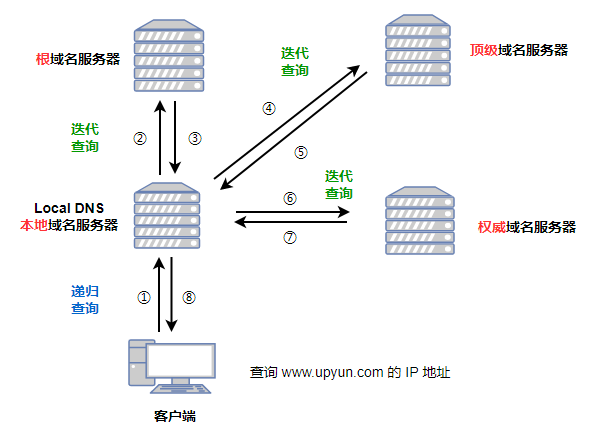
我们在网页中输入网址后发生了什么呢? 1.浏览器获取域名 2.通过DNS协议获取域名对应服务器的ip地址 3.浏览器和对应的服务器通过三次握手建立TCP连接 4.浏览器通过HTTP协议向服务器发送数据请求 5.服务器将查询结果返回给浏览器 6.四次挥手释放TCP连接 7.浏览器渲染结果
其中涉及到了: 应用层:HTTP和DNS 传输层:TCP UDP 网络层:IP ICMP ARP
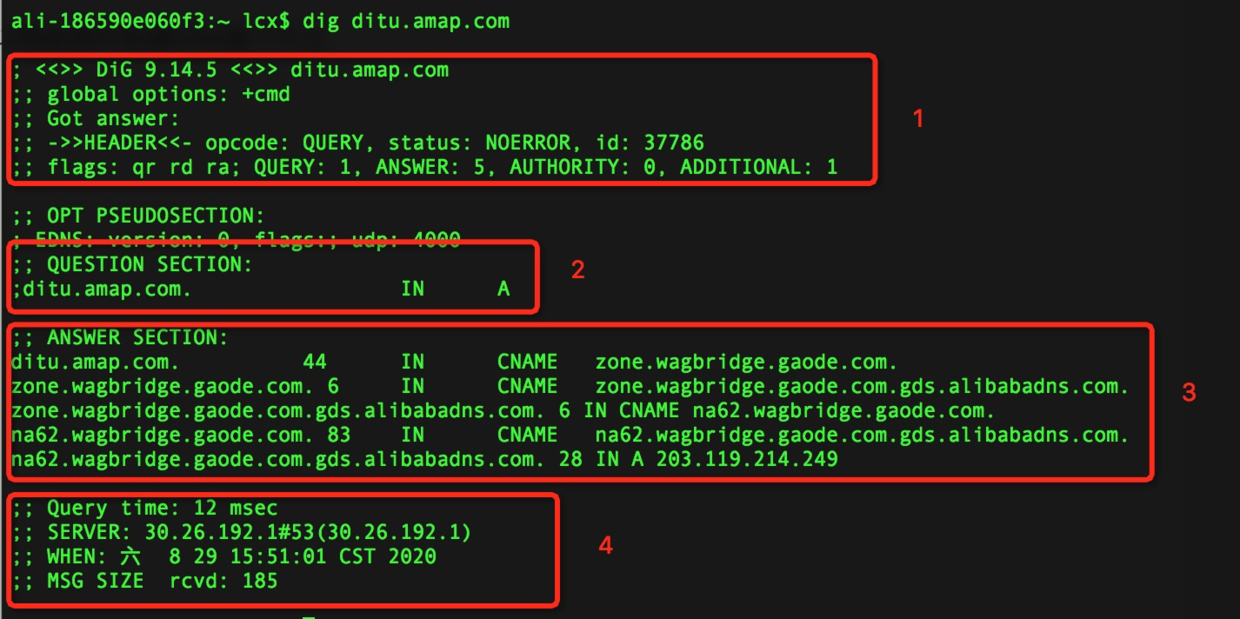
那为什么需要到用代理呢? 因为在做爬虫的过程中经常会遇到这样的情况: 最初爬虫正常运行,正常抓取数据,一切看起来都很不错,然而喝口茶的功夫可能就会出现错误,比如403 Forbidden 这时候打开网页一看,可能会看到“您的IP访问频率太高”这样的提示。 出现这种现象的原因是网站采取了一些反爬虫措施。 比如,服务器会检测某个IP在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返回一些错误信息,这种情况可以称为封IP。 而代理ip就避免了这个问题。
代理ip的获取 一、原始方法注入数据
// 初始化方法
constructor () {
// token
this.token = "Z1QljZOZiT4NTG"
// 请求地址
this.req_url = 'http://api.txapi.cn/v1/proxies_ip'
}二、开始代理IP
注意:agr 参数是必传;1:HTTP 2:HTTPS 3:SOCKS5
agent_IP (url, token) {
let p = new Promise(function (resolve, reject) {
axios({
url: url,
method: 'GET',
params: {
token: token,
agr: 1
}
}).then(resp => {
if(resp.data.code !== 200){
console.log("查询失败")
} else {
resolve(resp.data)
}
})
})
return p
}三、封装run函数
// run函数
run () {
this.agent_IP(this.req_url, this.token).then(res => {
console.log(res); // 查询结果
})
}四、完整代码
const axios = require('axios')
class Parse {
// 初始化方法
constructor () {
// token
this.token = "Z1QljZOZiT4NTG"
// 请求地址
this.req_url = 'http://api.txapi.cn/v1/proxies_ip'
}
// 代理IP
agent_IP (url, token) {
let p = new Promise(function (resolve, reject) {
axios({
url: url,
method: 'GET',
params: {
token: token,
agr: 1
}
}).then(resp => {
if(resp.data.code !== 200){
console.log("查询失败")
} else {
resolve(resp.data)
}
})
})
return p
}
// run函数
run () {
this.agent_IP(this.req_url, this.token).then(res => {
console.log(res); // 查询结果
})
}
}
if(__filename === process.mainModule.filename) {
// new一个Parse对象
const p = new Parse()
// 调用run方法
p.run()
}