点击蓝色字体“肉眼品世界”,关注公众号
深度价值体系传递

当集群中有新成员加入,或者某些主题增加了分区之后,消费者是怎么进行重新分配分区再进行消费的?这里就涉及到重平衡(Rebalance)的概念,下面我就给大家讲解一下什么是 Kafka 重平衡机制,我尽量做到图文并茂通俗易懂。
重平衡的作用
重平衡跟消费组紧密相关,它保证了消费组成员分配分区可以做到公平分配,也是消费组模型的实现,消费组模型如下:
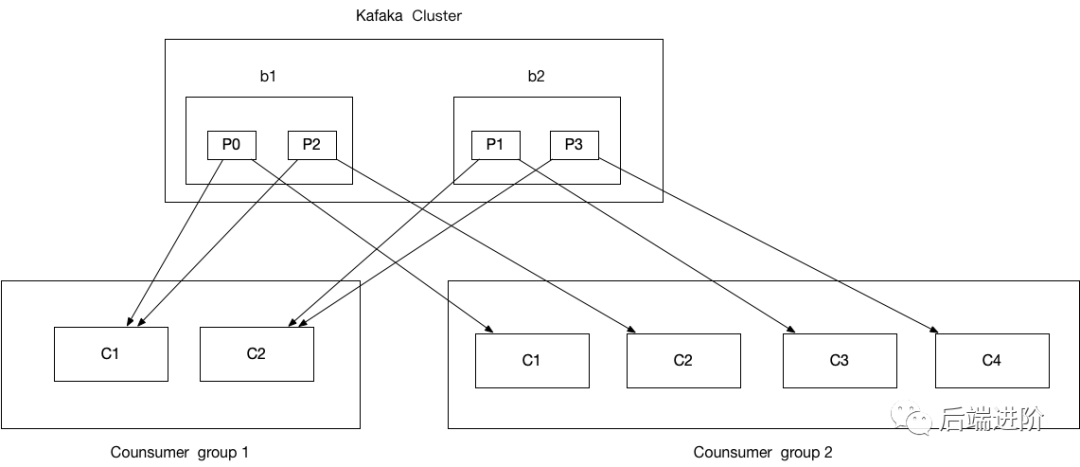
从图中可以找到消费组模型的几个概念:
1.同一个消费组,一个分区只能被一个消费者订阅消费,但一个消费者可订阅多个分区,也即是每条消息只会被同一个消费组的某一个消费者消费,确保不会被重复消费;2.一个分区可被不同消费组订阅,这里有种特殊情况,加入每个消费组只有一个消费者,这样分区就会广播到所有消费者上,实现广播模式消费。
要想实现以上消费组模型,那么就要实现当外部环境变化时,比如主题新增了分区,消费组有新成员加入等情况,实现动态调整以维持以上模型,那么这个工作就会交给 Kafka 重平衡机制去处理。
Kafka与RocketMQ的重平衡区别
Kafka 重平衡机制的一些实现相比 RocketMQ 还是有些区别的,但最终的目的还是都是一样,就是保证分区(RocketMQ 是队列)公平分配且只能被一个消费者订阅(同一个消费组)。
Kafka 重平衡:
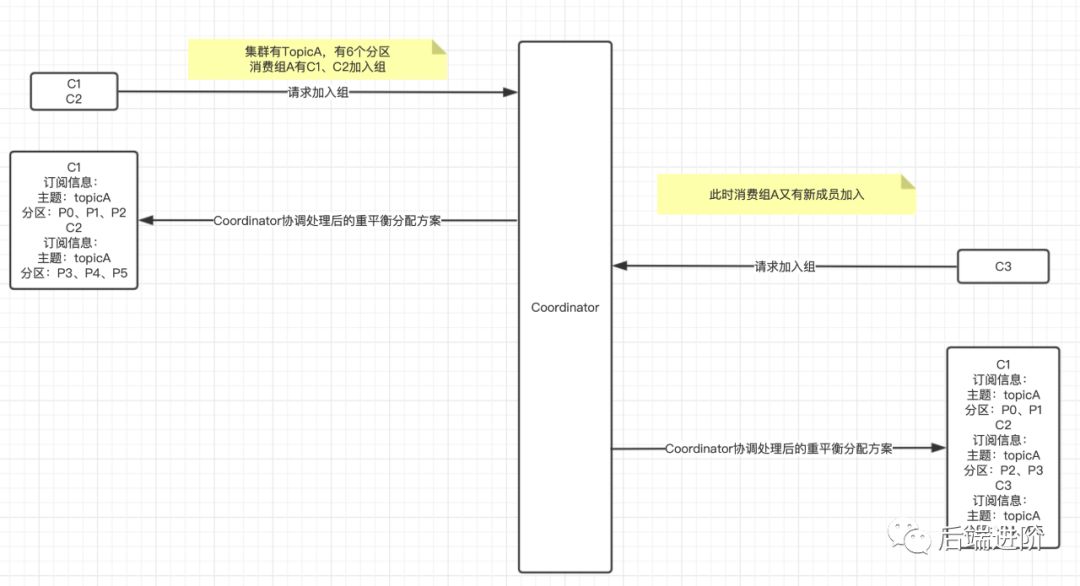
从图中可看出,Kafka 重平衡是外部触发导致的,触发 Kafka 重平衡的有以下几种情况:
1.消费组成员发生变更,有新消费者加入或者离开,或者有消费者崩溃;2.消费组订阅的主题数量发生变更;3.消费组订阅的分区数发生变更。
每个消费者都会跟 Coordinator 保持心跳,当以上情况发生时,心跳响应就会包含 REBALANCE_IN_PROGRESS 命令,消费者停止消费,加入到重平衡事件当中。
RocketMQ重平衡:
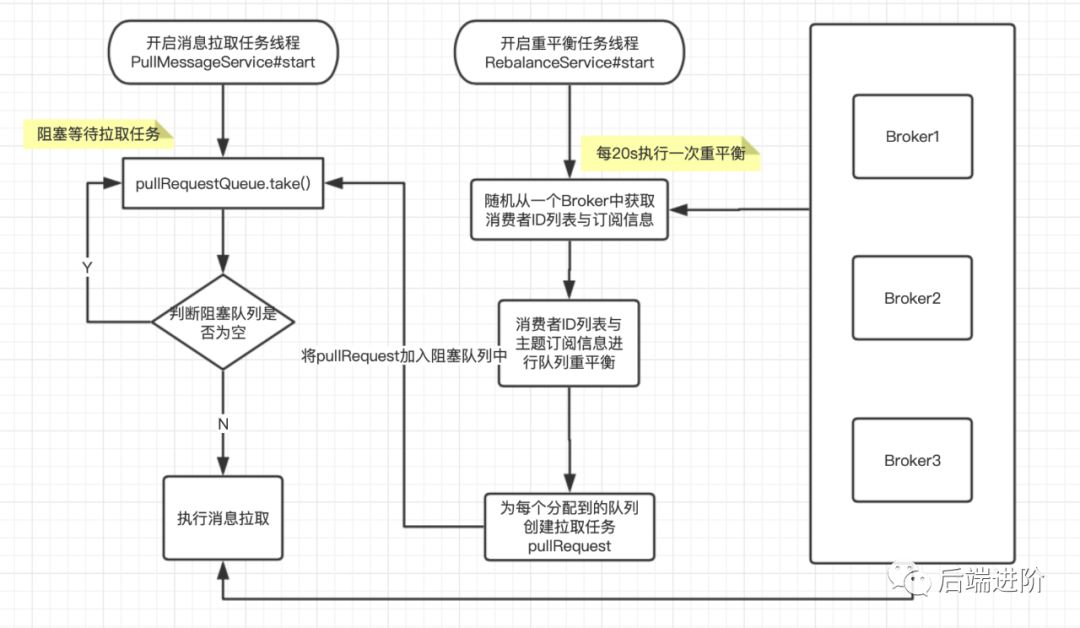
RocketMQ 消费者启动时,会开启两条线程,一条线程执行拉取消息任务,另一条线程者则定时执行重平衡任务,从图中可看出拉取消息线程会从 pullRequestQueue 中取出拉取任务,pullRequestQueue 是一个阻塞队列,意味着当 pullRequestQueue 队列中元素为空时,会一直阻塞,直到有新的拉取任务,那么如果添加新的任务到阻塞队列中去呢?这时 RocketMQ 的重平衡作用就来了,它会每隔 20s 从任意一个 Broker 节点获取消费组的消费 ID 以及订阅信息,再根据这些订阅信息进行分配,然后将分配到的信息封装成 pullRequest 对象 pull 到 pullRequestQueue 队列中,拉取线程唤醒后执行拉取任务。
重平衡所涉及的参数
在消费者启动时,某些参数会影响重平衡机制的发生,所以需要根据业务的属性,对这些参数进行调优,否则可能会因为设置不当导致频繁重平衡,严重影响消费速度,下面跟大家说说这几个参数的一些要点:
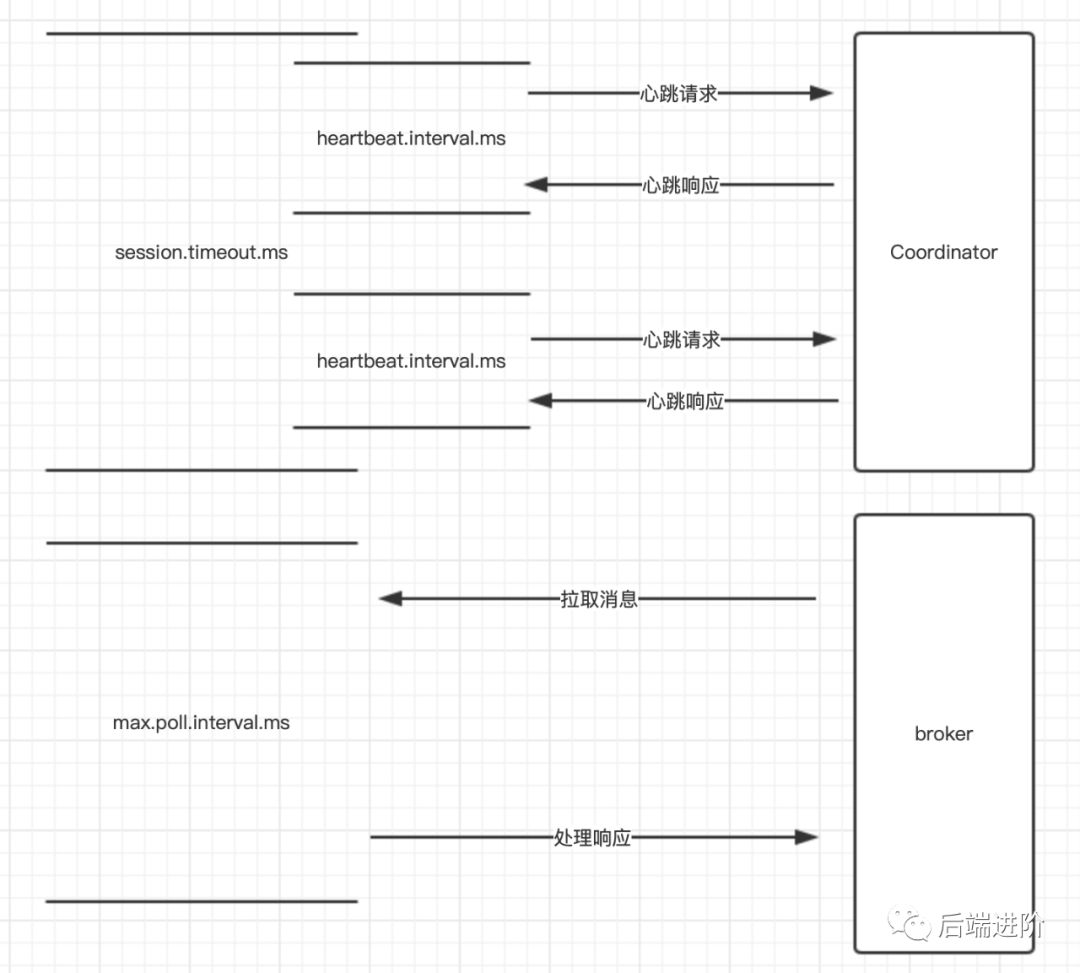
•session.timeout.ms
该参数是 Coordinator 检测消费者失败的时间,即在这段时间内客户端是否跟 Coordinator 保持心跳,如果该参数设置数值小,可以更早发现消费者崩溃的信息,从而更快地开启重平衡,避免消费滞后,但是这也会导致频繁重平衡,这要根据实际业务来衡量。
•max.poll.interval.ms
消费者处理消息逻辑的最大时间,对于某些业务来说,处理消息可能需要很长时间,比如需要 1分钟,那么该参数就需要设置成大于 1分钟的值,否则就会被 Coordinator 剔除消息组然后重平衡。
•heartbeat.interval.ms
该参数跟 session.timeout.ms 紧密关联,前面也说过,只要在 session.timeout.ms 时间内与 Coordinator 保持心跳,就不会被 Coordinator 剔除,那么心跳间隔的时间就是 session.timeout.ms,因此,该参数值必须小于 session.timeout.ms,以保持 session.timeout.ms 时间内有心跳。
下面我用图来形象表达这三个参数的含义:
重平衡流程
在新版本中,消费组的协调管理已经依赖于 Broker 端某个节点,该节点即是该消费组的 Coordinator, 并且每个消费组有且只有一个 Coordinator,它负责消费组内所有的事务协调,其中包括分区分配,重平衡触发,消费者离开与剔除等等,整个消费组都会被 Coordinator 管控着,在每个过程中,消费组都有一个状态,Kafka 为消费组定义了 5 个状态,如下:
1.Empty:消费组没有一个活跃的消费者;2.PreparingRebalance:消费组准备进行重平衡,此时的消费组可能已经接受了部分消费者加入组请求;3.AwaitingSync:全部消费者都已经加入组并且正在进行重平衡,各个消费者等待 Broker 分配分区方案;4.Stable:分区方案已经全部发送给消费者,消费者已经在正常消费;5.Dead:该消费组被 Coordinator 彻底废弃。
可以看出,重平衡发生在 PreparingRebalance 和 AwaitingSync 状态机中,重平衡主要包括以下两个步骤:
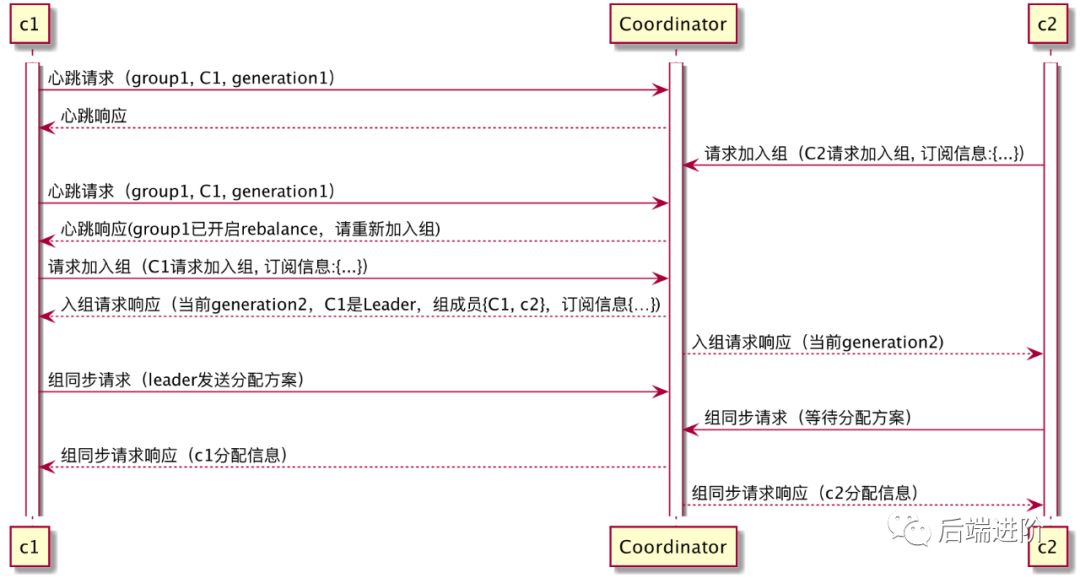
1.加入组(JoinGroup):当消费者心跳包响应 REBALANCE_IN_PROGRESS 时,说明消费组正在重平衡,此时消费者会停止消费,并且发送请求加入消费组;2.同步更新分配方案:当 Coordinator 收到所有组内成员的加入组请求后,会选出一个consumer Leader,然后让consumer Leader进行分配,分配完后会将分配方案放入SyncGroup请求中发送会Coordinator,Coordinator根据分配方案发送给每个消费者。
重平衡场景举例
根据重平衡触发的条件,重平衡的工作流程大概有以下几种类型:
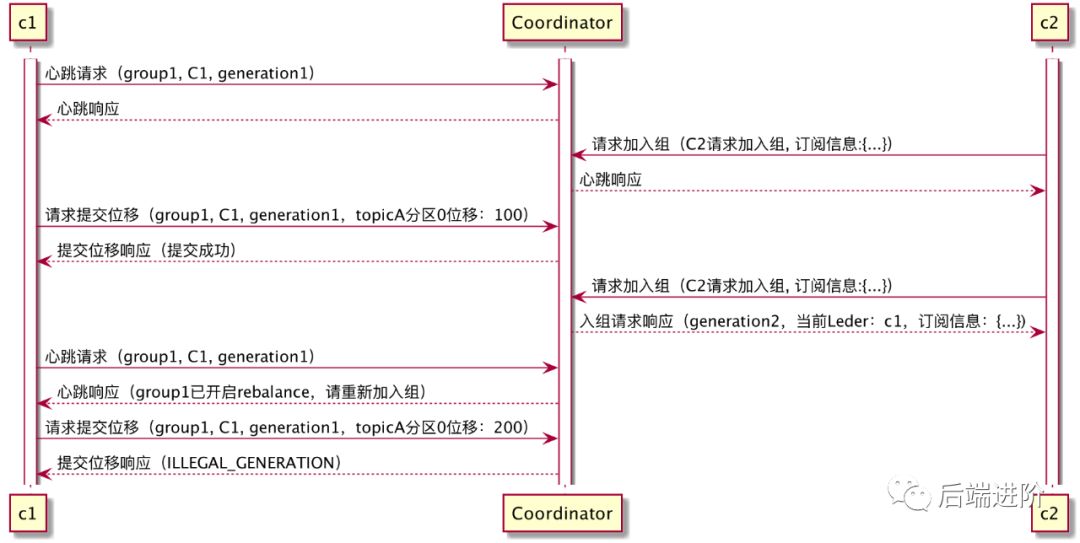
有新的成员加入消费组:
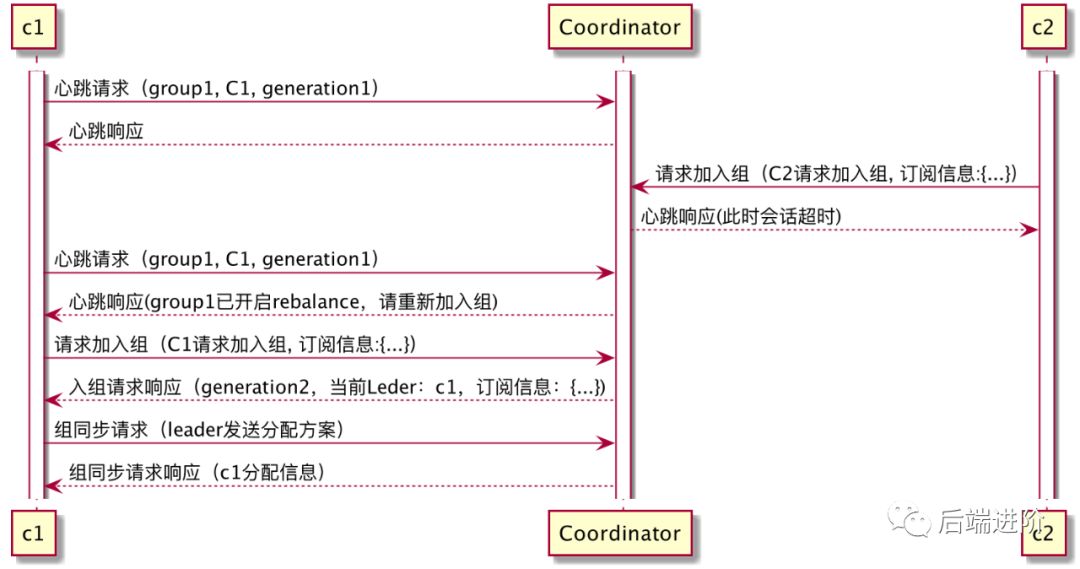
消费组成员崩溃:
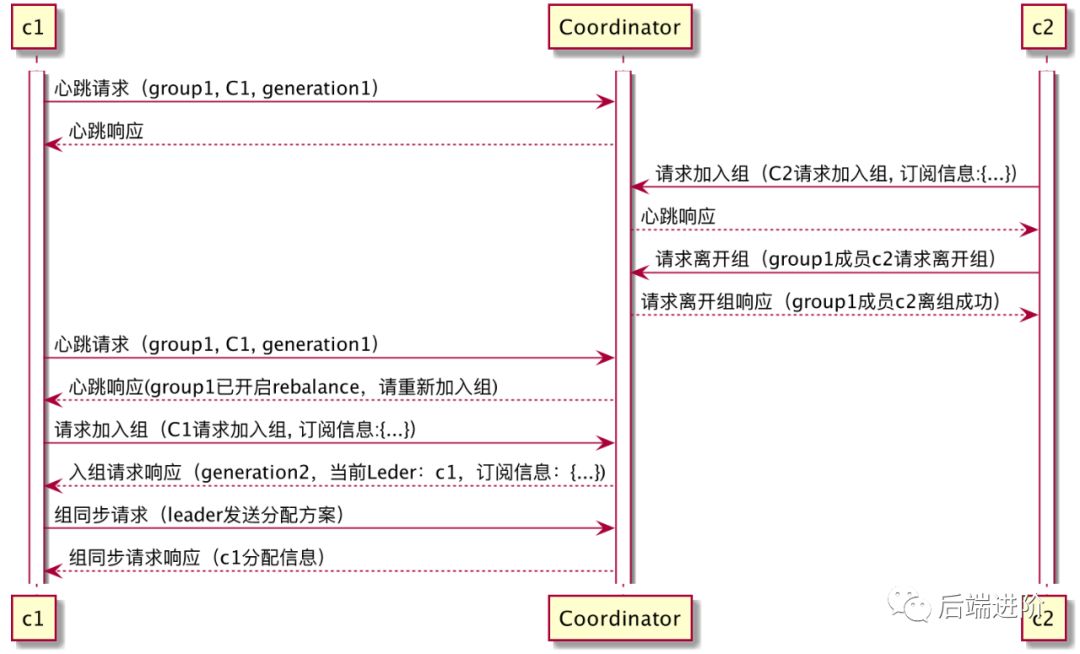
消费组成员主动离开:
消费组成员提交位移时:
本文分享自微信公众号 - 肉眼品世界(find_world_fine)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。