云妹导读:
所谓写确认,是指用户将数据写入数据库之后,数据库告知用户写入成功的一个概念。根据数据库的特点和配置,可以在不同的写入程度上,返回给用户,而这其中,就涉及到了不同的性能、数据安全等级以及数据一致性的内容。
不同的写入确认级别或配置,是数据库提供给用户的一种自我控制的能力,用户可以针对自身业务的特点、数据管理的需要、性能的考虑、数据一致性以及服务可用性各种因素进行考虑,选择适合的数据库配置,来实现自身的需要。
首先介绍几个重要的概念,这些概念也是数据库中常识性的知识了,不过是在不同数据库的不同表述。
这些概念主要涉及到写确认的两个重要考量点,一个是本地数据库写操作的不丢失,一个是分布式环境下,数据冗余的一致性。
本地数据库写操作是指数据库在处理用户的写操作后,能够持续化,防止因为意外导致的数据丢失,这个主要涉及到日志,比如MySQL中的redo log和MongoDB中的journal日志。
数据冗余的一致性是指多副本的环境下,比如主从或复制集架构下,数据写入主节点后,如何实现从节点与主节点的数据一致,而主从之间是以另外一个日志实现数据同步的,比如MySQL的binlog和MongoDB中的oplog日志。
另外防止主节点崩溃,数据未能同步到从节点,导致从节点成为新的主节点后,未同步数据丢失,也是写确认中重要的内容,即不但同步数据,而且要让数据安全快速的同步。
redo/journal
MySQL的redo log和MongoDB的journal日志都是数据库存储引擎层面的WAL(Write-Ahead Logging)预写式日志,记录的是数据的物理修改,是提高数据系统持久性的一种技术。
redo log
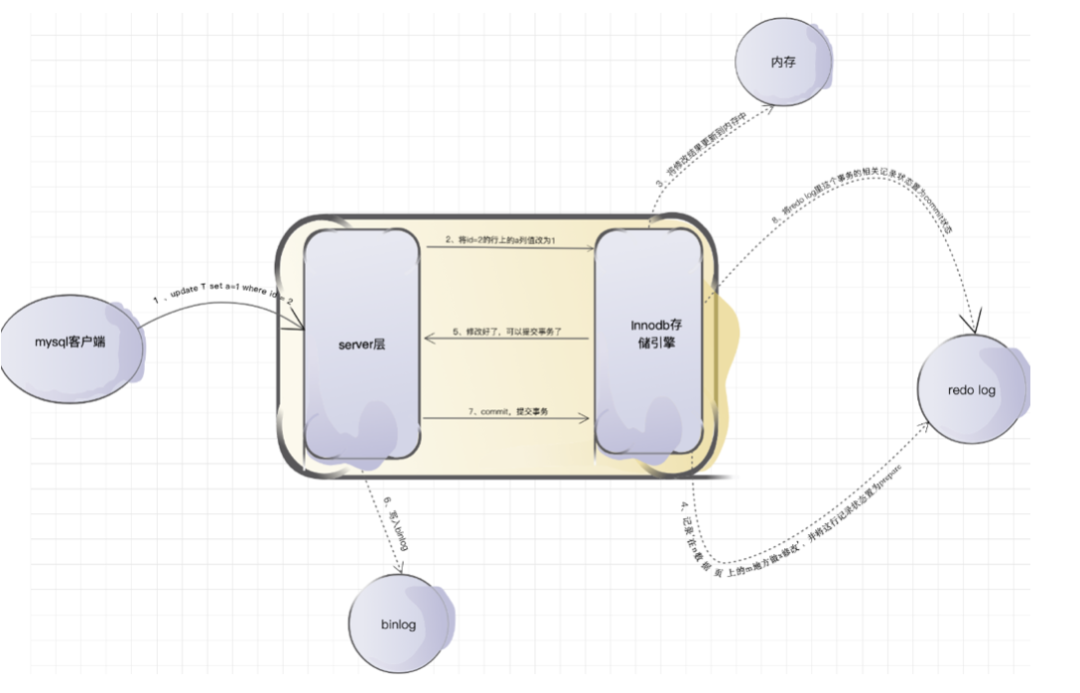
redo log是MySQL的默认存储引擎innodb事务日志中的核心日志文件之一,俗称重做日志,主要用作前滚的数据恢复。
当我们想要修改MySQL数据库中某一行数据的时候,innodb是把数据从磁盘读取到内存的缓冲池上进行修改。这个时候数据在内存中被修改,与磁盘中相比就存在了差异,我们称这种有差异的数据为脏页。innodb对脏页的处理不是每次生成脏页就将脏页刷新回磁盘,这样会产生海量的io操作,严重影响innodb的处理性能,因此并不是每次有了脏页都立刻刷新到磁盘中。既然脏页与磁盘中的数据存在差异,那么如果在这期间数据库出现故障就会造成数据的丢失。
而redo log就是为了解决这个问题。由于redo log的存在,可以延迟刷新脏页到磁盘的时间,保障了数据库性能的情况下提高了数据的安全。虽然增加了redo log刷新的开销,但是由于redo log采用的顺序io,比数据页的随机io要快很多,这额外的开销可接受。
即,数据库先将数据页的物理修改情况写到刷盘较快的redo log文件中,防止数据丢失。一旦发生故障,数据库重启恢复的时候,可以先从redo log把未刷新到磁盘的已经提交的物理数据页恢复回来。
journal
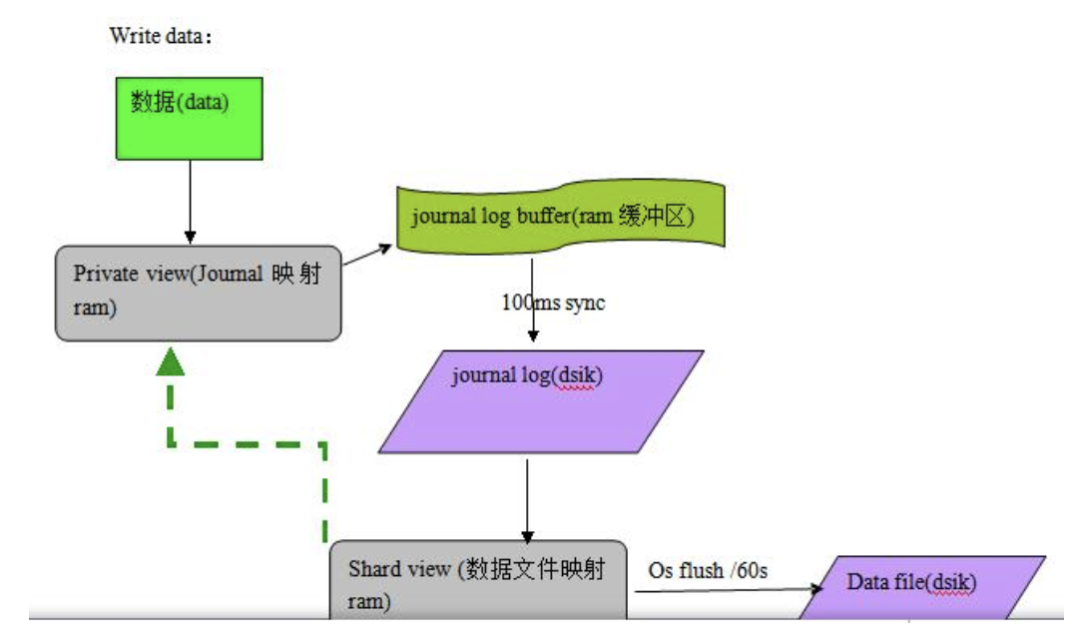
journal是MongoDB存储引擎层面的概念,MongoDB主要支持的mmapv1、wiredtiger、mongorocks等存储引擎,都⽀持配置journal。MongoDB可以基于journal来恢复因为崩溃未及时写到磁盘的信息。
MongoDB 所有的数据写⼊、读取最终都是调存储引擎层的接⼝来存储、读取数据,journal 是存储引擎存储数据时的一种辅助机制。
在MongoDB的4.0版本以前,用户可以设置是否开启journal日志;从4.0版本开始,副本集成员必须开启journal功能。
以wiredtiger为例,如果不配置journal,写入wiredtiger的数据,并不会立即持久化存储;而是每分钟会做一次全量的checkpoint( storage.syncPeriodSecs配置项,默认为1分钟),将所有的数据持久化。如果中间出现宕机,那么数据只能恢复到最近的一次checkpoint,这样最多可能丢掉1分钟的数据。
所以建议「一定要开启journal」,开启journal后,每次写入会记录一条操作日志(通过journal可以重新构造出写入的数据)。这样即使出现宕机,启动时 Wiredtiger 会先将数据恢复到最近的一次checkpoint的点,然后重放后续的 journal操作日志来恢复数据。
binlog/oplog
MySQL的binlog和MongoDB的oplog都是数据库层面的写操作对应的逻辑日志,主要用于实现数据在主备之间的同步复制以及增量备份和恢复。
binlog
binlog是MySQL数据库层面的一种二进制日志,不管底层使用的什么存储引擎,对数据库的修改都会产生这种日志。binlog记录操作的方法是逻辑性语句,可以通过设置log-bin=mysql-bin来启动该功能。
binlog中记录了有关写操作的执行时间、操作类型、以及操作的具体内容,比如SQL语句(statement)或每行实际数据的变更(row)。
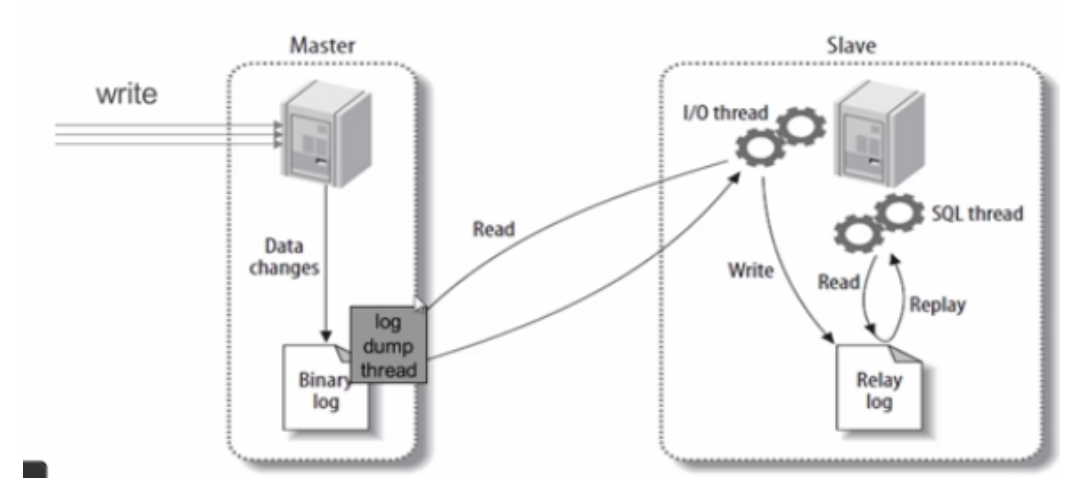
上图是MySQL主从之间是如何实现数据复制的,其中的三个重要过程是:
- 主库(Master)把数据库更改记录到binlog(图中的Binary Log)中;
- 备库(Slave)将主库上的binlog复制到自己的中继日志(Relay log)中;
- 备库读取中继日志中的事件,将其重放(Replay)到备库数据之上。
这样源源不断的复制,实现了数据在数据库节点之间的一致。
oplog
oplog是MongoDB数据库层面的概念,在复制集架构下,主备节点之间通过oplog来实现节点间的数据同步。Primary中所有的写入操作都会记录到MongoDB Oplog中,然后从库会来主库一直拉取Oplog并应用到自己的数据库中。这里的Oplog是MongoDB local数据库的一个集合,它是Capped collection,通俗意思就是它是固定大小,循环使用的。
oplog 在 MongoDB 里是一个普通的 capped collection,对于存储引擎来说,oplog只是一部分普通的数据而已。
只有按复制集架构启动的节点会自动在local库中创建oplog.rs的集合。
oplog中记录了有关写操作的操作时间、操作类型、以及操作的具体内容,几乎保留的每行实际数据的变更(在4.0及以后版本中,一个事务中涉及的多个文档,会写在一条oplog中)。
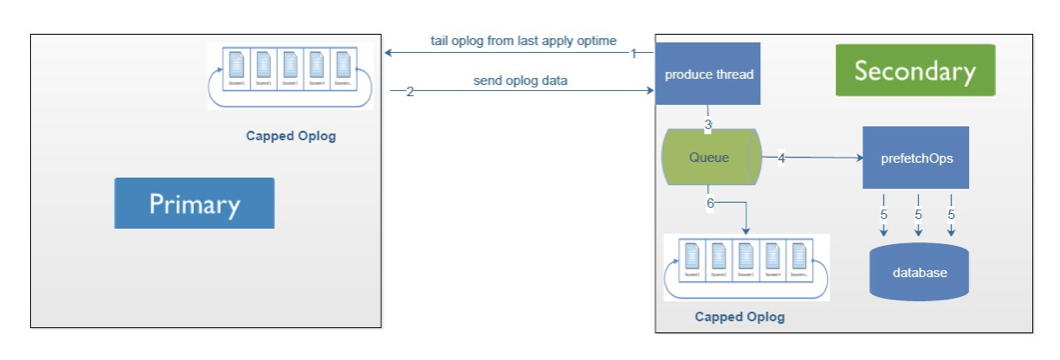
上图是MongoDB主备之间如何实现数据复制的,其中的四个重要过程是:
- 主库(Primary)把数据库更改记录到oplog(图中的Capped Oplog集合)中;
- 备库(Secondary)把主库上的oplog拉取到自己的回放队列中(Queue)中;
- 备库读取队列中的oplog,批量回放(applyOps)到备库数据中;
- 再将队列中的Oplog写入到备库中的oplog.rs集合中。
这样源源不断的复制,实现了数据在数据库节点之间的一致。
另外MongoDB支持链式复制,即oplog不一定从Primary中获取,还可以从其他Secondary获取。上图是MongoDB主备之间如何实现数据复制的,其中的四个重要过程是:
- 主库(Primary)把数据库更改记录到oplog(图中的Capped Oplog集合)中;
- 备库(Secondary)把主库上的oplog拉取到自己的回放队列中(Queue)中;
- 备库读取队列中的oplog,批量回放(applyOps)到备库数据中;
- 再将队列中的Oplog写入到备库中的oplog.rs集合中。
这样源源不断的复制,实现了数据在数据库节点之间的一致。
另外MongoDB支持链式复制,即oplog不一定从Primary中获取,还可以从其他Secondary获取。
redo与binlog
- redo log是在innodb存储引擎层产生,而binlog是MySQL数据库的上层产生的,并且binlog不仅仅针对innodb存储引擎,MySQL数据库中的任何存储引擎对于数据库的更改都会产生binlog。
- 两种日志记录的内容形式不同。MySQL的binlog是逻辑日志,其记录是对应的SQL语句或行的修改内容。而innodb存储引擎层面的redo log是物理日志。
- 两种日志与记录写入磁盘的时间点不同,binlog只在事务提交完成后进行一次写入。而innodb存储引擎的redo log在事务进行中不断地被写入,并日志不是随事务提交的顺序进行写入的。
- binlog仅在事务提交时记录,并且对于每一个事务,仅在事务提交时记录,并且对于每一个事务,仅包含对应事务的一个日志。而对于innodb存储引擎的redo log,由于其记录是物理操作日志,因此每个事务对应多个日志条目,并且事务的redo log写入是并发的,并非在事务提交时写入,其在文件中记录的顺序并非是事务开始的顺序。
- binlog不是循环使用,在写满或者重启之后,会生成新的binlog文件,redo log是循环使用。
- binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
journal与oplog
journal日志是在wiretiger、mmapV1等存储引擎层产生,而oplog是MongoDB数据库的主从复制层面的概念,oplog也与存储引擎无关;
两种日志记录的内容形式不同。MongoDB的oplog是逻辑日志,其记录的是对应的写操作的内容。而journal存储的物理修改;
两种日志与记录写入磁盘的时间点不同。
MongoDB 复制集里写入一个文档时,需要修改如下数据
- 将文档数据写入对应的集合
- 更新集合的所有索引信息
- 写入一条oplog用于同步 最终存储引擎会将所有修改操作应用,并将上述3个操作写⼊到一条 journal 操作日志里。
- journal不是循环使用,在写满或者重启之后,会生成新的journal文件,oplog是循环使用;
- oplog可以作为恢复数据使用,复制集架构,journal作为一场宕机或者介质故障后的数据恢复使用。

写确认
写确认这个概念其实是来自于MongoDB中的write concern,描述的是MongoDB对一个写操作的确认(acknowledge)等级。而MySQL中对应的这个概念,可以理解为,用户在提交(commit)写操作的时候,需要经过哪些操作之后就会告知用户提交成功。
MongoDB
在MongoDB中,数据库支持基于write concern功能使用户配置灵活的写入策略,则不同的策略对应不同的数据写入程度即返回给用户写入成功,用户可以继续操作下一个写请求。
write concern
write concern支持3个配置项:
{ w: , j: , wtimeout: }
其中:
- w,该参数要求写操作已经写入到个节点才向用户确认;
- {w: 0} 对客户端的写入不需要发送任何确认,适用于性能要求高,但不关注正确性的场景;
- {w: 1} 默认的writeConcern,数据写入到Primary就向客户端发送确认;
- {w: "majority"} 数据写入到副本集大多数成员后向客户端发送确认,适用于对数据安全性要求比较高的场景,该选项会降低写入性能;
- j,该参数表示是否写操作要进行journal持久化之后才向用户确认;
- {j: true} 要求primary写操作进行了journal持久化之后才向用户确认;
- {j: false} 要求写操作已经在journal缓存中即可向用户确认;journal后续会将持久化到磁盘,默认是100ms;
- wtimeout,该参数表示写入超时时间,w大于1时有效;当w大于1时,写操作需要成功写入若干个节点才算成功,如果写入过程中节点有故障,导致写操作迟迟不能满足w要求,也就一直不能向用户返回确认结果,为了防止这种情况,用户可以设置wtimeout来指定超时时间,写入过程持续超过该时间仍未结束,则认为写入失败。
副本集下的写确认
下面以一个副本集架构来描述,一个写操作的流程,来认识MongoDB下的写确认。
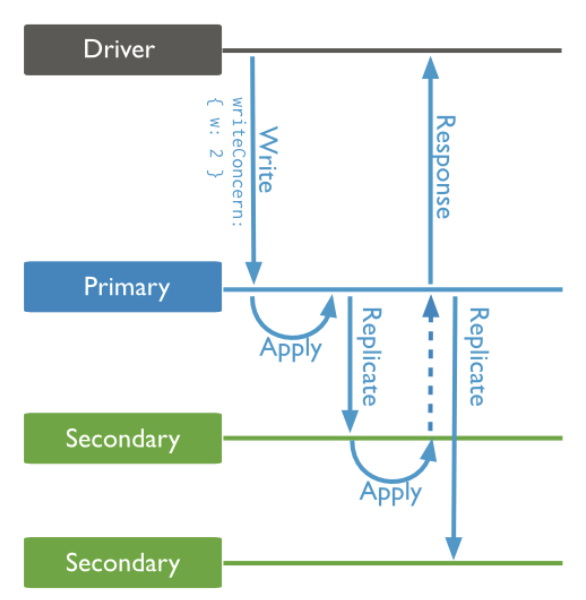
上面这个写操作,{w:2},需要至少两个节点写成功才可以返回给用户写成功;而每个节点的写入成功可以基于参数{j}来判断,如果{j:true},则每个节点写入操作的journal都刷盘才可以;如果{j:false},则写入操作的journal在缓存中即可以返回成功;
另外,MongoDB的Primary如何知道Secondary是否已经同步成功呢,是基于如下流程:
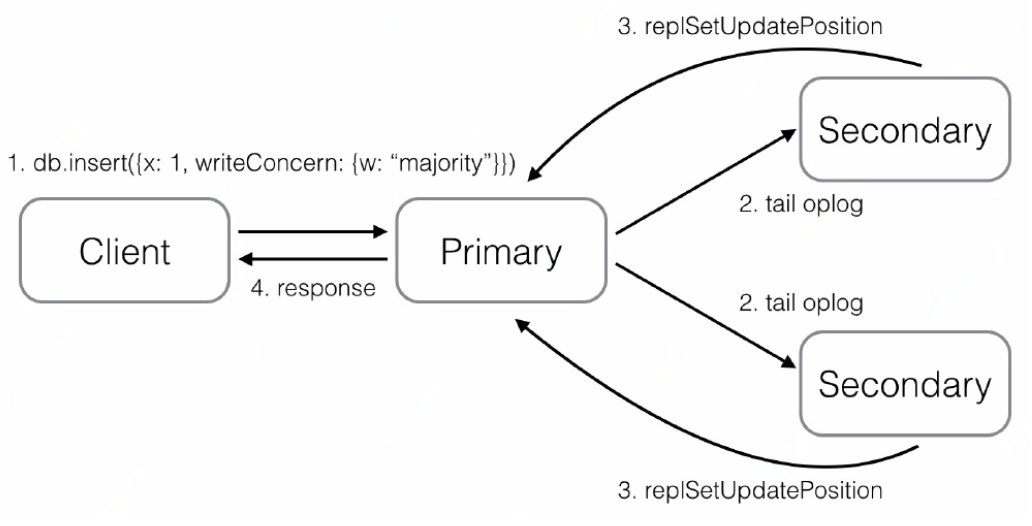
- Client向Primary发起请求,指定writeConcern为{w: "majority"},Primary收到请求,本地写入并记录写请求到oplog,然后等待大多数节点都同步了这条/批oplog(Secondary应用完oplog会向主报告最新进度);
- Secondary拉取到Primary上新写入的oplog,本地重放并记录oplog。为了让Secondary能在第一时间内拉取到主上的oplog,find命令支持一个awaitData的选项,当find没有任何符合条件的文档时,并不立即返回,而是等待最多maxTimeMS(默认为2s)时间看是否有新的符合条件的数据,如果有就返回;所以当新写入oplog时,备立马能获取到新的oplog;
- Secondary上有单独的线程,当oplog的最新时间戳发生更新时,就会向Primary发送replSetUpdatePosition命令更新自己的oplog时间戳;
- 当Primary发现有足够多的节点oplog时间戳已经满足条件了,向客户端发送确认,这样,Primary即可知道数据已经同步到了。
MySQL
MySQL数据库在所谓写确认或写成功方面可以通过执行事务的commit提交来体现,提交成功则为写成功。因此我主要从事务在执行事务以及commit事务的过程中,涉及的redo log、binlog以及两种日志的刷盘和主从复制的流程来分析MySQL的写成功相关的设置和问题。
MySQL复制架构
目前MySQL较为流量的版本包括5.5、5.6、5.7、8.0,而8.0版本中使用的Group Replication来实现多节点的数据一致性,这种组复制依靠分布式一致性协议(Paxos协议的变体),实现了分布式下数据的最终一致性。
MySQL中有几种常见复制机制:
- 同步复制。当主库提交事务之后,所有的从库节点必须收到、Replay并且提交这些事务,然后主库线程才能继续做后续操作。但缺点是,主库完成一个事务的时间会被拉长,性能降低。
- 异步复制。主库将事务 Binlog 事件写入到 Binlog文件中,此时主库只会通知一下 Dump 线程发送这些新的Binlog,然后主库就会继续处理提交操作,而此时不会保证这些 Binlog 传到任何一个从库节点上。
- 半同步复制。是介于全同步复制与全异步复制之间的一种,主库只需要等待至少一个从库节点收到并且 Flush Binlog 到 Relay Log 文件即可,主库不需要等待所有从库给主库反馈。同时,这里只是一个收到的反馈,而不是已经完全完成并且提交的反馈,如此,节省了很多时间。
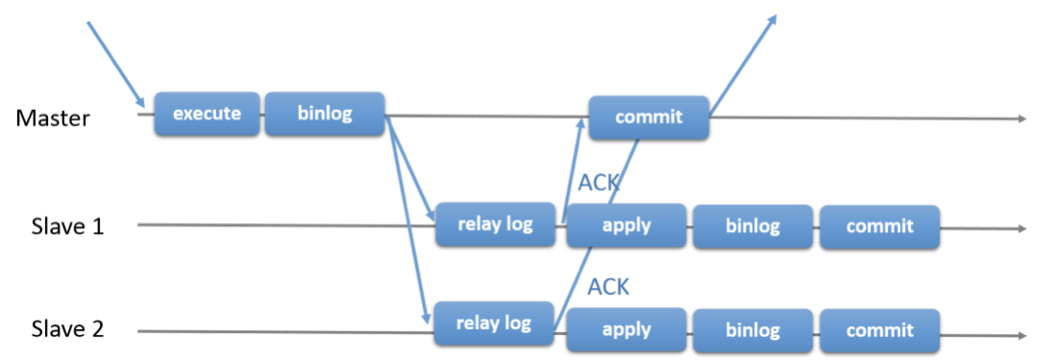
- 组复制。由若干个节点共同组成一个复制组,一个事务的提交,必须经过组内大多数节点(N / 2 + 1)决议并通过,才能得以提交。比如由3个节点组成一个复制组,Consensus层为一致性协议层,在事务提交过程中,发生组间通讯,由2个节点决议(certify)通过这个事务,事务才能够最终得以提交并响应。
除了组复制,半同步复制技术是性能和安全相对更好的设计,尤其在5.7版本中,优化了之前版本的半同步复制相关的逻辑,因此我们主要以5.7版本来介绍。
MySQL5.6/5.5半同步复制的原理:提交事务的线程会被锁定,直到至少一个Slave收到这个事务,由于事务在被提交到存储引擎之后才被发送到Slave上,所以事务的丢失数量可以下降到最多每线程一个。因为事务是在被提交之后才发送给Slave的,当Slave没有接收成功,并且Master挂了,会导致主从不一致:主有数据,从没有数据。这个被称为AFTER_COMMIT。
MySQL5.7在Master事务提交的时间方面做了改进,事务是在提交之前发送给Slave(AFTER_SYNC),当Slave没有接收成功,并且Master宕机了,不会导致主从不一致,因为此时主还没有提交,所以主从都没有数据。
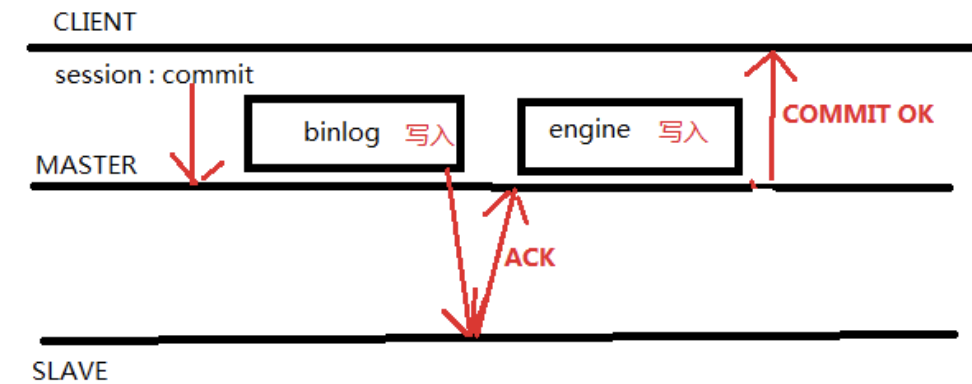
不过假如Slave接收成功,并且Master中的binlog未来得及刷盘并且在存储引擎提交之前宕机了,那么很明显这个事务是不成功的,但由于对应的Binlog已经做了Sync操作,从库已经收到了这些Binlog,并且执行成功,相当于在从库上多了数据,也算是有问题的,但多了数据,问题一般不算严重。此时可能就需要8.0版本中的组复制了。
MySQL写确认行为
我们以MySQL的5.7版本的半同步复制的主从架构的为例子,来介绍MySQL各个参数对写确认即commit的不同影响。
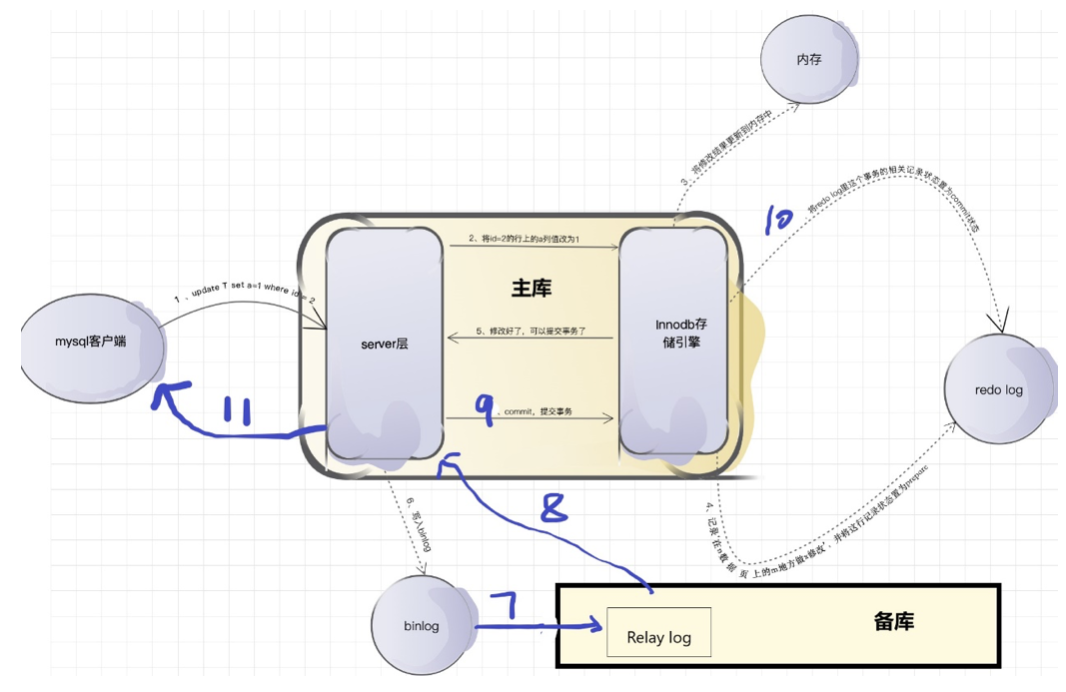
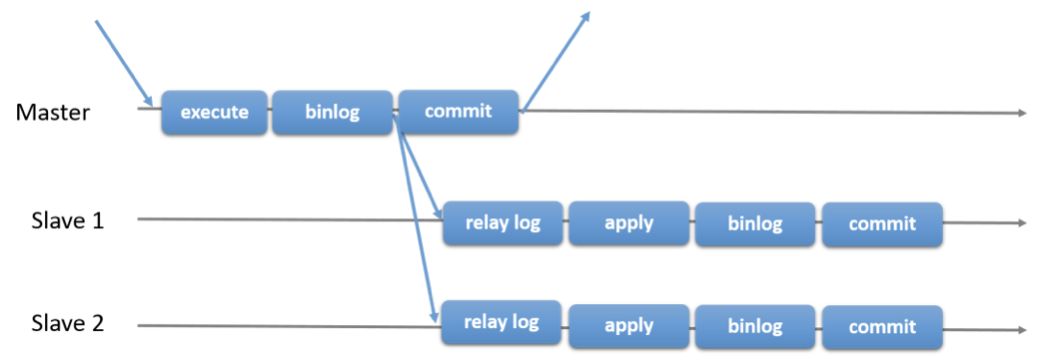
上图中,能够体现半同步复制(AFTER SYNC)的过程为:
- 第6步,写binlog;(sync_binlog参数在此起作用)
- 第7步,同步binlog到备库的Relay log;(sync_relay_log参数在此起作用)
- 第8步,返回给主库ack;
- 第9步和第10步,提交事务,将redo log中该事务标记为已提交;(innodb_flush_log_at_trx_commit参数在此起作用)
- 第11步,返回给用户写成功;
上图中,能体现redo log和binlog顺序一致性的过程为:
- 第4步,将redo log置为prepare并刷盘;
- 第6步,写入binlog;(sync_binlog参数在此起作用)
- 第9步和第10步,提交事务,并将redo log置为提交状态;
下面将把上面介绍的与刷盘有关的配置项引入这整个过程,来看写操作不同的行为和风险。

注意:以上是在开始内部两阶段提交的流程,即innodb_support_xa=true,这个时候可以通过判断binlog来恢复会提交的事务,因此innodb_flush_log_at_trx_commit看起来可有可无;如果未开启内部事务的两阶段提交,则更会复杂,只有innodb_flush_log_at_trx_commit = 1 且 sync_binlog = 1 且 sync_relay_log = 1的情况下,可以保证已提交事务的安全,其他情况都有可能导致数据丢失或者主从数据不一致的风险。
但是在innodb_flush_log_at_trx_commit = 1 且 sync_binlog = 1 且 sync_relay_log = 1 的情况下,MySQL的性能相对最低。可以在提高性能的情况下,比如 innodb_flush_log_at_trx_commit = 2 且 sync_binlog = N (N为500 或1000),由于这种情况,redo log和binlog都在系统缓存中,可以使用带蓄电池后备电源的缓存cache,防止系统断电异常。
此外,rpl_semi_sync_master_wait_for_slave_count参数是控制同步到多少个节点的,类似MongoDB中write concern中的 w 参数,如果这个参数设置为0(其实不能,最低1),则变为了纯粹的异步复制;如果这个参数设置为最大(所有从节点个数),则变为了纯粹的同步复制,因此这个地方也可以根据需要来进行调整,来提交数据的安全。
同时,有可能影响同步模式的还包括rpl_semi_sync_master_wait_no_slave参数、影响复制等待超时的参数rpl_semi_sync_master_timeout等。当rpl_semi_sync_master_wait_no_slave为OFF时,只要master发现Rpl_semi_sync_master_clients小于rpl_semi_sync_master_wait_for_slave_count,则master立即转为异步模式;如果为ON时,如果在事务提交阶段(master等待ACK)超时rpl_semi_sync_master_timeout,master会转为异步模式。
对比
配置比较

其他
虽然MongoDB和MySQL在很多方面可以有类似或相似的设置,但是还是存在一些区别,比如:
- MongoDB的journal中包含了oplog的信息;而binlog和redo log是两个相对独立的内容;
- MySQL几乎所有的写操作都是基于事务来提交的;而MongoDB在4.0开始支持多文档的事务,单文档的事务基于内部事务逻辑实现,未直接提供给用户;
- MySQL的写确认是已commit提交成功为标志,MongoDB的普通写操作是返回写入成功为标志;事务写操作也是已commit为标志;
总结
本文章所介绍的写确认的概念,涉及到了MongoDB与MySQL的日志文件(redo log/journal)、同步用日志(binlog/oplog)、刷盘机制和时机、主从同步架构等多个流程和模块,目的就是实现写操作的原子性、持久性、分布式环境下的数据一致性等,对数据的性能和安全都有影响,需要根据数据、业务、压力、安全等客观因素去调整。
由于涉及的内容非常多,未对所有的情况进行测试验证,可能有疏漏或错误,希望大家不吝赐教。也希望本篇内容对于对MySQL和MongoDB都有兴趣的同学可以作为一个总结和参考。
参考资料
高性能MySQL(https://item.jd.com/11220393.html)
MongoDB官方手册(https://docs.mongodb.com/manual/)
深入浅出MongoDB复制(https://mongoing.com/archives/5200)
mysql基于binlog的复制(https://blog.csdn.net/u012548016/article/details/86584293)
MongoDB journal 与 oplog,究竟谁先写入?(https://mongoing.com/archives/3988)
MySQL5.7新特性--官方高可用方案MGR介绍(https://www.cnblogs.com/luoahong/articles/8043035.html)
MongoDB writeConcern原理解析(https://mongoing.com/archives/2916)
mysql日志系统之redo log和bin log(https://www.jianshu.com/p/4bcfffb27ed5)
MySQL 5.7 半同步复制增强【转】(https://www.cnblogs.com/mao3714/p/8777470.html)
MySQL 中Redo与Binlog顺序一致性问题 【转】(https://www.cnblogs.com/mao3714/p/8734838.html)
详细分析MySQL事务日志(redo log和undo log)(https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html)
MySQL 的"双1设置"-数据安全的关键参数(案例分享)(https://www.cnblogs.com/kevingrace/p/10441086.html)
rpl_semi_sync_master_wait_no_slave 参数研究实验(https://www.cnblogs.com/konggg/p/12205505.html)
MySQL5.7新特性半同步复制之AFTER_SYNC/AFTER_COMMIT的过程分析和总结(http://blog.itpub.net/15498/viewspace-2143986/)
以上,Enjoy~
点击【阅读】,可了解更多数据库相关详请