

简介
在计算机科学中,比较和交换(Conmpare And Swap)是用于实现多线程同步的原子指令。它将内存位置的内容与给定值进行比较,只有在相同的情况下,将该内存位置的内容修改为新的给定值。这是作为单个原子操作完成的。
原子性保证新值基于最新信息计算; 如果该值在同一时间被另一个线程更新,则写入将失败。操作结果必须说明是否进行替换; 这可以通过一个简单的布尔响应(这个变体通常称为比较和设置),或通过返回从内存位置读取的值来完成。
核心思想
一个 CAS 涉及到以下操作:
我们假设内存中的原数据V,旧的预期值A,需要修改的新值B。
比较 A 与 V 是否相等。(比较)
如果比较相等,将 B 写入 V。(交换)
返回操作是否成功。
当多个线程同时对某个资源进行CAS操作,只能有一个线程操作成功,但是并不会阻塞其他线程,其他线程只会收到操作失败的信号。可见 CAS 其实是一个乐观锁。
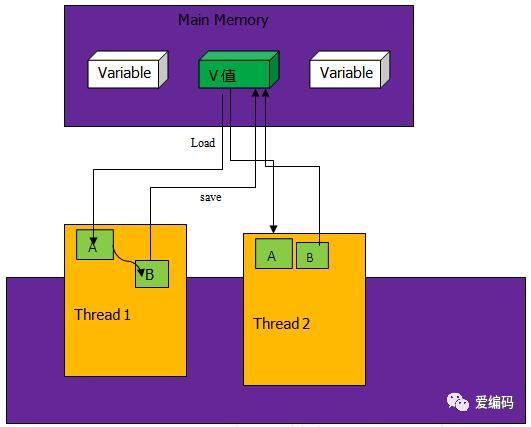
如上图中,主存中保存V值,线程中要使用V值要先从主存中读取V值到线程的工作内存A中,然后计算后变成B值,最后再把B值写回到内存V值中。多个线程共用V值都是如此操作。CAS的核心是在将B值写入到V之前要比较A值和V值是否相同,如果不相同证明此时V值已经被其他线程改变,重新将V值赋给A,并重新计算得到B,如果相同,则将B值赋给V。
如果不使用CAS机制,看看存在什么问题:
假如V=1,现在Thread1要对V进行加1,Thread2也要对V进行加1,首先Thread1读取V=1到自己工作内存A中此时A=1,假设Thread2此时也读取V=1到自己的工作内存A中,分别进行加1操作后,两个线程中B的值都为2,此时写回到V中时发现V的值为2,但是两个线程分别对V进行加处理结果却只加了1有问题。
CAS 实现
本文将对 java.util.concurrent.atomic 包下的原子类 AtomicInteger 中的 compareAndSet 方法进行分析,就能发现最终调用的是 sum.misc.Unsafe 这个类。
看名称 Unsafe 就是一个不安全的类,这个类是利用了 Java 的类和包在可见性的的规则中的一个恰到好处处的漏洞。Unsafe 这个类为了速度,在Java的安全标准上做出了一定的妥协。
再往下寻找我们发现 Unsafe的compareAndSwapInt 是 Native 的方法:
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
也就是说,这几个 CAS 的方法应该是使用了本地的方法。所以这几个方法的具体实现需要我们自己去 jdk 的源码中搜索。
最终到搜索 cmpxchg 函数
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) { // 判断是否是多核 CPU int mp = os::is_MP(); __asm { // 将参数值放入寄存器中 mov edx, dest // 注意: dest 是指针类型,这里是把内存地址存入 edx 寄存器中 mov ecx, exchange_value mov eax, compare_value // LOCK_IF_MP cmp mp, 0 /* * 如果 mp = 0,表明是线程运行在单核 CPU 环境下。此时 je 会跳转到 L0 标记处, * 也就是越过 _emit 0xF0 指令,直接执行 cmpxchg 指令。也就是不在下面的 cmpxchg 指令 * 前加 lock 前缀。 */ je L0 /* * 0xF0 是 lock 前缀的机器码,这里没有使用 lock,而是直接使用了机器码的形式。至于这样做的 * 原因可以参考知乎的一个回答: * https://www.zhihu.com/question/50878124/answer/123099923 */ _emit 0xF0L0: /* * 比较并交换。简单解释一下下面这条指令,熟悉汇编的朋友可以略过下面的解释: * cmpxchg: 即“比较并交换”指令 * dword: 全称是 double word,在 x86/x64 体系中,一个 * word = 2 byte,dword = 4 byte = 32 bit * ptr: 全称是 pointer,与前面的 dword 连起来使用,表明访问的内存单元是一个双字单元 * [edx]: [...] 表示一个内存单元,edx 是寄存器,dest 指针值存放在 edx 中。 * 那么 [edx] 表示内存地址为 dest 的内存单元 * * 这一条指令的意思就是,将 eax 寄存器中的值(compare_value)与 [edx] 双字内存单元中的值 * 进行对比,如果相同,则将 ecx 寄存器中的值(exchange_value)存入 [edx] 内存单元中。 */ cmpxchg dword ptr [edx], ecx }}
总结一下 JAVA 的 cas 是怎么实现的:
java 的 cas 利用的的是 unsafe 这个类提供的 cas 操作。
unsafe 的cas 依赖了的是 jvm 针对不同的操作系统实现的 Atomic::cmpxchg
Atomic::cmpxchg 的实现使用了汇编的 cas 操作,并使用 cpu 硬件提供的 lock信号保证其原子性
ABA 问题
CAS 由三个步骤组成,分别是“读取->比较->写回”。
考虑这样一种情况,线程1和线程2同时执行 CAS 逻辑,两个线程的执行顺序如下:
时刻1:线程1执行读取操作,获取原值 A,然后线程被切换走
时刻2:线程2执行完成 CAS 操作将原值由 A 修改为 B
时刻3:线程2再次执行 CAS 操作,并将原值由 B 修改为 A
时刻4:线程1恢复运行,将比较值(compareValue)与原值(oldValue)进行比较,发现两个值相等。
然后用新值(newValue)写入内存中,完成 CAS 操作
如上流程,线程1并不知道原值已经被修改过了,在它看来并没什么变化,所以它会继续往下执行流程。对于 ABA 问题,通常的处理措施是对每一次 CAS 操作设置版本号。java.util.concurrent.atomic 包下提供了一个可处理 ABA 问题的原子类 AtomicStampedReference,具体的实现这里就不分析了,有兴趣的朋友可以自己去看看。
ABA问题的解决办法
1.在变量前面追加版本号:每次变量更新就把版本号加1,则A-B-A就变成1A-2B-3A。
2.atomic包下的AtomicStampedReference类:其compareAndSet方法首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用的该标志的值设置为给定的更新值。
其他问题
CAS除了ABA问题,仍然存在循环时间长开销大和只能保证一个共享变量的原子操作
1. 循环时间长开销大
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
2. 只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。
比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
CAS 的应用
1.Java的concurrent包下就有很多类似的实现类,如Atomic开头那些。
2.自旋锁
3.令牌桶限流器
令牌桶限流器
就是系统以恒定的速度向桶内增加令牌。每次请求前从令牌桶里面获取令牌。如果获取到令牌就才可以进行访问。当令牌桶内没有令牌的时候,拒绝提供服务。我们来看看 eureka 的限流器是如何使用 CAS 来维护多线程环境下对 token 的增加和分发的。
参考文章
https://www.jb51.net/article/125232.htm
https://www.imooc.com/article/40690
https://segmentfault.com/a/1190000013127775
https://www.cnblogs.com/barrywxx/p/8487444.html
最后
如果对 Java、大数据感兴趣请长按二维码关注一波,我会努力带给你们价值。觉得对你哪怕有一丁点帮助的请帮忙点个赞或者转发哦。
关注公众号【爱编码】,小编会一直更新文章的哦。

本文分享自微信公众号 - 爱编码(ilovecode)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











