
Namespace 的概念
Linux Namespace 是kernel 的一个功能,它可以隔离一系列系统的资源,比如PID(Process ID),User ID, Network等等。一般看到这里,很多人会想到一个命令chroot,就像chroot允许把当前目录变成根目录一样(被隔离开来的),Namesapce也可以在一些资源上,将进程隔离起来,这些资源包括进程树,网络接口,挂载点等等。
比如一家公司向外界出售自己的计算资源。公司有一台性能还不错的服务器,每个用户买到一个tomcat实例用来运行它们自己的应用。有些调皮的客户可能不小心进入了别人的tomcat实例,修改或者关闭了其中的某些资源,这样就会导致各个客户之间互相干扰。也许你会说,我们可以限制不同用户的权限,让用户只能访问自己名下的tomcat,但是有些操作可能需要系统级别的权限,比如root。我们不可能给每个用户都授予root权限,也不可能给每个用户都提供一台全新的物理主机让他们互相隔离,因此这里Linux Namespace就派上了用场。使用Namespace, 我们就可以做到UID级别的隔离,也就是说,我们可以以UID为n的用户,虚拟化出来一个namespace,在这个namespace里面,用户是具有root权限的。但是在真实的物理机器上,他还是那个UID为n的用户,这样就解决了用户之间隔离的问题。当然这个只是Namespace其中一个简单的功能。
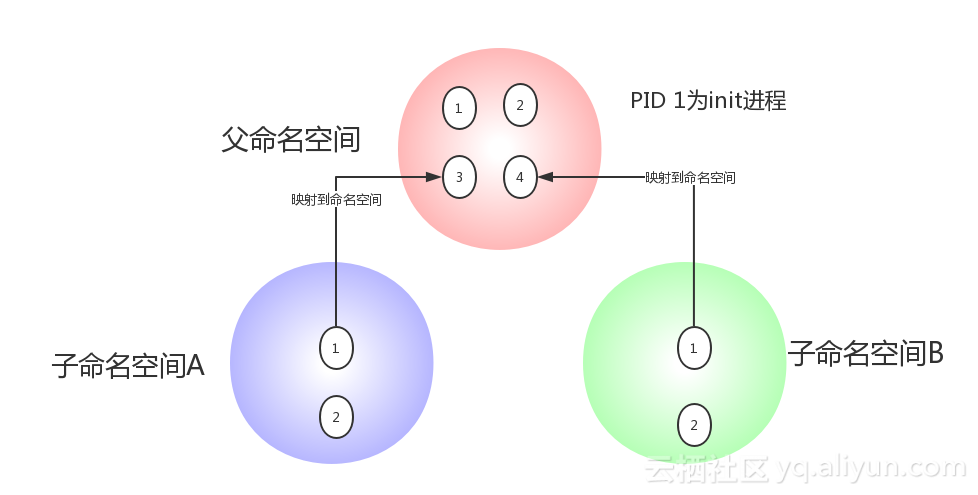
除了User Namespace ,PID也是可以被虚拟的。命名空间建立系统的不同视图, 对于每一个命名空间,从用户看起来,应该像一台单独的Linux计算机一样,有自己的init进程(PID为1),其他进程的PID依次递增,A和B空间都有PID为1的init进程,子容器的进程映射到父容器的进程上,父容器可以知道每一个子容器的运行状态,而子容器与子容器之间是隔离的。从图中我们可以看到,进程3在父命名空间里面PID 为3,但是在子命名空间内,他就是1.也就是说用户从子命名空间 A 内看进程3就像 init 进程一样,以为这个进程是自己的初始化进程,但是从整个 host 来看,他其实只是3号进程虚拟化出来的一个空间而已。
Namespace 是 Linux 内核用来隔离内核资源的方式。通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。
Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
Namespace 的用途
可能绝大多数的使用者和我一样,是在使用 docker 后才开始了解 linux 的 namespace 技术的。实际上,Linux 内核实现 namespace 的一个主要目的就是实现轻量级虚拟化(容器)服务。在同一个 namespace 下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,认为自己置身于一个独立的系统中,从而达到隔离的目的。也就是说 linux 内核提供的 namespace 技术为 docker 等容器技术的出现和发展提供了基础条件。
我们可以从 docker 实现者的角度考虑该如何实现一个资源隔离的容器。比如是不是可以通过 chroot 命令切换根目录的挂载点,从而隔离文件系统。为了在分布式的环境下进行通信和定位,容器必须要有独立的 IP、端口和路由等,这就需要对网络进行隔离。同时容器还需要一个独立的主机名以便在网络中标识自己。接下来还需要进程间的通信、用户权限等的隔离。最后,运行在容器中的应用需要有进程号(PID),自然也需要与宿主机中的 PID 进行隔离。也就是说这六种隔离能力是实现一个容器的基础,让我们看看 linux 内核的 namespace 特性为我们提供了什么样的隔离能力:

上表中的前六种 namespace 正是实现容器必须的隔离技术,至于新近提供的 Cgroup namespace 目前还没有被 docker 采用。相信在不久的将来各种容器也会添加对 Cgroup namespace 的支持。
Namespace 的发展历史
Linux 在很早的版本中就实现了部分的 namespace,比如内核 2.4 就实现了 mount namespace。大多数的 namespace 支持是在内核 2.6 中完成的,比如 IPC、Network、PID、和 UTS。还有个别的 namespace 比较特殊,比如 User,从内核 2.6 就开始实现了,但在内核 3.8 中才宣布完成。同时,随着 Linux 自身的发展以及容器技术持续发展带来的需求,也会有新的 namespace 被支持,比如在内核 4.6 中就添加了 Cgroup namespace。
Linux 提供了多个 API 用来操作 namespace,它们是 clone()、setns() 和 unshare() 函数,为了确定隔离的到底是哪项 namespace,在使用这些 API 时,通常需要指定一些调用参数:CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER、CLONE_NEWUTS 和 CLONE_NEWCGROUP。如果要同时隔离多个 namespace,可以使用 | (按位或)组合这些参数。同时我们还可以通过 /proc 下面的一些文件来操作 namespace。下面就让让我们看看这些接口的简要用法。
查看进程所属的 Namespace
从版本号为 3.8 的内核开始,/proc/[pid]/ns 目录下会包含进程所属的 namespace 信息,使用下面的命令可以查看当前进程所属的 namespace 信息:
$ ll /proc/$$/ns
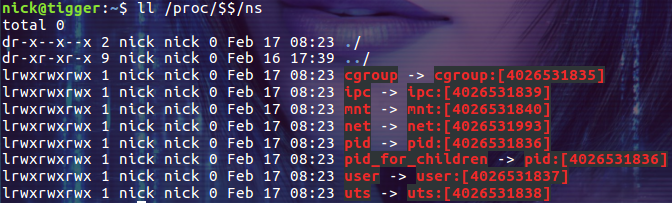
首先,这些 namespace 文件都是链接文件。链接文件的内容的格式为 xxx:[inode number]。其中的 xxx 为 namespace 的类型,inode number 则用来标识一个 namespace,我们也可以把它理解为 namespace 的 ID。如果两个进程的某个 namespace 文件指向同一个链接文件,说明其相关资源在同一个 namespace 中。
其次,在 /proc/[pid]/ns 里放置这些链接文件的另外一个作用是,一旦这些链接文件被打开,只要打开的文件描述符(fd)存在,那么就算该 namespace 下的所有进程都已结束,这个 namespace 也会一直存在,后续的进程还可以再加入进来。
除了打开文件的方式,我们还可以通过文件挂载的方式阻止 namespace 被删除。比如我们可以把当前进程中的 uts 挂载到 ~/uts 文件:
$ touch ~/uts
$ sudo mount --bind /proc/$$/ns/uts ~/uts
使用 stat 命令检查下结果:

很神奇吧,~/uts 的 inode 和链接文件中的 inode number 是一样的,它们是同一个文件。
-----------------------------------------------------------------------------------------------------------------------------------------------
上面是构建Linux容器的namespace技术,它帮进程隔离出自己单独的空间,但Docker又是怎么限制每个空间的大小,保证他们不会互相争抢呢?那么就要用到Linux的Cgroups技术。
Cgroups概念
Cgroups(Control Groups) 是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO等等)的机制。可以对一组进程及将来的子进程的资源的限制、控制和统计的能力,这些资源包括CPU,内存,存储,网络等。通过Cgroups,可以方便的限制某个进程的资源占用,并且可以实时的监控进程的监控和统计信息。最初由google的工程师提出,后来被整合进Linux内核。Cgroups也是LXC为实现虚拟化所使用的资源管理手段,可以说没有cgroups就没有LXC (Linux Container)。
ask:
一个进程
control group:
控制组群,按照某种标准划分的进程组
hierarchy:
层级,control group可以形成树形的结构,有父节点,子节点,每个节点都是一个control group,子节点继承父节点的特定属性。
subsystem:
子系统。
子系统就是资源控制器,每种子系统就是一个资源的分配器,比如cpu子系统是控制cpu时间分配的。
可以使用lssubsys -all来列出系统支持多少种子系统,和使用ls /sys/fs/cgroup/ (ubuntu)来显示已经挂载的子系统:

可以看到这里的几个子系统,比如cpu是控制cpu时间片的,memory是控制内存使用的。
Cgroups可以做什么?
Cgroups最初的目标是为资源管理提供的一个统一的框架,既整合现有的cpuset等子系统,也为未来开发新的子系统提供接口。现在的cgroups适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization)。Cgroups提供了一下功能:
1.限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)。
2.进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定cpu share。
3.记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间
4.进程组隔离(isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
5.进程组控制(control)。比如:使用freezer子系统可以将进程组挂起和恢复。
通过mount -t cgroup命令或进入/sys/fs/cgroup目录,我们看到目录中有若干个子目录,我们可以认为这些都是受 cgroups 控制的资源以及这些资源的信息。
- blkio — 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
- cpu — 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
- cpuacct — 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
- cpuset — 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
- devices — 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
- freezer — 这个子系统挂起或者恢复 cgroup 中的任务。
- memory — 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成内存资源使用报告。
- net_cls — 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
- net_prio — 这个子系统用来设计网络流量的优先级
- hugetlb — 这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
如何为Cgroup分配限制的资源
首先明白下,是先挂载子系统,然后才有control group的。意思就是比如想限制某些进程的资源,那么,我会先挂载memory子系统,然后在memory子系统中创建一个cgroup节点,在这个节点中,将需要控制的进程id写入,并且将控制的属性写入。
1、以memory子系统为例:
进入/sys/fs/cgroup/memory这个目录,我们创建一个test文件夹就相当于创建了一个control group了,进入test目录,你会发现test目录下自动创建了许多文件
这些文件的含义如下:

于是,限制内存使用我们就可以设置memory.limit_in_bytes
将一个进程ID加入到这个test中: echo $$ > tasks
这样就将当前这个终端进程加入到了内存限制的cgroup中了,如果需要删除cgroup只要删除刚创建的目录就可以了。
2、以CPU子系统为例:
跑一个耗费cpu的脚本
x=0
while [ True ];do
x=$x+1
done;
用top命令可以看到这个脚本基本占了100%的cpu资源
下面用cgroups控制这个进程的cpu资源
mkdir -p /sys/fs/cgroup/cpu/hello/ #新建一个控制组hello
echo 50000 > /sys/fs/cgroup/cpu/hello/cpu.cfs_quota_us #将cpu.cfs_quota_us设为50000,相对于cpu.cfs_period_us的100000是50%
echo "$PID" > /sys/fs/cgroup/cpu/hello/tasks
然后观察top的实时统计数据,会发现cpu占用率将近50%,看来cgroups关于cpu的控制起了效果。











