

2020 年,新冠肺炎疫情催化数字化生活方式渐成常态。在企业积极进行数字化转型、全面提升效率的今天,几乎无人否认背负“降本增效”使命诞生的 Serverless 即将成为云时代新的计算范式。
Serverless 将开发者从繁重的手动资源管理和性能优化中解放出来,正在引发云计算生产力的新变革。
然而,Serverless 的落地问题却往往很棘手,例如传统项目如何迁移到 Serverless,同时保障迁移过程业务连续性,在 Serverless 架构下如何提供完善的开发工具、有效的调试诊断工具,如何利用 Serverless 做更好的节约成本等,每一个都是难题。
尤其涉及到在主流场景大规模的落地 Serverless ,更是并非易事。正因为这样,业界对于 Serverless 核心场景规模化落地最佳实践的呼唤更加迫切。
总交易额 4982 亿元,订单创建峰值 58.3 万笔/秒,2020 年天猫 双11 又一次创造记录。对于阿里云来说,今年的 双11 还有另一个意义:阿里云实现了国内首例 Serverless 在核心业务场景下的大规模落地,扛住了全球最大规模的流量洪峰,创造了 Serverless 落地应用的里程碑。
Serverless 落地之痛
挑战一:冷启动耗时长
快弹是 Serverless 天然自带的属性,但是快弹的条件是要有极致的冷启动速度去支撑。在非核心的业务上,毫秒级别的延时,对业务来说几乎不受影响。但是,对于核心业务场景,延时超过 500 毫秒已经会影响到用户体验。
虽然 Serverless 利用轻量化的虚拟技术,不断的降低冷启动,甚至某些场景能降低到 200 毫秒以下。但这也只是理想的独立运行场景,在核心业务链路上,用户不仅是运行自己的业务逻辑,还要依赖中间件、数据库、存储等后端服务,这些服务的连接都要在实例启动的时候进行建连,这无形中加大了冷启动的时间,进而把冷启动的时间加长到秒级别。
对于核心在线业务场景来说,秒级别的冷启动是不可接受的。
挑战二:与研发流程割裂
Serverless 主打的场景是像写业务函数一样去写业务代码,简单快速即可上线,让开发者在云上写代码,轻松完成上线。
然而在现实中,核心业务的要求把开发者从云上拉回到现实,面对几个灵魂拷问:如何做测试?如何灰度上线?如何做业务的容灾?如何控制权限?
当开发者回答完了这些问题,就会变的心灰意冷,原来在核心业务上线中,“函数正常运行”只占了小小的一环,离上线的距离还有长江那么长。
挑战三:中间件的连通问题
核心在线业务不是独立函数孤立运行的,需要连接存储、中间件、数据中后台服务,获取数据后再计算,进而输出返回给用户。
传统中间件客户端需要打通和客户的网络、初始化建连等一系列操作,往往会使函数启动速度下降很多。
Serverless 场景下实例生命周期短、数量多,会导致频繁建连、连接数多的问题,因此针对在线核心应用常用的中间件的客户端进行网络连通优化,同时对调用链路进行监控数据打通,帮助 SRE (Site Reliability Engineer )从业者更好的评估函数的下游中间件依赖情况,对于核心应用迁移上 Serverless 非常重要。
挑战四:可观测性差
用户大多数的核心业务应用多采用微服务架构,看核心业务应用的问题也就会带有微服务的特性,比如用户需要对业务系统的各种指标进行非常详尽的检查,不仅需要检查业务指标,还需要检查业务所在系统的资源指标,但是在 Serverless 场景中没有机器资源的概念,那这些指标如何透出?是否只透出请求的错误率和并发度,就可以满足业务方的需求?
实际上,业务方的需求远不止这些。可观测性做的好坏还是源于业务方是否信任你的技术平台。做好可观测性是赢得用户信任的重要前提。
挑战五:远程调试难度高
当核心业务出现线上问题时,需要立即进入调查,而调查的第一要素就是:现场的保留,然后登陆进行调试。而在 Serverless 场景中没有机器层面的概念,所以如果用户想登陆机器,在现有的 Serverless 基础技术之上是很难做到的。当然原因不仅限于此,比如 Vendor-lockin 的担心等。
上面几大类痛点的概括,主要是针对开发者的开发体验,对于实际的开发场景中,是否真的是"提效", 而不是新瓶装旧酒。目前仍有大部分核心应用开发者对 Serverless 还是持有观望状态,当然也不乏一些质疑观点,“FaaS 只适合小业务场景以及非核心业务场景”。
Serverless 的 双11 “大考”
2019 年 12 月咨询公司 O'Reill 发布 Serverless 使用调研中,已有 40% 的受访者所在的组织采用了 Serverless。2020 年 10 月,中国信息通信研究院发布的《中国云原生用户调研报告》指出:“Serverless 技术显著升温,近 30% 的用户已在生产环境中应用。”2020 年,越来越多企业选择加入 Serverless 阵营,翘首以待更多 Serverless 规模化落地核心场景的案例。
面对 Serverless 开发者数量的稳步增长的现状,阿里巴巴年初就制定了“打造 Serverless 双11”的策略,目的不只是单纯的去抗流量、打峰值,而是切实的降成本,提高资源利用率,通过 “双11 技术炼金炉”把阿里云 Serverless 打造成更安全、更稳定、更友好的云产品,帮助用户实现更大的业务价值。
与过去 11 年的 双11 都不同的是,继去年天猫 双11 核心系统上云后,阿里巴巴基于数字原生商业操作系统,实现了全面云原生化,底层硬核技术升级带来了澎湃动力和极致效能。以支撑订单创建峰值为例,每万笔峰值交易的 IT 成本较四年前下降了 80%。Serverless 也迎来了首次在 双11 核心场景下的规模化落地。
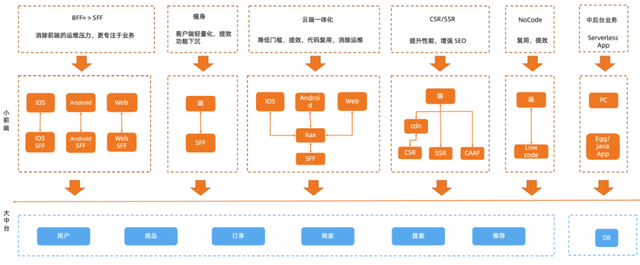
场景一:前端多场景
2020 年 双11,阿里巴巴集团前端全面拥抱云原生 Serverless,淘系、飞猪、高德、CBU、ICBU、优酷、考拉等十数 BU ,共同落地了以 Node.js FaaS 在线服务架构为核心的云端一体研发模式。
今年 双11 在保障稳定性、高资源利用率的前提下,多 BU 的重点营销导购场景实现了研发模式升级。前端 FaaS 支撑的云端一体研发模式交付平均提效 38.89%。依托 Serverless 的便利性和可靠性,淘宝、天猫、飞猪等 双11 会场页面快捷落地 SSR 技术,提高了用户页面体验,除了保障大促以外,日常弹性下也较以往减少 30% 计算成本。
场景二:个性化推荐场景
Serverless 天然的弹性伸缩能力,是“个性化推荐业务场景”选择由 Serverless 实现的最重要原因,数以千计的异构应用运维成本一直是这个场景下的痛点。通过 Serverless 化进一步释放运维,让开发者专注于业务的算法创新。
目前这个场景的应用范围越来越广,已经覆盖了几乎整个阿里系 APP:淘宝,天猫,支付宝,优酷,飞猪等等,因此我们可以对机器资源利用率方面做更多的优化,通过智能化的调度,在峰值时的机器资源利用率达到了 60%。
场景三:中、后台场景
2020 年,世纪联华 双11 基于阿里云函数计算(FC)弹性扩容,在大促会场 SSR、线上商品秒杀、优惠券定点发放、行业导购、数据中台计算等多个场景进行应用,业务峰值 QPS 超过 2019 年 双11 的 230%,研发效率交付提效超过 30%,弹性资源成本减少 40% 以上。

当然,适用于 Serverless 的场景还有很多,需要更多行业的开发者们共同丰富。总的来说,今年 FaaS 的成绩单非常耀眼,在 双11 大促中,不仅承接了部分核心业务,流量也突破新高,帮助业务扛住了百万 QPS 的流量洪峰。
阿里云如何击破 Serverless 痛点?
那么,面对行业共有的 Serverless 落地之痛,阿里云是如何克服的呢?
1. 预留模式 + 按量模式消除冷启动
在 2019 年的 Serverless 2.0 重大升级中,阿里云函数计算率先支持了预留模式,接着 AWS Lambda 几个月后,也上线了类似的功能。
为什么阿里云会率先提出这个问题?阿里云 Serverless 团队不断探索真实业务的需求,按量模式的按需付费模式,虽然非常的诱人,但是冷启动时间过长,因此把核心在线业务拒之门外。接下来阿里云着重分析了核心在线业务的诉求:延时小,保证资源弹性。那如何解决呢?
请看下图,一个非常典型的业务曲线图,用预留模式方式满足底部固定的量,用弹性能力去满足 burst 的需求。
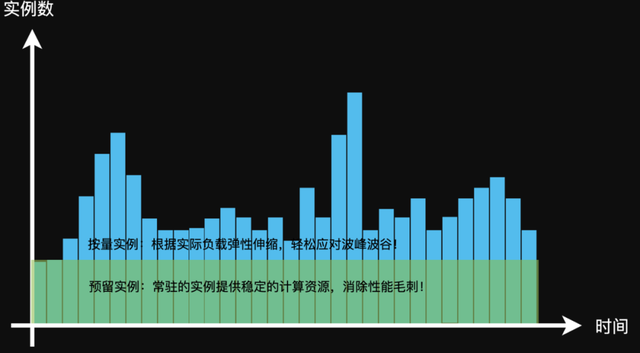
针对 burst 扩容,我们利用两种扩容方式结合进行满足:按资源扩容与按请求扩容,比如用户可以只设置 CPU 资源的扩容阈值为 60%,当实例的 CPU 达到阈值后,就会触发扩容。此时的新请求并没有立即到扩容实例,而是等待实例准备好后再导流,从而避免了冷启动。
同理,如果只设置了并发度指标的扩容阈值为 30(每一个实例承载的并发度),同样满足这个条件后,也会触发同样流程的扩容。如果两个指标都进行了设置,那么先满足的条件会先触发扩容。
通过丰富的伸缩方式,阿里云函数计算解决了 Serverless 冷启动的问题,很好的支撑了延时敏感业务。
2. 核心业务研发提效 38.89%
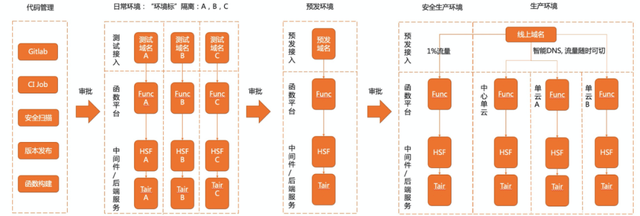
“提升效率”本应该是 Serverless 的优势,但对于核心应用来说,"快" = "风险大",用户需要经过 CI 测试,日常测试,预发测试,灰度部署等几个流程验证,才能确保函数的质量。这些流程是阻碍核心应用使用 FaaS 的绊脚石。
针对于这个问题,阿里云函数计算的策略是" 被集成“,把研发平台的优势与阿里云函数计算进行结合,既能满足用户的 CI/CD 流程,又能享受到 Serverless 的红利,帮用户跨过使用 FaaS 的鸿沟。
阿里集团内部通过暴露标准的 OpenAPI 与各个核心应用的研发平台进行集成,经过双十一业务研发的验证,研发效率大大提高了 38.89%。在公有云上我们与云效平台集成,把研发流程与 FaaS 结合的更紧密、更顺畅,帮助集团外的业务提高人效。
3. 中间件连通
核心应用离不开上下游的配合,一旦核心应用使用了函数计算,又该如何与中间件相配合?传统应用开发需要集成各类中间件的 SDK,进行打包上线,但对于 Serverless 的函数来说,代码包的大小就是一个硬伤,这个问题将将直接影响冷启动的时间。
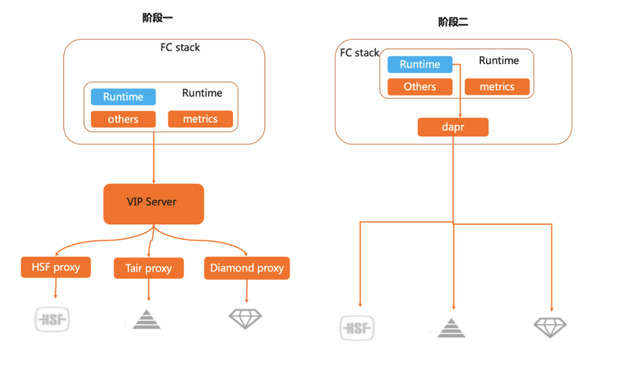
阿里云函数计算经过两个阶段的发展,第一个阶段我们通过搭建中间件 Proxy,通过 Proxy 去打通中间件,函数只用单一的协议与 Proxy 进行交互,从而 offload 掉中间件的 SDK 的包袱。
第二个阶段:随着中间件能力的下沉,一些控制类型的需求也被提上了议程,比如:命令下发,流量管理,配置拉取等等,期间阿里云拥抱了开源组件 Dapr,利用 Sidecar 的方式 Offload 中间的交互成本。
上述的方案,是基于阿里云函数计算的 Custom Runtime,以及 Custom Container 功能完成的。
4. 极致的开发体验
远程调试、日志查看、链路追踪、资源利用率,以及完善周边工具链是开发者的必备能力。阿里云函数计算同时启动了不同的攻关小组,首先与 Tracing/ARMS 结合,打造清晰的链路追能力,与 SLS 集成打造了全面的业务数据监控。
因此,业务可以根据需求进行自定义,并且拥抱开源产品 Prometheus 暴露出资源利用率,支持远程调试能力的 WebIDE。
再加上阿里云近期刚开源的重磅武器:Serverless-devs ,一个无厂商绑定的、帮助开发者在 Serverless 架构下实现开发/运维效率翻倍的开发者工具。开发者可以简单、快速的创建应用、项目开发、项目测试、发布部署等,实现项目的全生命周期管理。
Serverless 初始的痛点有很多,为什么阿里云却能把 Serverless 落地到各行各业?
首先,阿里云提供了所有云厂商中最完整的 Serverless 产品矩阵,包括函数计算 FC、Serverless 应用引擎 SAE、面向容器编排的 ASK、以及面向容器实例的 ECI。
丰富的产品矩阵能够覆盖不同的场景,比如针对事件触发场景,函数计算提供了丰富的事件源集成能力和百毫秒伸缩的极致弹性;而针对微服务应用,Serverless 应用引擎能做到零代码改造,让微服务也能享受 Serverless 红利。
其次, Serverless 是一个快速发展的领域,阿里云在不断拓展 Serverless 的产品边界。例如函数计算支持容器镜像、预付费模式、实例内并发执行多请求等多个业界首创的功能,彻底解决了冷启动带来的性能毛刺等 Serverless 难题,大大拓展了函数计算的应用场景。
最后,阿里经济体拥有非常丰富的业务场景,可以进一步打磨 Serverless 的落地实践。今年阿里经济体的淘系、考拉、飞猪、高德等多个 BU 的 双11 核心业务场景均使用了阿里云函数计算,并顺利扛住了 双11 的高峰。
Serverless 引领下一个十年
“劳动生产力的最大激进,以及运用劳动时所表现的更大熟练、技巧和判断力,似乎都是劳动分工的结果” ,这是摘自《国富论》的一段话,强调的是“劳动分工”的利害关系,任何一个行业,市场规模越大,分工将会越细,这也是著名的“斯密定理”。
同样,这一定理也适用于软件应用市场行业,随着传统行业进入了互联网化阶段,市场规模越来越大,劳动分工越来越细,物理机托管时代已经成为了历史,被成熟的 IaaS 层取代,随之而来的是容器服务,目前也已经是行业的标配。
那么,接下来的技术十年是什么呢?答案是:Serverless,抹平了研发人员在预算、运维经验上的不足,在对抗业务洪峰的情况下,绝大多数研发也能轻易掌控处理,不仅极大地降低了研发技术门槛,同时大规模提升了研发效率,线上预警、流量观测等工具一应俱全,轻松做到了技术研发的免运维,可以说 Serverless 是更细粒度的分工,让业务开发者不再关注底层运维,只关注于业务创新,以此大大提高了劳动生产力,这就是“斯密定理”效应,也是 Serverless 成为未来必然趋势的内在原因。
当下,整个云的产品体系已经 Serverless 化,70% 以上的产品都是 Serverless 形态。对象存储、消息中间件、API 网关、表格存储等 Serverless 产品已经被广大开发者熟知。下一个十年, Serverless 将重新定义云的编程模型,重塑企业创新的方式。
本文为阿里云原创内容,未经允许不得转载。











