
公众号关注“杰哥的IT之旅”,
选择“星标”,重磅干货,第一时间送达!

来源丨图灵人工智能
让我们看一下使用Python进行数据可视化的主要库以及可以使用它们完成的所有类型的图表。我们还将看到建议在每种情况下使用哪个库以及每个库的独特功能。
我们将从最基本的可视化开始,直接查看数据,然后继续绘制图表,最后制作交互式图表。
数据集
我们将使用两个数据集来适应本文中显示的可视化效果,数据集可通过下方链接进行下载。
数据集:github.com/albertsl/dat
这些数据集都是与人工智能相关的三个术语(数据科学,机器学习和深度学习)在互联网上搜索流行度的数据,从搜索引擎中提取而来。
该数据集包含了两个文件temporal.csv和mapa.csv。在这个教程中,我们将更多使用的第一个包括随时间推移(从2004年到2020年)的三个术语的受欢迎程度数据。另外,我添加了一个分类变量(1和0)来演示带有分类变量的图表的功能。
mapa.csv文件包含按国家/地区分隔的受欢迎程度数据。在最后的可视化地图时,我们会用到它。
Pandas
在介绍更复杂的方法之前,让我们从可视化数据的最基本方法开始。我们将只使用熊猫来查看数据并了解其分布方式。
我们要做的第一件事是可视化一些示例,查看这些示例包含了哪些列、哪些信息以及如何对值进行编码等等。
import pandas as pddf = pd.read_csv('temporal.csv')df.head(10) #View first 10 data rows
使用命令描述,我们将看到数据如何分布,最大值,最小值,均值……
df.describe()
使用info命令,我们将看到每列包含的数据类型。我们可以发现一列的情况,当使用head命令查看时,该列似乎是数字的,但是如果我们查看后续数据,则字符串格式的值将被编码为字符串。
df.info()

通常情况下,pandas都会限制其显示的行数和列数。这可能让很多程序员感到困扰,因为大家都希望能够可视化所有数据。
使用这些命令,我们可以增加限制,并且可以可视化整个数据。对于大型数据集,请谨慎使用此选项,否则可能无法显示它们。
pd.set_option('display.max_rows',500)pd.set_option('display.max_columns',500)pd.set_option('display.width',1000)
使用Pandas样式,我们可以在查看表格时获得更多信息。首先,我们定义一个格式字典,以便以清晰的方式显示数字(以一定格式显示一定数量的小数、日期和小时,并使用百分比、货币等)。不要惊慌,这是仅显示而不会更改数据,以后再处理也不会有任何问题。
为了给出每种类型的示例,我添加了货币和百分比符号,即使它们对于此数据没有任何意义。
format_dict = {'data science':'${0:,.2f}', 'Mes':'{:%m-%Y}', 'machine learning':'{:.2%}'}#We make sure that the Month column has datetime formatdf['Mes'] = pd.to_datetime(df['Mes'])#We apply the style to the visualizationdf.head().style.format(format_dict)
我们可以用颜色突出显示最大值和最小值。
format_dict = {'Mes':'{:%m-%Y}'} #Simplified format dictionary with values that do make sense for our datadf.head().style.format(format_dict).highlight_max(color='darkgreen').highlight_min(color='#ff0000')
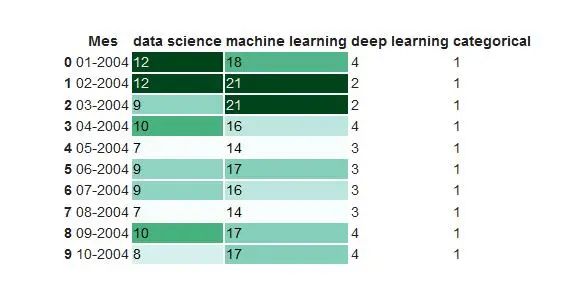
我们使用颜色渐变来显示数据值。
df.head(10).style.format(format_dict).background_gradient(subset=['data science', 'machine learning'], cmap='BuGn')
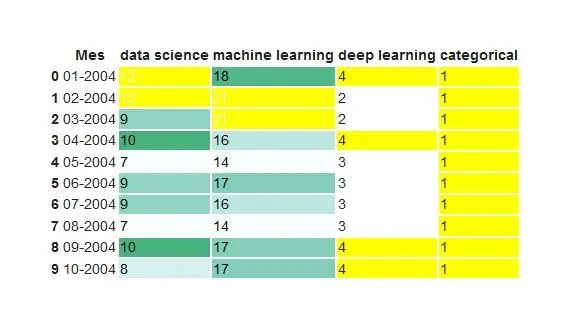
我们也可以用条形显示数据值。
df.head().style.format(format_dict).bar(color='red', subset=['data science', 'deep learning'])

此外,我们还可以结合以上功能并生成更复杂的可视化效果。
df.head(10).style.format(format_dict).background_gradient(subset = ['data science','machine learning'],cmap ='BuGn')。highlight_max(color ='yellow')
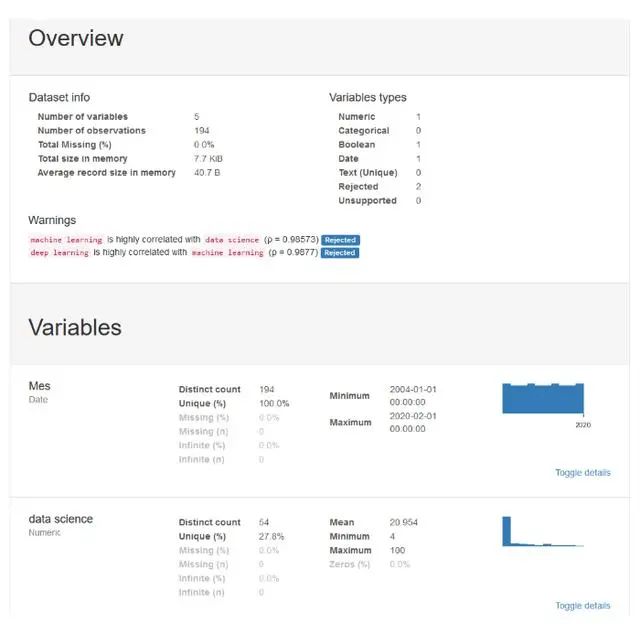
Pandas分析
Pandas分析是一个库,可使用我们的数据生成交互式报告,我们可以看到数据的分布,数据的类型以及可能出现的问题。它非常易于使用,只需三行,我们就可以生成一个报告,该报告可以发送给任何人,即使您不了解编程也可以使用。
from pandas_profiling import ProfileReportprof = ProfileReport(df)prof.to_file(output_file='report.html')
Matplotlib
Matplotlib是用于以图形方式可视化数据的最基本的库。它包含许多我们可以想到的图形。仅仅因为它是基本的并不意味着它并不强大,我们将要讨论的许多其他数据可视化库都基于它。
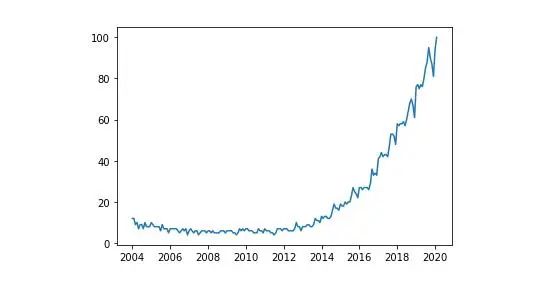
Matplotlib的图表由两个主要部分组成,即轴(界定图表区域的线)和图形(我们在其中绘制轴,标题和来自轴区域的东西),现在让我们创建最简单的图:
import matplotlib.pyplot as pltplt.plot(df['Mes'], df['data science'], label='data science') #The parameter label is to indicate the legend. This doesn't mean that it will be shown, we'll have to use another command that I'll explain later.
我们可以在同一张图中制作多个变量的图,然后进行比较。
plt.plot(df ['Mes'],df ['data science'],label ='data science')plt.plot(df ['Mes'],df ['machine learning'],label ='machine learning ')plt.plot(df ['Mes'],df ['deep learning'],label ='deep learning')
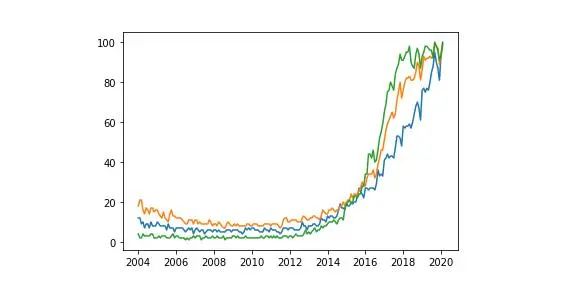
每种颜色代表哪个变量还不是很清楚。我们将通过添加图例和标题来改进图表。
plt.plot(df['Mes'], df['data science'], label='data science')plt.plot(df['Mes'], df['machine learning'], label='machine learning')plt.plot(df['Mes'], df['deep learning'], label='deep learning')plt.xlabel('Date')plt.ylabel('Popularity')plt.title('Popularity of AI terms by date')plt.grid(True)plt.legend()
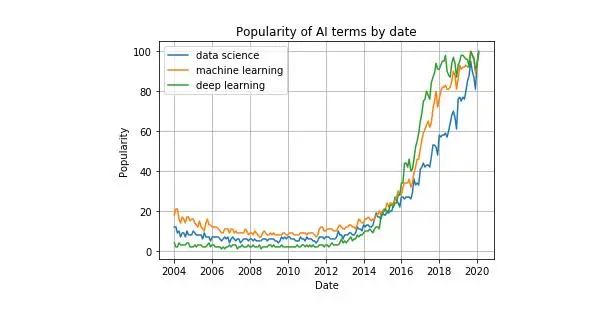
如果您是从终端或脚本中使用Python,则在使用我们上面编写的函数定义图后,请使用plt.show()。如果您使用的是Jupyter Notebook,则在制作图表之前,将%matplotlib内联添加到文件的开头并运行它。
我们可以在一个图形中制作多个图形。这对于比较图表或通过单个图像轻松共享几种图表类型的数据非常有用。
fig, axes = plt.subplots(2,2)axes[0, 0].hist(df['data science'])axes[0, 1].scatter(df['Mes'], df['data science'])axes[1, 0].plot(df['Mes'], df['machine learning'])axes[1, 1].plot(df['Mes'], df['deep learning'])
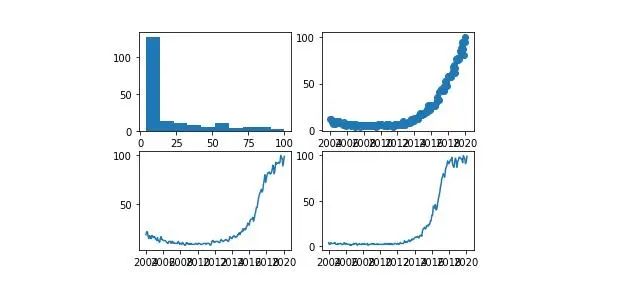
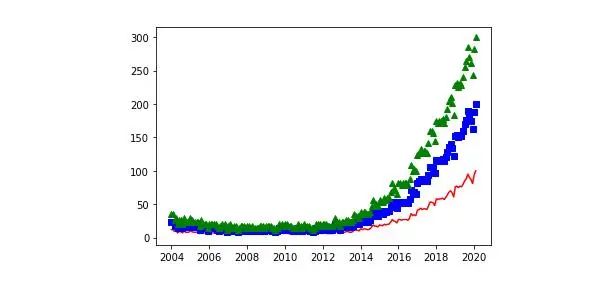
我们可以为每个变量的点绘制具有不同样式的图形:
plt.plot(df ['Mes'],df ['data science'],'r-')plt.plot(df ['Mes'],df ['data science'] * 2,'bs')plt .plot(df ['Mes'],df ['data science'] * 3,'g ^')
现在让我们看一些使用Matplotlib可以做的不同图形的例子。我们从散点图开始:
plt.scatter(df['data science'], df['machine learning'])
条形图示例:
plt.bar(df ['Mes'],df ['machine learning'],width = 20)
直方图示例:
plt.hist(df ['deep learning'],bins = 15)
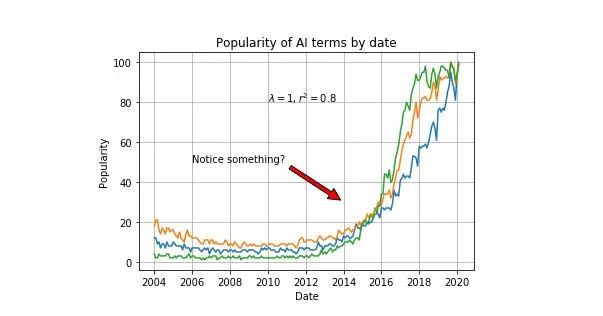
我们可以在图形中添加文本,并以与图形中看到的相同的单位指示文本的位置。在文本中,我们甚至可以按照TeX语言添加特殊字符
我们还可以添加指向图形上特定点的标记。
plt.plot(df['Mes'], df['data science'], label='data science')plt.plot(df['Mes'], df['machine learning'], label='machine learning')plt.plot(df['Mes'], df['deep learning'], label='deep learning')plt.xlabel('Date')plt.ylabel('Popularity')plt.title('Popularity of AI terms by date')plt.grid(True)plt.text(x='2010-01-01', y=80, s=r'$\lambda=1, r^2=0.8$') #Coordinates use the same units as the graphplt.annotate('Notice something?', xy=('2014-01-01', 30), xytext=('2006-01-01', 50), arrowprops={'facecolor':'red', 'shrink':0.05})
Seaborn
Seaborn是基于Matplotlib的库。基本上,它提供给我们的是更好的图形和功能,只需一行代码即可制作复杂类型的图形。
我们导入库并使用sns.set()初始化图形样式,如果没有此命令,图形将仍然具有与Matplotlib相同的样式。我们显示了最简单的图形之一,散点图:
import seaborn as snssns.set()sns.scatterplot(df['Mes'], df['data science'])
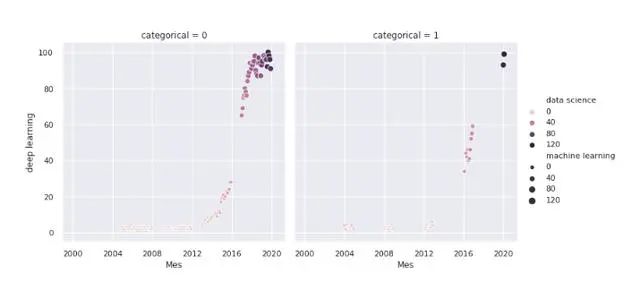
我们可以在同一张图中添加两个以上变量的信息。为此,我们使用颜色和大小。我们还根据类别列的值制作了一个不同的图:
sns.relplot(x='Mes', y='deep learning', hue='data science', size='machine learning', col='categorical', data=df)
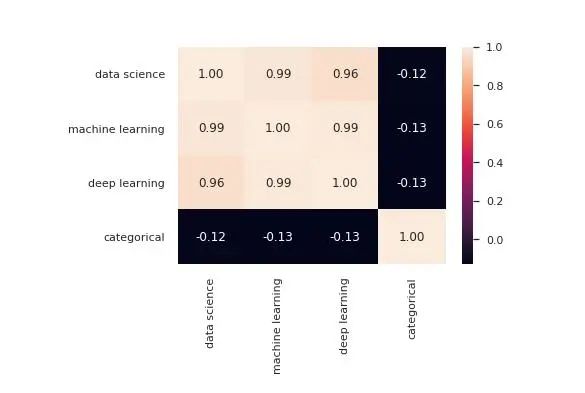
Seaborn提供的最受欢迎的图形之一是热图。通常使用它来显示数据集中变量之间的所有相关性:
sns.heatmap(df.corr(),annot = True,fmt ='。2f')
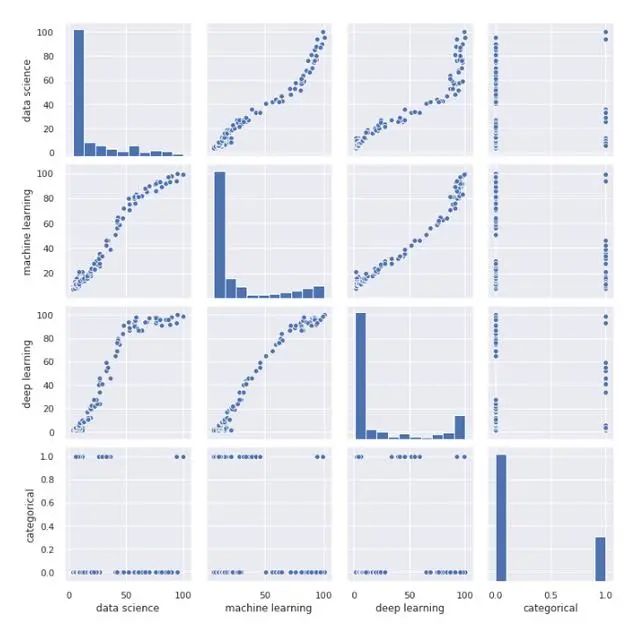
另一个最受欢迎的是配对图,它向我们显示了所有变量之间的关系。如果您有一个大数据集,请谨慎使用此功能,因为它必须显示所有数据点的次数与有列的次数相同,这意味着通过增加数据的维数,处理时间将成倍增加。
sns.pairplot(df)
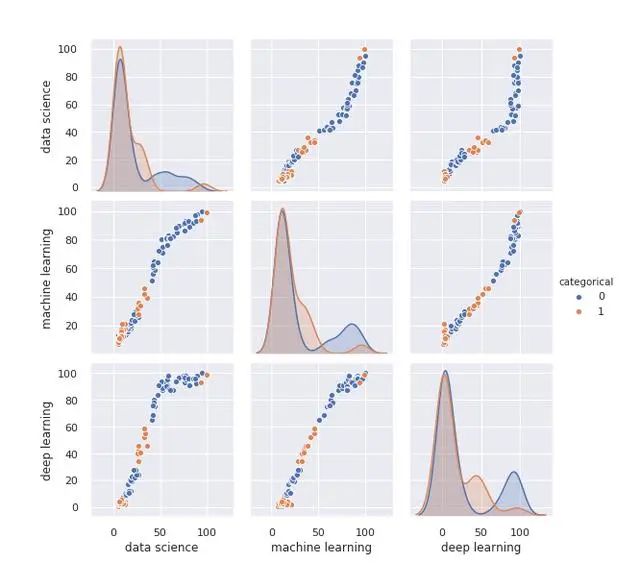
现在让我们做一个成对图,显示根据分类变量的值细分的图表。
sns.pairplot(df,hue ='categorical')
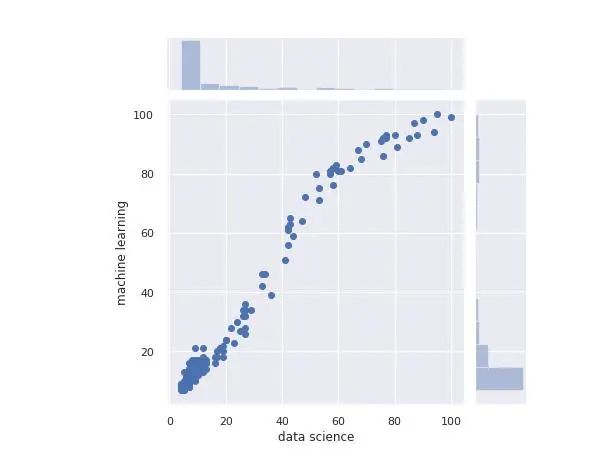
联合图是一个非常有用的图,它使我们可以查看散点图以及两个变量的直方图,并查看它们的分布方式:
sns.jointplot(x='data science', y='machine learning', data=df)
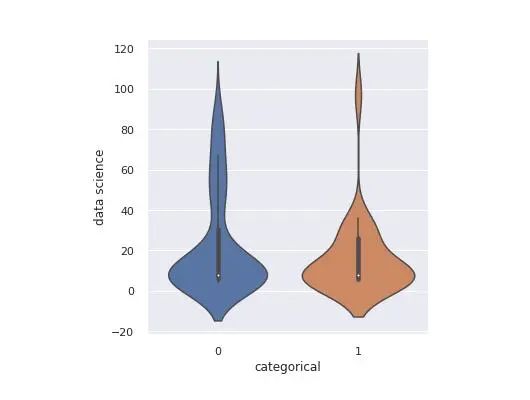
另一个有趣的图形是ViolinPlot:
sns.catplot(x='categorical', y='data science', kind='violin', data=df)
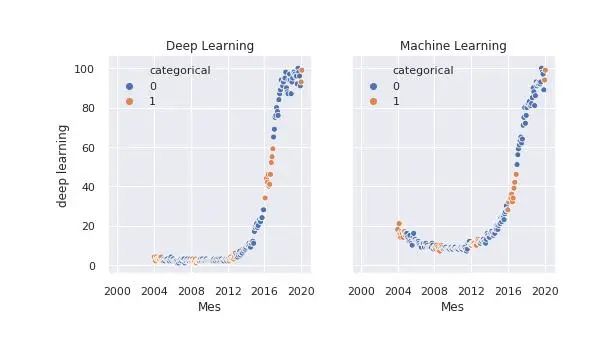
我们可以像使用Matplotlib一样在一个图像中创建多个图形:
fig, axes = plt.subplots(1, 2, sharey=True, figsize=(8, 4))sns.scatterplot(x="Mes", y="deep learning", hue="categorical", data=df, ax=axes[0])axes[0].set_title('Deep Learning')sns.scatterplot(x="Mes", y="machine learning", hue="categorical", data=df, ax=axes[1])axes[1].set_title('Machine Learning')
Bokeh
Bokeh是一个库,可用于生成交互式图形。我们可以将它们导出到HTML文档中,并与具有Web浏览器的任何人共享。
当我们有兴趣在图形中查找事物并且希望能够放大并在图形中移动时,它是一个非常有用的库。或者,当我们想共享它们并给其他人探索数据的可能性时。
我们首先导入库并定义将要保存图形的文件:
from bokeh.plotting import figure, output_file, saveoutput_file('data_science_popularity.html')
我们绘制所需内容并将其保存在文件中:
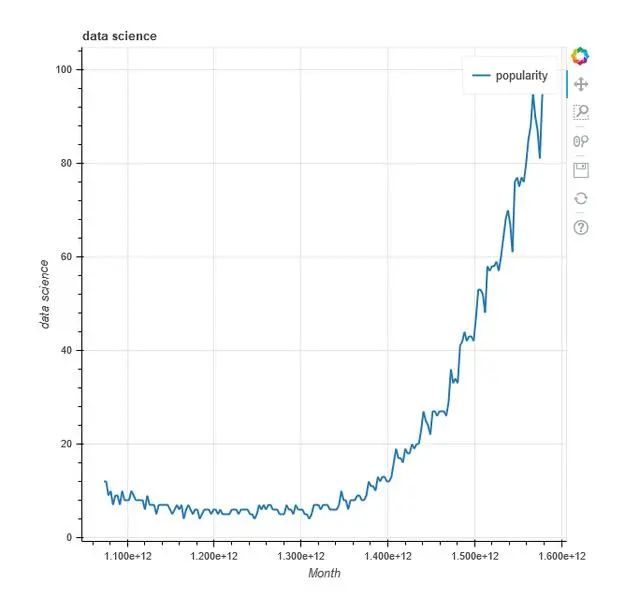
p = figure(title='data science', x_axis_label='Mes', y_axis_label='data science')p.line(df['Mes'], df['data science'], legend='popularity', line_width=2)save(p)
将多个图形添加到单个文件:
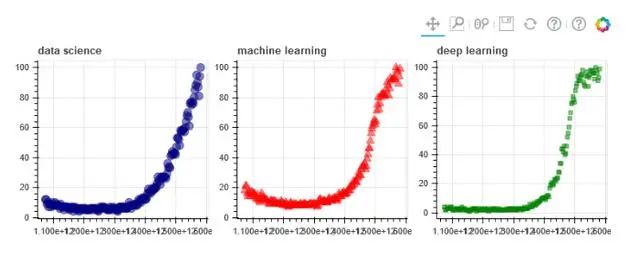
output_file('multiple_graphs.html')s1 = figure(width=250, plot_height=250, title='data science')s1.circle(df['Mes'], df['data science'], size=10, color='navy', alpha=0.5)s2 = figure(width=250, height=250, x_range=s1.x_range, y_range=s1.y_range, title='machine learning') #share both axis ranges2.triangle(df['Mes'], df['machine learning'], size=10, color='red', alpha=0.5)s3 = figure(width=250, height=250, x_range=s1.x_range, title='deep learning') #share only one axis ranges3.square(df['Mes'], df['deep learning'], size=5, color='green', alpha=0.5)p = gridplot([[s1, s2, s3]])save(p)
Altair
我认为Altair不会给我们已经与其他图书馆讨论的内容带来任何新的东西,因此,我将不对其进行深入讨论。我想提到这个库,因为也许在他们的示例画廊中,我们可以找到一些可以帮助我们的特定图形。
Folium
Folium是一项研究,可以让我们绘制地图,标记,也可以在上面绘制数据。Folium让我们选择地图的提供者,这决定了地图的样式和质量。在本文中,为简单起见,我们仅将OpenStreetMap视为地图提供者。
使用地图非常复杂,值得一读。在这里,我们只是看一下基础知识,并用我们拥有的数据绘制几张地图。
让我们从基础开始,我们将绘制一个简单的地图,上面没有任何内容。
import foliumm1 = folium.Map(location=[41.38, 2.17], tiles='openstreetmap', zoom_start=18)m1.save('map1.html')
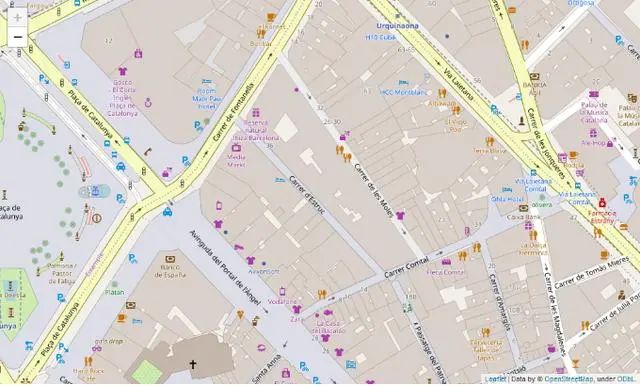
我们为地图生成一个交互式文件,您可以在其中随意移动和缩放。
我们可以在地图上添加标记:
m2 = folium.Map(location=[41.38, 2.17], tiles='openstreetmap', zoom_start=16)folium.Marker([41.38, 2.176], popup='<i>You can use whatever HTML code you want</i>', tooltip='click here').add_to(m2)folium.Marker([41.38, 2.174], popup='<b>You can use whatever HTML code you want</b>', tooltip='dont click here').add_to(m2)m2.save('map2.html')
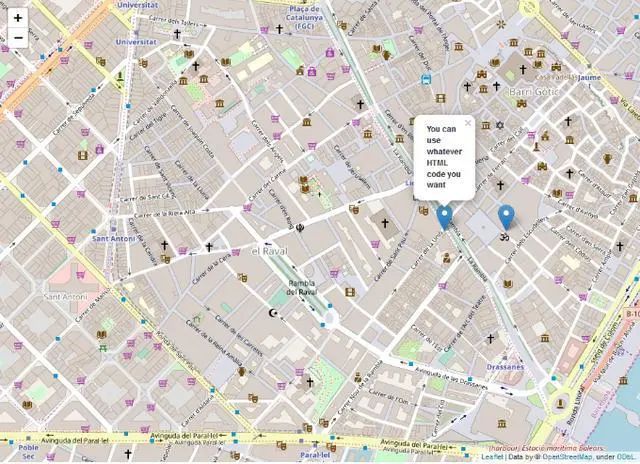
你可以看到交互式地图文件,可以在其中单击标记。
在开头提供的数据集中,我们有国家名称和人工智能术语的流行度。快速可视化后,您会发现有些国家缺少这些值之一。我们将消除这些国家,以使其变得更加容易。然后,我们将使用Geopandas将国家/地区名称转换为可在地图上绘制的坐标。
from geopandas.tools import geocodedf2 = pd.read_csv('mapa.csv')df2.dropna(axis=0, inplace=True)df2['geometry'] = geocode(df2['País'], provider='nominatim')['geometry'] #It may take a while because it downloads a lot of data.df2['Latitude'] = df2['geometry'].apply(lambda l: l.y)df2['Longitude'] = df2['geometry'].apply(lambda l: l.x)
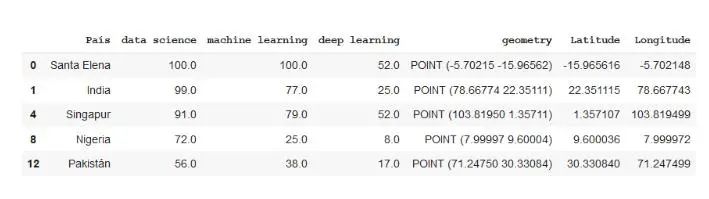
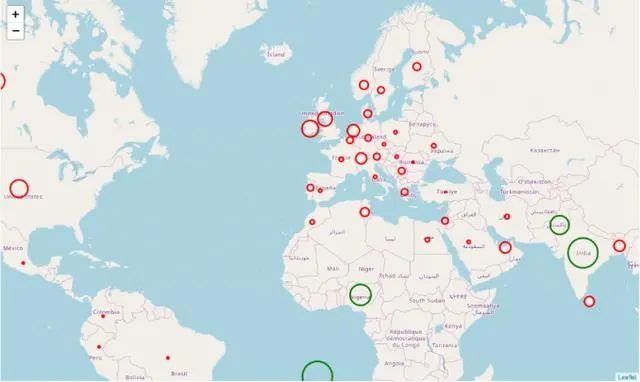
现在,我们已经按照纬度和经度对数据进行了编码,现在让我们在地图上进行表示。我们将从BubbleMap开始,在其中绘制各个国家的圆圈。它们的大小将取决于该术语的受欢迎程度,而颜色将是红色或绿色,具体取决于它们的受欢迎程度是否超过某个值。
m3 = folium.Map(location=[39.326234,-4.838065], tiles='openstreetmap', zoom_start=3)def color_producer(val): if val <= 50: return 'red' else: return 'green'for i in range(0,len(df2)): folium.Circle(location=[df2.iloc[i]['Latitud'], df2.iloc[i]['Longitud']], radius=5000*df2.iloc[i]['data science'], color=color_producer(df2.iloc[i]['data science'])).add_to(m3)m3.save('map3.html')
在何时使用哪个库?
有了各种各样的库,您可能想知道哪个库最适合您的项目。快速的答案是让你可以轻松制作所需图形的库。
对于项目的初始阶段,使用Pandas和Pandas分析,我们将进行快速可视化以了解数据。如果需要可视化更多信息,可以使用在matplotlib中可以找到的简单图形作为散点图或直方图。
对于项目的高级阶段,我们可以在主库(Matplotlib,Seaborn,Bokeh,Altair)的图库中搜索我们喜欢并适合该项目的图形。这些图形可用于在报告中提供信息,制作交互式报告,搜索特定值等。
推荐阅读
利用 Python 进行多 Sheet 表合并、多工作簿合并、一表按列拆分
Python 自动化办公之"你还在手动操作“文件”或“文件夹”吗?"
数据分析之AB testing实战(附Python代码)
“罗永浩抖音首秀”销售数据的可视化大屏是怎么做出来的呢?
情人节,不懂送女朋友什么牌子的口红?没关系!Python 数据分析告诉你。
利用 Python 爬取了 13966 条运维招聘信息,我得出了哪些结论?
利用 Python 爬取了 37483 条上海二手房信息,我得出的结论是?
总说手机没有“好壁纸”,Python一次性抓取500张“美女”图片,够不够用!
看了这个总结,其实 Matplotlib 可视化,也没那么难!
这几个用 Pyecharts 做出来的交互图表,领导说叼爆了!
Python 爬取链家成都二手房源信息 asyncio + aiohttp 异步爬虫实战
点个[在看],是对杰哥最大的支持!
本文分享自微信公众号 - 杰哥的IT之旅(Jake_Internet)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












