
写在前面
Omi框架在架构设计的时候就决定把update的控制权交给了开发者,视灵活性比生命还重要。不然的话,如果遇到React Fiber要解决的这类问题的话,就需要推翻原有架构重新搞了。
React Fiber
先引用下我们团队小鲜肉Stark伟-复旦大四 / 腾讯@AlloyTeam在知乎上的回答
React 的核心思想是每次对于界面 state 的改动,都会重新渲染整个 virtual dom,然后新老的两个 virtual dom 树进行 diff,对比出变化的地方,然后通过 renderer 渲染到实际的UI界面(这里可能是浏览器的DOM,也可能是native组件)。这样实质上就是把界面变成一个纯粹的状态机,React 的作用就是把这个状态机之间的状态转换高效率地运行出来。但是存在以下问题:
- 1、不是每一次状态的变化都要立刻执行。
- 2、不同的状态变化之间是有轻重缓急之分的,比如『动画』这种状态变化的优先级,出于对用户体验的考量,为了避免动画卡顿或者掉帧,一般比『改变页面数据』的优先级更高。
- 3、我们现在的做法只是调用 setState 触发重新渲染,然后 React 会收集一个 tick 内的 state 变化,然后执行,所以有可能大量的计算会在同一时刻阻塞进程。但我们没法控制 React 运算的时序问题,也不太可能通过手工声明让动画的优先级比数据变更更高。而 React 作为一个用户交互的框架,它本应该能让程序员能控制这些东西。所以这个破事要怎么解决咧?( ⊙ o ⊙ )我们知道,任何的函数调用都会有自己的调用栈,比如对于 v = f(d) 这个函数来说,函数 f 可能又调用了一系列其它的函数,这些函数就包括在 f 的调用栈中。关键的问题在于,这种原生的调用栈是基本不可延迟的,它会立即执行,如果计算量很大的话就会阻塞住进程,让界面失去响应,这种事情经常发生在 React 的渲染过程中。
或者看颜什么都不记得适的回答:
状态转移时,是在一次 tick 中递归遍历组件树,找出需要更新的节点 rerender。但是这样造成了一些问题:
- 在 UI 中,不是所有的状态转移都需要立即执行。大量的同时计算可能会导致资源的浪费,以致出现掉帧的状况,降低用户体验。
- 不同类型的状态转移应有不同的优先级,比如点击按钮出现动画的优先级应该比 Fetch API 要高。
- React 是 pull-based 实现的,事务的时序全部由 React 决定。我们没办法操控执行事务的时序。
Omi component update
Omi有上面的问题吗? 没有。
Omi的卖点之一便是:更自由的更新,每个组件都有update方法,自由选择你认为最佳的时机进行更新。这样设计的一大好处是更加灵活,如果想要自动更新集成个mobx或者obajs便可,进可功退可守护。
数据和视图虽然是关系密切,但是解耦的设计还是非常必要,这样可以应付更多的场景。好处:
- 你可以等某个动画播放完成再进行update
- 你可以控制update顺序
- 你可以update前后干一些事情而不需要利用生命周期的钩子函数(有的时候钩子函数让连续的逻辑打得粉碎...)
component update说完了吗?没有... Omi不仅仅有component update!还有更加强大的 updateSelf。
Omi component updateSelf
先说下两者的区别:
- update: 更新组件树
- updateSelf: 更新组件(不包含任何子节点)
如下图所示:
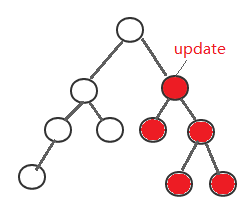
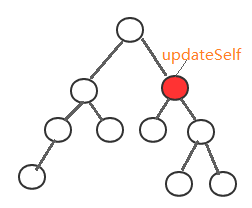
标红的代表会进行更新的节点。
场景模拟
class TestComponent extends Omi.Component {
render () {
return `<div>
<h3>{{title}}</h3>
<List name="list" data="listData" />
</div>`;
}
} 组件结构上面代码所示:
- 如果调用组件实例的update的话,会更新组件本身以及 List组件
- 如果调用组件实例的updateSelft的话,会更新组件本身,不会更新List组件
比如我们仅仅修改了this.data.title,就可以调用this.updateSelf方法,虽然一般情况下无脑update也能达到同样的结果,虽然morphdom的DOM diff已经足够轻量快速,但是一定没有updateSelf方法快速。上面的例子updateSelf优势可能不明显,如果这样呢:
class TestComponent extends Omi.Component {
render () {
return `<div>
<h3>{{title}}</h3>
<List name="list" data="listData" />
<List name="list" data="listData" />
<Content name="list" data="listData" />
<Slider name="list" data="listData" />
</div>`;
}
} 再或者Content、Slider里面再嵌套了子组件,子组件又嵌套了子组件,如果仅仅只是需要修改title的话,updateSelf优势就尽显无疑。
实现细节
这里主要说一说updateSelf的实现细节。主要包含两点:
- 不重新render的情况下拿到子组件的完整的HTML
- 关闭子组件的DOM diff
进行updateSelf的时候,就算子组件的data发生了变化,也不去改变子组件。因为updateSelf就意思就是更新自身。
所以子组件的HTML不需要使用模板和data生成,只需要component.node.outerHTML就可以了。outerHTML在古老的firefox是不支持的,可以通过创建节点插入然后读innerHTML进行polyfill。
组件本身的HTML是需要使用模板和data生成,子组件就使用刚刚的outerHTML替换便可。但是问题来了,子组件的DOM diff其实是没有必要的,虽然morphdom的DOM diff已经足够轻量快速。但是子组件他们本来就是一模一样,没有必要的开销。所以需要关闭DOM diff~~。然后morphdom没有ignore相关的配置....
扩展 morphdom
API:
morphdom(node, newNodeHTML, {
ignoreAttr: ['attr1','attr2']
} ) 比如上面代表只要标记了attr1或者attr2的就是忽略,当然为了规避错误,这里需要严格的匹配才会ignore DOM diff。怎么算严格的匹配?就是:
- 当同样的attr的DOM,并且该attr在ignoreAttr里才会ignore DOM diff
Omi Store体系addSelfView
Omi Store体系以前通过addView进行视图收集,store进行update的时候会调用组件的update。
与此同时,Omi Store体系也新增了addSelfView的API。
- addView 收集该组件视图,store进行update的时候会调用组件的update
- addSelfView 收集该组件本身的视图,store进行update的时候会调用组件的updateSelf
当然,store内部会对视图进行合并,比如addView里面加进去的所有视图有父子关系的,会把子组件去掉。爷孙关系的会把孙组件去掉。addSelfView收集的组件在addView里已经收集的也去进行合并去重,等等一系列合并优化。
Omi相关
- Omi官网omijs.org
- Omi的Github地址https://github.com/AlloyTeam/omi
- 如果想体验一下Omi框架,可以访问 Omi Playground
- 如果想使用Omi框架或者开发完善Omi框架,可以访问 Omi使用文档
- 如果你想获得更佳的阅读体验,可以访问 Docs Website
- 如果你懒得搭建项目脚手架,可以试试 omi-cli
- 如果你有Omi相关的问题可以 New issue
- 如果想更加方便的交流关于Omi的一切可以加入QQ的Omi交流群(256426170)












