
以下内容大部分摘自许世伟的《GO语言核心编程》
最近面试,在自己的简历上写了简单会一些GO语言。结果被面试官问了GO语言goroutine的原理。自己看倒是看过,时间长了又给忘了。特此写下此文以长记性。
协程:协程本质上是一种用户态线程,不需要操作系统来进行抢占式调度,并且在真正的实现中寄存于线程中,因此系统开销极小,可以有效的提高线程任务的并发性,而避免多线程的缺点。使用协程的优点是编程简单,结构清晰;缺点是需要语言的支持,如果不支持,则需要用户在程序中自行实现调度器。目前,原生支持协程的语言还很少
执行体是个抽象的概念,在操作系统层面有多个概念与之对应,比如操作系统自己掌管的进程(process)、进程内的线程(thread)以及进程内的协程(coroutine,也叫轻量级线程)。与传统的系统级线程和进程相比,协程的最大优势在于其“轻量级”,可以轻松创建上百万个而不会导致系统资源衰竭,而线程和进程通常最多也不能超过1万个。这也是协程也叫轻量级线程的原因。
多数语言在语法层面并不直接支持协程,而是通过库的方式支持,但用库的方式支持的功能也并不完整,比如仅仅提供轻量级线程的创建、销毁与切换等能力。如果在这样的轻量级线程中调用一个同步 IO 操作,比如网络通信、本地文件读写,都会阻塞其他的并发执行轻量级线程,从而无法真正达到轻量级线程本身期望达到的目标。
Go 语言在语言级别支持轻量级线程,叫goroutine。Go 语言标准库提供的所有系统调用操作(当然也包括所有同步 IO 操作),都会出让 CPU 给其他goroutine。这让事情变得非常简单,让轻量级线程的切换管理不依赖于系统的线程和进程,也不依赖于CPU的核心数量。
goroutine是Go语言中的轻量级线程实现,由Go运行时(runtime)管理。你将会发现,它的使用出人意料得简单。“go”这个单词是关键。与普通的函数调用相比,这也是唯一的区别。的确, go 是Go语言中最重要的关键字,这一点从Go语言本身的命名即可看出。
在一个函数调用前加上 go 关键字,这次调用就会在一个新的goroutine中并发执行。当被调用的函数返回时,这个goroutine也自动结束了。需要注意的是,如果这个函数有返回值,那么这个返回值会被丢弃。
Go程序从初始化 main package 并执行 main() 函数开始,当 main() 函数返回时,程序退出,且程序****默认****并不等待其他goroutine(非主goroutine)结束****。
并发编程的难度在于协调,而协调就要通过交流。从这个角度看来,并发单元间的通信是最大的问题。
在工程上,有两种最常见的并发通信模型:共享数据和消息。
共享数据是指多个并发单元分别保持对同一个数据的引用,实现对该数据的共享。被共享的数据可能有多种形式,比如内存数据块、磁盘文件、网络数据等。在实际工程应用中最常见的无疑是内存了,也就是常说的共享内存
Go语言提供的是另一种通信模型,即以消息机制而非共享内存作为通信方式。消息机制认为每个并发单元是自包含的、独立的个体,并且都有自己的变量,但在不同并发单元间这些变量不共享。每个并发单元的输入和输出只有一种,那就是消息。这有点类似于进程的概念,每个进程不会被其他进程打扰,它只做好自己的工作就可以了。不同进程间靠消息来通信,它们不会共享内存。
Go语言提供的消息通信机制被称为channel,GO语言提倡:“不要通过共享内存来通信,而应该通过通信来共享内存。”
下面的内容来自《GO语言并发实战 第二版》,该书对GO语言的原理介绍比较详细,这绝不是打广告(我跟作者没有任何利益勾结,我倒想有勾结,大佬带带我),我看过李文塔的《Golang核心编程》以及许世伟的《GO语言编程》和GO语言圣经,相比之下,还是《GO语言并发编程实战》一书对goroutine的原理介绍最为详细。
**GO语言协程(协程又叫轻量级用户线程)实现模型**
通过前面的介绍,可以将goroutine看做GO语言特有的应用程序线程。但是goroutine背后的支撑体系远没有这么简单。说起Go语言的线程实现模型,有3必须要知道的核心元素,它们支撑起了这个模型的主框架,简单说明如下:
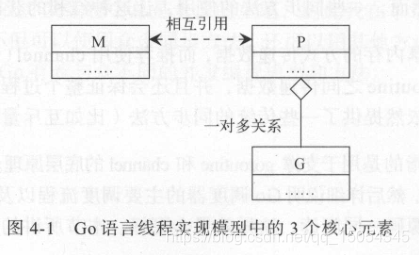
M:machine的缩写,一个M代表一个内核线程,或者称之为“工作线程”
P:processor的缩写。一个P代表执行一个GO代码片段所必须的资源(或称之为“上下文环境”),即用户级线程
G:goroutine的缩写(即协程)。一个G代表一个GO代码片段。前者是对后者的一种封装。
简单来说,一个G(协程)的执行需要P(用户级线程)和M(内核级线程)的支持。一个M在与一个P关联之后,就形成了一个有效的G运行环境(内核线程+上下文环境)。每个P都会包含一个可运行的G的队列(runq)。该队列中的G会被依次传递给与本地关联的M,并获得运行时机。在这里,我们把运行当前G的那个M称之为“当前M”,并把与当前M关联的那个P称之为“本地P”。
- P、G之间的关系:
三者与内核调度实体(KSE)之间的关系:
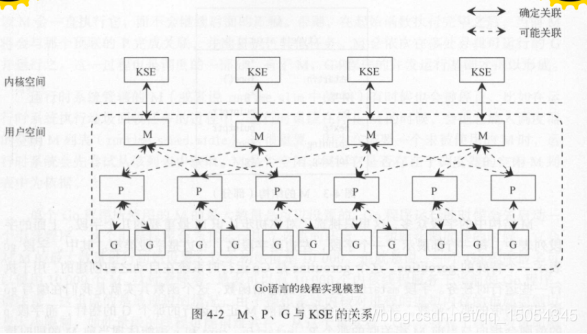
可以看到,M与KSE之间的关系总是一对一之间的关系,一个M仅能代表一个内核线程。GO的运行时系统(runtimesystem)用M代表一个内核调度实体。M与KSE之间的关联非常稳固,一个M在其生命周期内会且仅会与一个KSE产生关联。相比之下,M与P、P与G之间的关联都是易变的,它们之间的关系会在实际调度的过程中改变。其中,M与P之间也总是一对一的,而P与G之间则是一对多的关系(前面提到过P中存在一个可运行G的队列),此外M与G之间也会建立关联,因为一个G终归会有一个M来负责运行;它们至今的关联会由P来牵线。
GO的运行时系统会对这些实体的实例进行实时管理和调度。下面对M、P、G这三个实体进行详细的介绍
- **M**
一个M代表了一个内核线程,在大多数情况下创建一个M都是由于没有足够的M来关联P并运行其中可运行的G。不过在运行时系统执行系统监控或者垃圾回收等任务的时候,也会导致新的M创建。M的部分结构图如下:
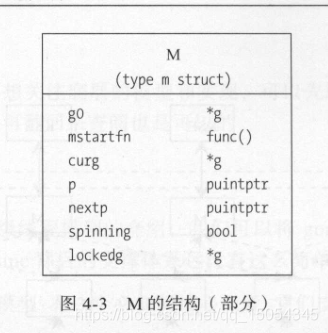
M在创建之初,会被加入到全局的M列表(runtime.allm)中。这时,它的起始函数和预关联的P也会被设置。最后,运行时系统会为这个M专门创建一个新的内核线程并与之相关联。如此一来,这个M就为执行G做好了准备。其中,起始函数仅当运行时系统要用此M执行系统监控或者垃圾回收等任务的时候才会被设置。而这里的全局M列表其实并没有什么特殊的意义。运行时系统在需要的时候,会通过它获取到所有M的信息。同时,它也可以防止M被当做垃圾回收掉。
在新M被创建之后,GO运行时系统会先对它进行一番初始化,其中包括自身所持有的栈空间以及信号处理方面的初始化。在这些所有初始化工作都完成之后,该M的起始函数会执行(如果存在的话)。注意,如果这个起始函数代表的是系统监控任务的话,那么该M会一直执行它,而不会继续后面的例程。否则在起始函数执行完毕之后,当前M将会与那个预联的P完成关联并准备执行其他的任务。M会依次在多处寻找可运行的G并运行之。这一过程也是调度的一部分,有了M,Go程序的并发基础才得以形成
运行时系统管辖的M(或者说runtime.allm中的M)有时候也会被停止,比如在运行时系统执行垃圾回收任务的过程中。运行时系统在停止M的时候,会把它放入调度器的空闲M列表(runtime.sched.midle)。这很重要,因为在需要一个未被使用的M时,运行时系统会尝试先从该列表中获取。M是否空闲,仅以他是否存在于调度器的空闲M类表中为依据。
单个GO程序所使用的M的最大数量是可以设置的。Go程序运行的时候会先启动一个引导程序,这个引导程序会为其运行建立必要的环境。在初始化调度器的时候,它会对M的最大数量进行初始设置,这个初始值是10000 。也就是说,一个GO程序最多可以使用10000个M,这就意味着,最多可以有10000个内核线程服务于当前的Go程序。但是这只是理想的情况下,由于操作系统内核对进程的虚拟内存的布局控制以及大小的限制,如此量级的线程可能很难共存。从这个角度来看,Go本身对于线程数量的限制几乎可以忽略。
2、P
P是G能够在M中运行的关键。GO的运行时系统会适时的让P与不同的M建立或断开关联,以使P中那些可运行的G能够及时获得运行时机,这与操作系统内核在CPU之上实时的切换不同进程或者线程的情形类似。
P的最大数量实际上是对程序中并发运行的G的规模的一种限制。P的数量即为可运行的G的队列的数量。一个G在被启用之后,会先被追加到某个P的可运行G队列中,以等待运行时机。一个P只有与一个M关联在一起才会使其可运行G队列中的G有机会运行。不过设置P的最大数量只能限制住P的数量,而对G和P的数量没有任何约束。当M因系统调用而阻塞(更确切的说是它运行的G进行了系统调用)的时候,运行系统会把该M和与之关联的P分离开来。这时,如果这个P的可运型G队列中还有未被运行的G,那么运行时系统就会找到一个空闲的M,或者创建一个新的M,并与该P关联以满足这些G的运行需要。因此,M的数量在很多的时候也会比P多。而G的数量一般取决于GO程序本身。
本文转自 https://blog.csdn.net/qq_15054345/article/details/89964800,如有侵权,请联系删除。













