):
隔离性(Isolation):一个事务所做的修改在提交之前,对其他事务是不可见的。也就是说事务互不影响。
持久性(Durability):一旦事务提交,则其所做的修改就会永久保存到数据库中。
隔离级别:
read uncommit(读未提交):在此隔离级别下,事务中的修改,及时没有提交,对其他事务也都是可见的。会出现脏读。
read commit(读已提交):事务中的修改,在提交之前,对其他事务是不可见的。会出现不可重复读。
repeatable read(可重复读):mysql默认的隔离级别。同一个事务中 ,多次执行相同的select,结果是一致的。会出现幻读。需要注意的是InnoDB和XtraDb存储引擎通过MVCC(多版本控制)解决了幻读的问题,准确来说是通过间隙锁解决了幻读的问题。
serializable(可串行化):会在读取的每一行上都加锁,解决了幻读,但不建议使用。
脏读:事务可以读取未提交的数据。
不可重复读:同一个事务,多次执行相同的select,结果不一样。
幻读:事务A读取某个范围的记录时,事物B在该范围插入了新事物,事物A再次读取该范围内的记录时,会产生幻行。












