
性能监控分析的命令包括如下:
1、vmstat
2、sar
3、iostat
4、top
5、free
6、uptime
7、netstat
8、ps
9、strace
10、lsof
命令介绍:
free命令是监控Linux内存使用最常用的命令
语法格式:
free [options]
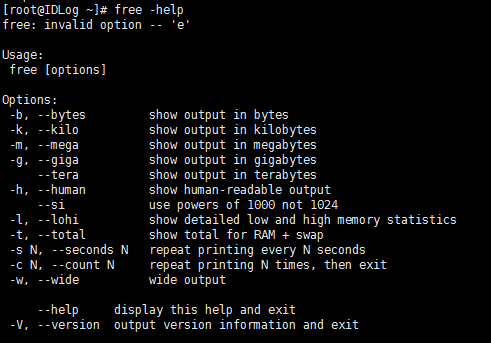
参数说明:
-m:以M为单位查看内容使用情况(默认为kb)
-b:以字节为单位查看内存使用情况
-s:可以在指定时间段内不间断监控内存使用情况
-k:以KB为单位显示内存使用情况
-g:以GB为单位显示内存使用情况
-o:不显示缓冲区调节列
-t:显示内存总和列
-V:显示版本信息
free命令执行结果如下:

各个字段说明:
total:总计物理内存的大小
used:已使用的大小
free:空闲可用的大小
shared:多个进程共享的内存总额
buffers/cached:磁盘缓存的大小
第三行(-/+ buffers/cache)
used:已使用多大
free:可用有多少
第四行是交换分区SWAP的,也就是我们通常所说的虚拟内存。
第二行与第三行used/free区别:
这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是1651532KB,已用内存是287436KB,其中包括,内核(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached。
如本机情况的可用内存为:
1864980=1651532KB+23688KB+760KB
我们使用total1、used1、free1、used2、free2 等名称来代表上面统计数据的各值
可以整理出如下等式:
total1 = used1 + free1
total1 = used2 + free2
used1 = buffers1 + cached1 + used2
free2 = buffers1 + cached1 + free1
cache 和 buffer的区别:
Cache: 高速缓存,是位于CPU与主内存间的一种容量较小但速度很高的存储器。由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周 期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,这样就减少了CPU的等待时间,提 高了系统的效率。Cache又分为一级Cache(L1 Cache)和二级Cache(L2 Cache),L1 Cache集成在CPU内部,L2 Cache早期一般是焊在主板上,现在也都集成在CPU内部,常见的容量有256KB或512KB L2 Cache。
Buffer:缓冲区,一个用于存储速度不同步的设备或优先级不同的设备之间传输数据的区域。通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据时,速度快的设备的操作进程不发生间断。
Free中的buffer和cache:(它们都是占用内存):
buffer: 作为buffer cache的内存,是块设备的读写缓冲区
cache: 作为page cache的内存, 文件系统的cache
如果 cache 的值很大,说明cache住的文件数很多。如果频繁访问到的文件都能被cache住,那么磁盘的读IO bi会非常小。
Buffers和Cached的区别
缓存(cached)是把读取过的数据保存起来,重新读取时若命中(找到需要的数据)就不要去读硬盘了,若没有命中就读硬盘。其中的数据会根据读取频率进行组织,把最频繁读取的内容放在最容易找到的位置,把不再读的内容不断往后排,直至从中删除。
缓冲(buffers)是根据磁盘的读写设计的,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。linux有一个守护进程定 期清空缓冲内容(即写如磁盘),也可以通过sync命令手动清空缓冲。举个例子吧:我这里有一个ext2的U盘,我往里面cp一个3M的MP3,但U盘的 灯没有跳动,过了一会儿(或者手动输入sync)U盘的灯就跳动起来了。卸载设备时会清空缓冲,所以有些时候卸载一个设备时要等上几秒钟。
修改/etc/sysctl.conf中的vm.swappiness右边的数字可以在下次开机时调节swap使用策略。该数字范围是0~100,数字越大越倾向于使用swap。默认为60,可以改一下试试。
两者都是RAM中的数据。简单来说,buffer是即将要被写入磁盘的,而cache是被从磁盘中读出来的。
buffer是由各种进程分配的,被用在如输入队列等方面,一个简单的例子如某个进程要求有多个字段读入,在所有字段被读入完整之前,进程把先前读入的字段放在buffer中保存。
cache经常被用在磁盘的I/O请求上,如果有多个进程都要访问某个文件,于是该文件便被做成cache以方便下次被访问,这样可提供系统性能。
接下来解释什么时候内存会被交换,以及按什么方交换:
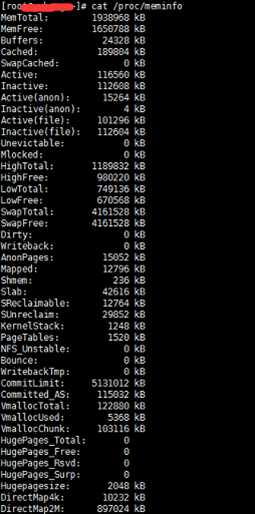
当可用内存少于额定值的时候,就会开会进行交换;查看额定值的命令:
#cat /proc/meminfo
交换将通过三个途径来减少系统中使用的物理页面的个数:
1.减少缓冲与页面cache的大小,
2.将系统V类型的内存页面交换出去,
3.换出或者丢弃页面。(Application 占用的内存页,也就是物理内存不足)。
事实上,少量地使用swap是不是影响到系统性能的。
常用操作
free //以KB为单位,显式系统内存使用情况
free -ml -s 1 //每秒以M为单位,显式系统内存详细使用情况。
free -c 4 -s 2 //为KB为单位,每2秒显式系统内存使用情况,一共显示4次
free -t //以总和的形式显示内存的使用信息
free -s 10 //周期性的查询内存使用信息,每10s 执行一次命令
参考文档:
https://www.cnblogs.com/ggjucheng/archive/2012/01/08/2316438.html
https://www.cnblogs.com/peida/archive/2012/12/25/2831814.html












