
英国弗兰明曾说过一句话:“不要等待运气降临,应该去努力掌握知识。”
1 前言
大家好,我是阿沐!你的收获便是我的喜欢,你的点赞便是对我的认可。
作为一年开发经验的毕业生,在上一个章节跟面试官聊了聊redis的基础数据结构列表类型,我们凭借日常知识积累跟面试官展开了相爱相杀场景以及面试期间内心的活动状况。通过结合项目在实际场景中的运用案例和知识点的细节,稳稳的对答如流。
那么这一章节面试官会考验我们对redis的hash数据结构的原理、场景、注意事项、实战这些点进行考察。
好了,开始我们与面试官的博弈,这将是一个很长很长的面试过程,请大家!
2 数据结构hash的理解
面试官:“小年轻,今天让我考验下你redis的hash数据结构知识,不是很厉害嘛,不给你搞个下马威是不行了,我没面子啊,我不要面子的嘛?”。休息完了,我们就继续下一个话题吧,你是怎么理解哈希类型的呢?
面试者:“嚯嚯嚯,看来是故意来找茬的,讲完sting,讲list,现在hash;告诉你我不怕”。非常非常地自信说道:
redis中的哈希(hash或者散列表),内部存储很多键值对以key - [Field-Value]的形式存储,也是一种数组+链表的二维结构(本身又是一个 键值对结构)。正是因为这样,通常我们可以使用哈希存储一个对象信息。下面是我对hash的关系图如下:
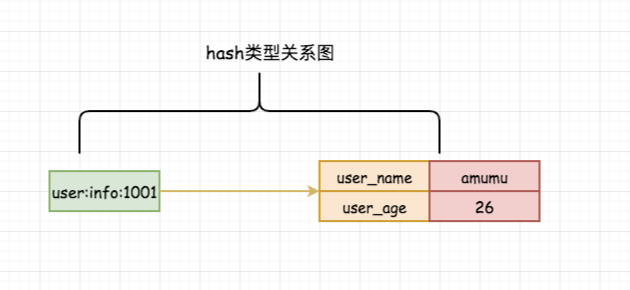
注意点:从上图我们可以看出,哈希的关系隐射实际上是field->value的映射,它们才是一对。
面试官:“不要以为知道一点点概念就洋洋得意,这是作为一个开发最最最基础的理念。”
3 常用的hash指令
面试官:基于上面你对哈希的理解,是否可以简单的介绍下hash的比较常见的指令呢?
面试者:“估计真是看我比较年轻,以为的经验是虚报的,这是要考验我基础是吧!那我可就不客气了”。嗯嗯,那我说说我经常使用的一些操作指令吧。
1、查找select指令操作:
hget指令:hget key field 获取哈希表key中给定字段的值,不存在返回nil;时间复杂度O(1)。
hgetall指令:hgetall key 获取哈希表key中的所有字段和值,不存在返回空列表;时间复杂度O(n),n是哈希表的大小。
hlen指令:hlen key 获取哈希表key中field的数量,不存在返回0;时间复杂度O(1)。
hmget指令:hmget key [field ...] 获取哈希表key中一个或多个给定字段的值,不存在返回nil;时间复杂度O(n),n为给定字段的数量。
hkeys指令:hkeys key 获取哈希表key中所有字段,不存在返回空表;时间复杂度O(n),n为哈希表的大小。
hscan指令:hscan key cursor(游标) [MATCH pattern(匹配的模式)] [COUNT count(指定从数据集里返回多少元素,默认值为 10 )] 获取哈希表key中匹配元素。
hvals指令:hlen key 获取哈希表key中所有的字段的值,不存在返回空表;时间复杂度O(n),n是哈希表的大小。
hexists指令:hexists key field 获取哈希表key中field是否存在,存在返回1不存在返回0;时间复杂度O(1)。
hstrlen指令:hstrlen key field 获取哈希表key中字段长度,不存在返回0,否则返回长度整数;时间复杂度O(1)。2、添加insert指令操作:
hset指令:hset key value 将哈希表key中的字段的值设为value,不存在则创建设置,否则将覆盖旧值;时间复杂度O(1)。
注意点:如果哈希表中字段已经存在且旧值已被新值覆盖,返回0而不是1,不能搞错。
hmset指令:hmset field value [field value ...] 一次将多个field-value数据设置进哈希表中,表中已存在的字段会直接覆盖;时间复杂度O(n),n为field-value的数量。
注意:不同于hset,若哈希表已存在字段值,重复设置将会返回OK,而不是0。
hsetnx指令:hsetnx key field value 仅仅当哈希表中字段不存在时可设置,否则无效;时间复杂度O(1)。
注意:跟setnx不同的是,若设置的字段已存在值,那么当前操作将返回结果集为0而不是OK。
hincrby指令:hincrby key field increment 给哈希表中指定字段增加数值;时间复杂度O(1)。
注意:执行hincrby命令后返回的是字段的最新值,而不是ok或者1。3、删除delete指令操作:
hdel指令:hdel key field [field ...] 删除哈希表中一个或多个字段,不存在则忽略;时间复杂度O(n),n为要删除字段的数量。
注意:删除操作返回值是删除成功的数量,不存在的字段将被忽略。下面是我整理哈希类型命令的时间复杂度,大家可以参考此表:
| 指令 | 时间复杂度 |
|---|---|
| hget key field | O(1) |
| hgetall key | O(n),n是哈希表的大小 |
| hlen key | O(1) |
| hmget key [field ...] | O(n),n为给定字段的数量 |
| hkeys key | O(n),n为哈希表的大小 |
| hexists key field | O(1) |
| hstrlen key field | O(1) |
| hset key value | O(1) |
| hmset field value [field value ...] | O(n),n为field-value的数量 |
| hsetnx key field value | O(1) |
| hincrby key field increment | O(1) |
| hdel key field [field ...] | O(n),n为要删除字段的数量 |
面试官:“咦,年轻人善于整理功能划分呀!可以可以,这样做笔记也是一个不错的选择”。那么我看你简历上你写着熟练掌握redis的应用场景,可以简单说下你是如何在项目中使用哈希数据表嘛?
面试者:“这不是 张飞吃豆芽,小菜一碟”。你好,面试官;没问题的,下面我来阐述我具体的应该场景
3.1 哈希的使用场景
面试者:其实hash的使用在项目中是最常见的一种数据结构,那么我们通常会使用hash结构来存储网站用户的基础信息;也可以用来定时统计指定的某些文章的阅读总数等等。实际上我们都是根据自己的业务场景来决定怎么用。
面试官:嗯嗯,那么可以简单的介绍下你是如何使用的?面试官还是一副严肃的表情,仿佛我欠了她几万块钱一样,搞的这么严肃我都赖的面试了。
3.1.1 用户信息
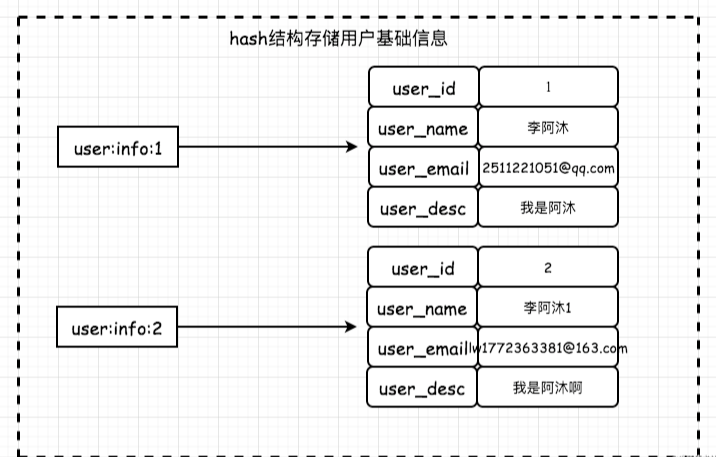
我们首先创建一个关系型的用户信息数据表,存储用户的基础信息(如果存在冷热数据分离,或者分表分库。做法都一样):
CREATE TABLE `mumu_user` (
`user_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`user_name` varchar(255) NOT NULL DEFAULT '' COMMENT '用户昵称',
`user_pwd` varchar(64) NOT NULL DEFAULT '' COMMENT '用户密码',
`user_email` varchar(125) NOT NULL DEFAULT '' COMMENT '用户邮箱',
`user_gender` tinyint(2) NOT NULL DEFAULT '0' COMMENT '用户性别 0-保密;1-男;2-女',
`user_desc` varchar(255) NOT NULL DEFAULT '' COMMENT '用户描述',
`create_at` int(10) NOT NULL DEFAULT '0' COMMENT '注册时间',
PRIMARY KEY (`user_id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户信息基础表';我们可以添加几条用户数据:
insert into `mumu_user` (`user_name`, `user_pwd`,`user_email`,`user_desc`,`create_at`) VALUES('李阿沐', '123456', '2511221051@qq.com', '我是阿沐', unix_timestamp());
insert into `mumu_user` (`user_name`, `user_pwd`,`user_email`,`user_desc`,`create_at`) VALUES('李阿沐1', '123456789', 'lw1772363381@163.com', '我是阿沐啊', unix_timestamp());那么我们使用Redis哈希结构存储用户信息的示意图如下:
<?php
<?php
// 实例化redis
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
//echo "Server is running: " . $redis->ping();
$data = [
'user_id' => 1001,
'user_name' => '李阿沐',
'user_email' => '2511221051@qq.com',
'user_desc' => '我是阿沐',
];
$key = sprintf('user:info:%u', $data['user_id']);
//向 hash 表中批量添加数据:hMset
$result = $redis->hMSet($key, $data);
$redis->expire($key,120);
if ($result) exit('批量设置用户信息成功!');
exit('批量设置用户信息失败!');
-- 终端查询
127.0.0.1:6379> HGETALL user:info:1001
1) "user_id"
2) "1001"
3) "user_name"
4) "\xe6\x9d\x8e\xe9\x98\xbf\xe6\xb2\x90"
5) "user_email"
6) "2511221051@qq.com"
7) "user_desc"
8) "\xe6\x88\x91\xe6\x98\xaf\xe9\x98\xbf\xe6\xb2\x90"面试官:嗯嗯,这是最基础的语法使用场景,没有什么特别强调的,你还可以说说在其他方面的使用吗?
面试者:可以,我就举一个比较简单的案例,通过一个活动中的某一个小部分用hash的一个小场景吧。
3.1.2 抽奖场景
场景:公司要做一个抽奖活动,在网页上共有8个道具可以抽奖,最大的是一辆豪华兰博基尼🚘,限制数量2量;其他道具各自限制抽奖数量,其中一个道具不限量,所有用户抽奖必中。
如何考虑:① 保证用户必中 ② 保证道具不限超 ③ 保证并发情况下原子性操作
那么大部分刚初入茅庐的小伙伴针对这三种情况如何解决呢?可能会有这种操作情况:为了保证不限超道具数量,会先redis->get(id)道具数量,然后拿到结果跟限制的数量对比;这种操作不是不可以,但是我们要考虑高并发的情况下,如何保证原子操作。
解决思路:① 在道具概率分配ok的情况下,要对限制数量的道具进行一个兜底操作 ② 每次用户抽奖对抽中的奖励进行数量检测 ③ 并发情况下:1.我们可以使用hincrby原子操作记录道具抽中的次数 2. 也可以使用get、set,但是必须要使用redis+lua实现原子操作,保证数据ok
下面是代码案例:
// 抽奖道具列表 道具列表可扩展多个 hash存储方便统一获取数据分析
const DRAW_PROP_LIST = [
[
'prop_id' => 123,
'prop_name' => '精选课堂笔记',
'limit' => 10,
'chance' => 15,
],
[
'prop_id' => 1234,
'prop_name' => '豪华兰博基尼',
'limit' => 2,
'chance' => 10,
],
[
'prop_id' => 12345,
'prop_name' => 'python入门实战教程',
'limit' => 3,
'chance' => 5,
],
[
'prop_id' => 123456,
'prop_name' => 'k8s实践书籍',
'limit' => 1,
'chance' => 70,
],
];
//randomChance 概率方法
$reward = DRAW_PROP_LIST[randomChance(array_column(DRAW_PROP_LIST, 'chance'))];
$key = "prop:count:record";
for ($i = 1; $i < 10; $i ++) {
$count = $redis->hIncrBy($key, $reward['prop_id'], 1);
echo $count.'-';
if ($count > $reward['limit']) {
echo '当前道具id为'.$reward['prop_id'].'已被抽奖完毕,可以考虑兜底数据返回给用户';
break;
}
}
// 结果集 1-2-当前道具id为123456已被抽奖完毕,可以考虑兜底数据返回给用户额外补充,我们也可以使用redis+lua保证原子操作设置:
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
//echo "Server is running: " . $redis->ping();
$lua = <<<SCRIPT
local _key = KEYS[1]
local limit = ARGV[1]
local num = ARGV[2]
local current_num = redis.call('get', _key)
current_num = tonumber(current_num) or 0
num = tonumber(num)
limit = tonumber(limit)
if (current_num + num) <= limit then
local ret, err = redis.call('set', _key, current_num + num)
if ret then
redis.call('expire', _key, 120)
return 1
end
end
return 0
SCRIPT;
$prop_id = 123456;
$key = 'prop:count:record:'.$prop_id;
for ($i = 1; $i < 10; $i++) {
$result = $redis->eval($lua, array($key, 5, 1), 1);
if ($result == 0) {
echo '当前道具id为'.$prop_id.'已被抽奖完毕,可以考虑兜底数据返回给用户';
break;
}
}
$redis->close();面试者:从上面的代码我们可以观察,当然最好是可以本地运行下测试下;即使我们多端并发请求跑1w次,那么当前道具的限制数量依然不会超,这就是获取和设置是原子性的操作。
面试官:“没想到小伙子还会使用lua脚本,看来还是小瞧了你呢,不过也算是不错的加分项”。那么你能分析一下,不同设置缓存的方案带来的问题是什么嘛?例如:set存储整个用户信息、set分别单独存储用户信息、hash存储用户信息。
面试者:“卧槽,这还要说一遍嘛?自己不会吗?这么简单还要问?”,内心蹭蹭蹭来了个三连问,心里还在逼逼赖赖的骂着:
set聚合存储:
优点:简单方便存储,设计合理序列化数据之后可以提高内存利用率。
缺点:序列化和反序列化对服务器有性能的开销,而且操作不方便,只修改一个值就需要全部数据更新后序列化重新塞进redis,麻烦且耗时间。不建议使用
set分散存储:
set user:info:1001:user_name 阿沐优点:对于用户每一个字段信息都能直观透明且操作简单只需要 set、get即可完成更新操作。
缺点:有多少字段需要占用多少键,可维护性差,批量查询用户信息,消耗性能增加,存储占用内存较大。拒绝使用
hash存储:每个用户属性只用一个键保存即可。
hmset user:info:1001 user_name amumu user_email 2511221051@qq.com优点:存储透明,操作简单,易维护占用内存较少(这个要看信息量,跟存储编码有关)
缺点:若存储的字段过长导致ziplist(压缩列表)和hashtable(哈希表)两种内部编码进行转换,如果全部使用哈希表存储,会导致hash消耗占用更多的内存空间。
面试官:嗯嗯,分析的挺到位的,我看你刚刚在介绍优缺点是提到了哈希的两种编码格式,可以具体的说一说嘛?
面试者:“额,这一直追着问是有点过分了呀,有句话是点到为止。这面试官肯定是在考验我的功底,那我也不能怂了我的能力啊”。面试官,你好,那么我来说说哈希表存储的两种编码格式吧!
3.1.3 ziplist(压缩列表OBJ_ENCODING_ZIPLIST)
Redis它很鸡贼,内部会根据数据量的情况,自动适配使用哪一种编码方案是最优的,也就是说这一操作对用户是完全透明。
redis的ziplist默认配置如下(实际可根据业务需求修改):
hash-max-ziplist-entries = 512 // 哈希元素个数
hash-max-ziplist-value = 64 // 哈希字段、字段值长度那么我们应该如何理解这个配置呢,hash又是如何决定使用哪种编码格式,什么时候才会使用ziplist?
必须同时满足以下条件:
1、哈希表中保存的键值对不能大于512个 num < 512
2、哈希表中保存的所有键值字符串的长度不能大于64字节 length < 64只有当全部满足以上条件,redis才会使用OBJ_ENCODING_ZIPLIST来存储该键。
面试者:我们光凭借语言口述,俗话说口说无凭,我们实际操作验证下。
localhost:6379> hmset test id 12345 name 我是阿沐
OK
localhost:6379> object encoding test //object encoding用来查看编码格式
"ziplist"
localhost:6379> hset test test_name "我是阿沐我是阿沐我是阿沐我是阿沐我是阿沐我是阿沐我是阿沐我是阿沐我是阿沐我是阿沐我是阿沐" // 132字节 肯定大于64字节了
(integer) 1
localhost:6379> object encoding test
"hashtable"以上的终端测试已验证了,当哈希表中有一个字段长度大于64字节时,编码格式就会从ziplist转换为hashtable格式。
面试官:“讲的还是满细致的嘛,虽然不够深入,可是回答的还是比较不错的。卧槽,突然内心想让问下是否了解过hash的底层源码实现了,这可咋办?问一问试一试?恩,就这样,稍微问下看看”。讲的挺好的,对ziplist压缩的理解以及知道如何检查编码方式挺熟练的,你是否可以尝试说下哈希编码转换的底层实现呢?
面试者:卧槽,卧槽,卧槽,这么狠,问我底层c嘛?好像我都忘记差不多了,这真是要搞死我哦;嘴巴里念念到。尝试看下源代码给面试官解释一下糊弄过去算了。
那么我们来简单的看下哈希切换编码的底层代码吧:
其实个人觉得并不需要看源码,知道怎么一回事就可以了;大部分开发并不是科班或者科班并没有好好学C,不一定能看明白怎么一回事,所以只需要理解是怎么回事,实现原理即可,不需要深究。
-- 目前我使用的是redis5.0版本 源码路径 t_hash.c ,此案例网上比比皆是
-- 大概45行左右
for (i = start; i <= end; i++) {
if (sdsEncodedObject(argv[i]) &&
// 若hash表中字段值长度超过配置64字节时,则转为OBJ_ENCODING_HT编码
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
hashTypeConvert(o, OBJ_ENCODING_HT); --设置存储编码格式
break;
}
}
-- 237行左右 当hash的字段长度(总数)大于配置指定的512个时,内部就会转为OBJ_ENCODING_HT(哈希字典)编码格式
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT); --设置存储编码格式
} else if (o->encoding == OBJ_ENCODING_HT) {
dictEntry *de = dictFind(o->ptr,field);可以画出压缩列表和hash表的结构示意图,方便更好地理解:
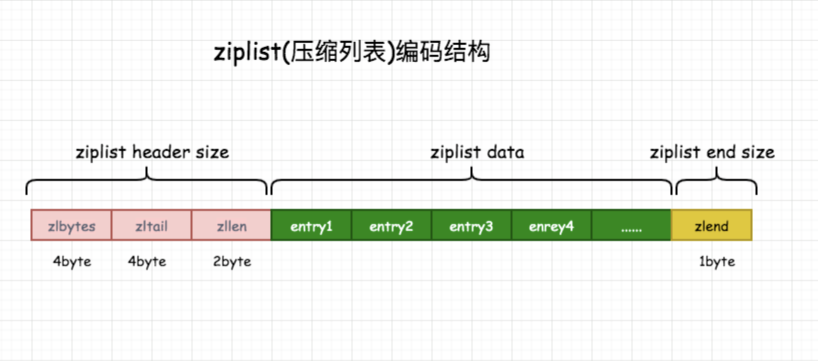
进行对数据的参数解析如下:
- 1、zlbytes:存储压缩列表的内存使用数量(4个byte无符号整数),通过zlbytes可以设置列表内存大小。
- 2、zltail:记录entry距离起始地址偏移量,占4个byte。
- 3、zllen:记录列表节点entry的总数目,占用2个byte。
- 4、entry:列表存储数据的节点,类型可字节数组或整数。
- 5、zlend:列表的结尾部,占用1个byte,恒为 0xFF(表示二进制1111 1111)。
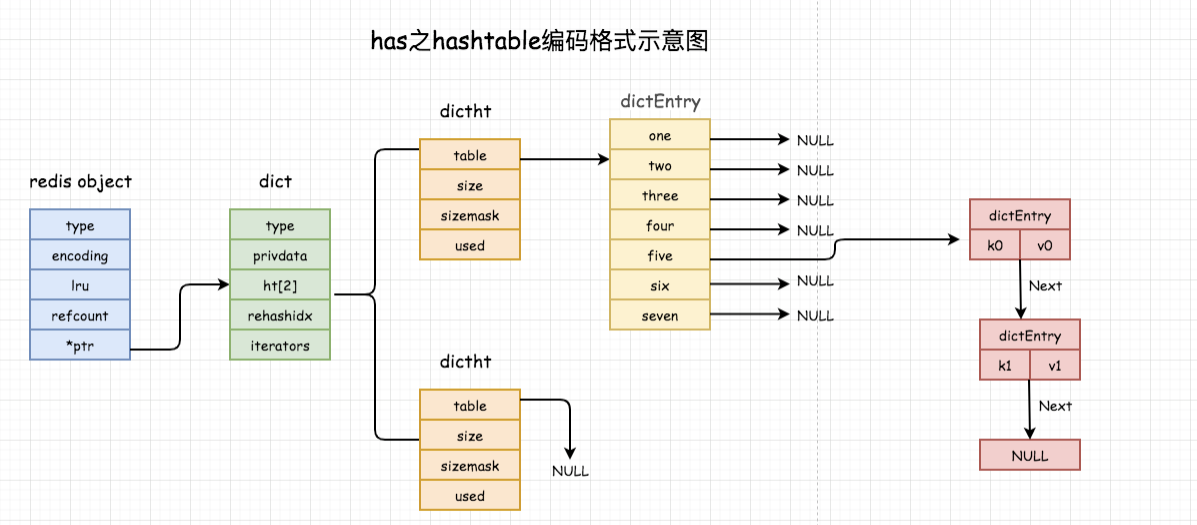
从上面的图结构可以看出:hashtable这种编码方式内部才是真正的哈希表结构或者称其为字典结构(一层层嵌套下去),所以可实现O(1)读写操作,操作效率极高。关系如下:
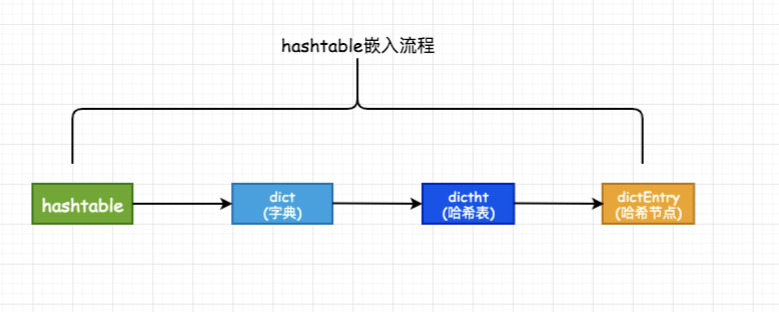
1、type:是一个指向dictType 结构的指针,保存了一系列用于操作特定类型键值对的函数;
2、privdata:保存了需要传给上述特定函数的可选参数;
3、ht[2]:是两个哈希表,一般情况下,只使用ht[0],只有当哈希表的键值对数量超过负载(元素过多)时,才会将键值对迁移到ht[1],这一步迁移被称为rehash(重哈希);
4、rehashidx:记录当前rehash的进度,rehash完成之后,重置为-1
5、table:是一个数组,数组的每个元素都是一个指向dictEntry结构的指针;
6、size:记录哈希表的大小,即table数组的大小,且一定是2的幂;
7、sizemask:用于对哈希过的键进行映射且值永远等于size-1。映射方法:哈希值和sizemask进行位与操作。
8、used:记录哈希表中已有结点的数量;
9、key:是键值对中的键;
10、v 是键值对中的值,它是一个联合类型,方便存储各种结构;
11、next 是链表指针,指向下一个哈希表节点,他将多个哈希值相同的键值对串联在一起,用于解决键冲突。面试官:“额,说的底层代码逻辑我都不咋会,小伙子藏的有点深啊!我不能让他看出来我不了解这些,必须淡定稳住战况,敷衍一下顺带过去”,心里一万个奔溃,想不到一个不到一年经验的小家伙竟然还知道底层代码原理,还能解释出来,嘴里嘀咕嘀咕着。
为什么我们日常开发中要使用ziplist而不是hashtable?那么ziplist又是如何实现hash存储?面试官的两连问:
为什么使用ziplist?
1、相对比hashtable,压缩列表整体结构少了指针的使用,减少了内存的使用。 2、ziplist使用更加紧凑的结构,元素之间是连续存储,在节省内存方面比hashtable要强不少。
ziplist如何实现hash存储?
它是将同一键值对的两个节点紧凑保存,键在节点的前面,值在节点后面;若有新的键值对插入,则会被放在ziplist表尾部。
面试官:ok,ok,ok,可以了;那就先到这里吧,休息一下。
面试者:给你一个🖕自己体会,真是超级难为我找个一年的小开发了。还好没有继续问 哈希算法、哈希冲突(collision)、hash扩展与收缩、渐进式hash这些知识点,不然真就废了,肯定答不上来。有想了解的小伙伴可以私下去看下这方面的资料,了解下这些来龙去脉;这里就不在阐述了,有机会时间充裕我们一起探讨画图解析。
最后总结
本文章具体描述是在实际面试中,面试官会问的一些跟hash相关的问题。当然我们的阐述对象是:刚毕业、初中级工程师,甚至一些假的高级开发,只会使用但是并没有去细看相关的一些使用原理,很可能就会在面试阶段被pass掉。
Redis的字典数据结构,是比较常用的缓存命令,也是面试高频出现的问题。我们通过场景去引导、思考哈希的一些特性以及存储编码选择原理。那么大家有不一样的看法,可以留言哦!
以上皆为个人对redis的哈希结构的使用、场景、原理、编码转换的理解,如有错误欢迎评论区指正。
参考文献
《Redis 的设计与实现(第二版)》
最后,欢迎关注我的个人公众号「我是阿沐」,会不定期的更新后端知识点和学习笔记。也欢迎直接公众号私信或者邮箱联系我,我们可以一起学习,一起进步。
好了,我是阿沐,一个不想30岁就被淘汰的打工人 ⛽️ ⛽️ ⛽️ 。













