
1.1 数据类型概览
数据类型算是一种字段约束,它限制每个字段能存储什么样的数据、能存储多少数据、能存储的格式等。MySQL/MariaDB大致有5类数据类型,分别是:整形、浮点型、字符串类型、日期时间型以及特殊的ENUM和SET类型。
这5种数据类型的意义、限制和相关说明如下图所示:
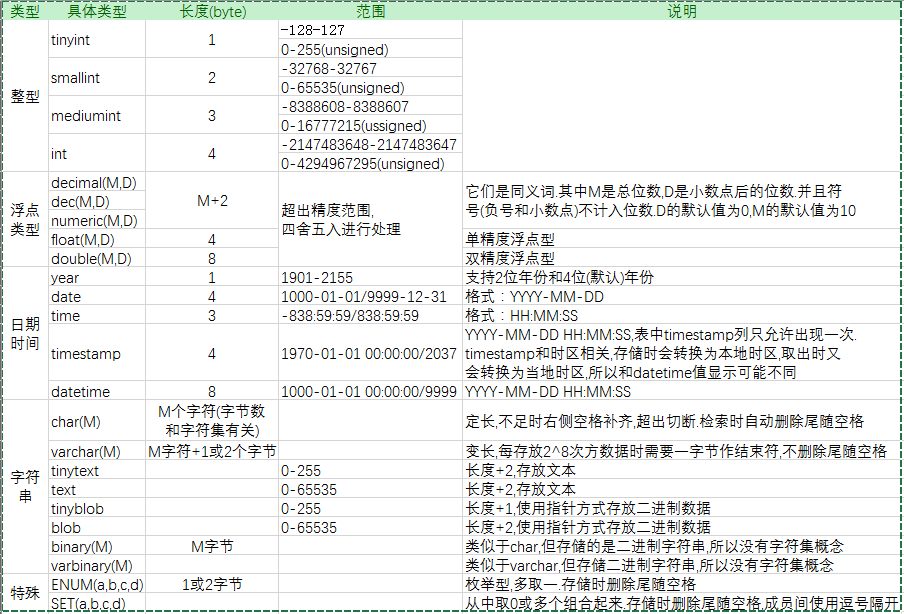
各数据类型占用字节数,参见mariadb官方手册。
1.2 存储机制和操作方式
数据类型之所以能限定字段的数据存储长度,是因为在创建表时在内存中严格划定了地址空间,地址空间的长度是多少就能存储多少字节的数据。当然,这是一个很粗犷的概念,更具体的存储方式见下面的描述。
数据类型限定范围的方式有两种:一是严格限定空间,划分了多少空间就只能存储多少数据,超出的数据将被切断;二是使用额外的字节的bit位来标记某个地址空间的字节是否存储了数据,存储了就进行标记,不存储就不标记。
1.2.1 整型的存储方式
此处主要说明整型的存储方式,至于浮点型数据类型的存储方式要考虑的东西太多。
对于整型数据类型来说,它严格限定空间,但它和字符不同,因为每个已划分的字节上的bit位上的0和1直接可以计算出数值,所以它的范围是根据bit位的数量值来计算的。一个字节有8个Bit位,这8个bit位可以构成2^8=256个数值,同理2字节的共2^16=65536个数值,4字节的int占用32bit,可以表示的范围为0-2^32。也就是说,在0-255之间的数字都只占用一个字节,256-65535之间的数字需要占用两个字节。
需要注意,在MySQL/mariadb中的整型数据类型可以使用参数M,M是一个正整数,例如INT(M),tinyint(M)。这个M表示的是显示长度,如int(4)表示在输出时将显示4位整数,如果实际值的位数小于显示值宽度,则默认使用空格填充在左边。而结果位数超出时将不影响显示结果。一般该功能都会配合zerofill属性用0代替空格填充,但是使用了zerofill后,该列就会自动变成无符号字段。例如:
CREATE TABLE test3(id INT(2) ZEROFILL NOT NULL);
INSERT INTO test3 VALUES(1),(2),(11),(111);
SELECT id FROM test3;
+-----+
| id |
+-----+
| 01 |
| 02 |
| 11 |
| 111 |
+-----+
4 rows in set (0.00 sec) 唯一需要注意的是,显示宽度仅仅影响显示效果,不影响存储、比较、长度计算等等任何操作。
1.2.2 字符类型的存储方式
此处主要说明char和varchar的存储方式以及区别。
char类型是常被称为"定长字符串类型",它严格限定空间长度,但它限定的是字符数,而非字节数,但以前老版本中限定的是字节数。因此char(M)严格存储M个字符,不足部分使用空格补齐,超出M个字符的部分直接截断。
由于char类型有"短了就使用空格补足"的能力,因此为了体现数据的真实性,在从地址空间中检索数据时将自动删除尾随的空格部分。这正是char的一个特殊性,即使是我们手动存储的尾随空格也会被认为是自动补足的,于是在检索时被删除。也就是说在where语句中name='gaoxiaofang '和name='gaoxiaofang'的结果是一样的。
例如:
create table test2(a char(4) charset utf8mb4);
insert into test2 values('恭喜你'),('恭喜你成功晋级'),('hello'),('he ');
select concat(a,'x') from test2;
+---------------+
| concat(a,'x') |
+---------------+
| 恭喜你x |
| 恭喜你成x |
| hellx |
| hex |
+---------------+
4 rows in set 从上面的结果可以看到,char(4)只能存储4个字符,并删除尾随空格。
varchar常被称为"变长字符串类型",它存储数据时使用额外的字节的bit位来标记某个字节是否存储了数据。每存储一个字节(不是字符)占用一个bit位进行记录,因此一个额外的字节可以标记共256个字节,2个额外的字节可以标记65536个字节。但MySQL/mariadb限制了最大能存储65536个字节。这表示,如果是单字节的字符,它最多能存储65536个字符,如果是多字节字符,如UTF8的每个字符占用3个字节,它最多能存储65536/3=21845个utf8字符。
因此,varchar(M)存储时除了真实数据占用空间长度,还要额外计算1或2个字节的Bit位长度,即对于单字节字符实际占用的空间为M+1或M+2个字节,对于多字节字符(如3字节)实际占用的空间为M*3+1或M*3+2个字节。
由于varchar存储时需要采用额外的bit位记录每一个字节,短了的数据不会自动使用补齐,因此显式存储的尾随空格也会被存储并在Bit位上进行标记,也就是说不会删除尾随空格。
和char(M)一样,当指定varchar(2)时,只能存储两个字节的字符,如果超出了,则切断。
关于char、varchar以及text字符串类型,它们在比较时不会考虑尾随空格,但做like匹配或正则匹配时会考虑空格,因为匹配时字符是精确的。例如:
create table test4(a char(4),b varchar(5));
insert into test4 values('ab ','ab ');
select a='ab ',b='ab ',a=b from test4;
+-----------+--------------+-----+
| a='ab ' | b='ab ' | a=b |
+-----------+--------------+-----+
| 1 | 1 | 1 |
+-----------+--------------+-----+
1 row in set
select a like 'ab ' from test4;
+-------------------+
| a like 'ab ' |
+-------------------+
| 0 |
+-------------------+
1 row in set 最后需要说明的是,数值在存储(或调入内存)时,以数值型方式存储比字符型或日期时间类型更节省空间。因为整数值存储时是直接通过bit计算数值的,0-255之间的任意整数都只占一个字节,256-65535之间的任意整数都占2个字节,而占用4个字节时便可以代表几十亿个整数之间的任意一个,这显然比字符型存储时每个字符占用一个字节节省空间的多。例如值"100"存储为字符型时占用三个字节,而存储为数值型将只占用一个字节。因此数据库默认将不使用引号包围的值当作数值型,如果明确要存储为字符型或日期时间型则应该使用引号包围以避免歧义。
1.2.3 日期时间型的存储方式
日期时间型数据存储时需要使用引号包围,避免和数值类型的数据产生歧义。关于日期时间的输入方式是非常宽松的,以下几种方式都是被允许的:任意允许的分隔符,建议使用4位的年份。
20110101
2011-01-01 18:40:20
2011/01/01 18-40-20
20110101184020 1.2.4 ENUM数据类型
ENUM数据类型是枚举型。定义方式为ENUM('value1','value2','value3',...),在向该类型的字段中插入数据时只能插入value中的某一个或NULL,插入其他值或空(即'')时都将截断为空数据。存储时会忽略大小写(将转换为ENUM中的字符),且会截断尾随空格。
mysql> create table test6(id int auto_increment primary key,name char(20),gender enum('Male','f'));
mysql> insert into test6(name,gender) values('malongshuai','Male'),('gaoxiaofang','F'),('wugui','x'),('tuner',null),('woniu','');
Query OK, 5 rows affected
Records: 5 Duplicates: 0 Warnings: 2
mysql> show warnings;
+---------+------+---------------------------------------------+
| Level | Code | Message |
+---------+------+---------------------------------------------+
| Warning | 1265 | Data truncated for column 'gender' at row 3 |
| Warning | 1265 | Data truncated for column 'gender' at row 5 |
+---------+------+---------------------------------------------+
2 rows in set
mysql> select * from test6;
+----+-------------+--------+
| id | name | gender |
+----+-------------+--------+
| 1 | malongshuai | Male |
| 2 | gaoxiaofang | f |
| 3 | wugui | |
| 4 | tuner | NULL |
| 5 | woniu | |
+----+-------------+--------+
5 rows in set ENUM类型的数据存储时是通过index数值进行存储的,相比于字符串类型,它只需要1或2个字节进行存储即可。理论上,当value的数量少于256个时只需一个字节,超出256个但少于65536个时使用2个字节存储。MySQL/MariaDB限制最多只能存储65536个value。当然,这是理论上的限制,实际存储时要考虑的因素有很多,例如NULL也会占用bit位,所以实际存储时可能250个value就需要2个字节。
ENUM的每个value都通过index号码进行编号,无论是检索还是操作该字段时都会通过index的值来操作。value1的index=1,value2的index=2,依次类推。但需要注意有两个特殊的index值:NULL值的index=NULL,空数据的index=0。
例如ENUM('a','b','c'),向该字段依次插入'','b','a','c',NULL,'xxx'时,由于第一个和最后一个都会截断为空数据,所以它们的index为0,插入的NULL的index为NULL,插入的'b','a','c'的index值分别为2,1,3。所以index号码和值的对应关系为:
| index | value |
|---|---|
| NULL | NULL |
| 0 | '' |
| 0 | '' |
| 1 | 'a' |
| 2 | 'b' |
| 3 | 'c' |
使用ENUM的index进行数据检索:
mysql> select * from test6 where gender=2;
+----+-------------+--------+
| id | name | gender |
+----+-------------+--------+
| 2 | gaoxiaofang | f |
+----+-------------+--------+
1 row in set 特别建议,不要使用ENUM存储数值,因为无论是排序还是检索或其他操作,都是根据index值作为条件的,这很容易产生误解。例如,下面是用ENUM存储两个数值,然后进行检索和排序操作。
mysql> create table test7(id enum('3','1','2'));
mysql> insert into test7 values('1'),('2'),('3');
# 检索时id=2,但结果查出来却为1,因为id=2的2是enum的index值,在enum中index=2的值为1
mysql> select * from test7 where id=2;
+----+
| id |
+----+
| 1 |
+----+
1 row in set
# 按照id进行排序时,也是通过index大小进行排序的
mysql> select * from test7 order by id asc;
+----+
| id |
+----+
| 3 |
| 1 |
| 2 |
+----+
3 rows in set 因此,强烈建议不要在ENUM中存放数值,即使是浮点型数值也很容易出现歧义。
1.2.5 SET数据类型
对于SET类型,和enum类似,不区分大小写,存储时删除尾随空格,null也是有效值。但不同的是可以组合多个给出的值。如set('a','b','c','d')可以存储'a,b','d,b'等,多个成员之间使用逗号隔开。所以,使用多个成员的时候,成员本身的值中不能出现逗号。如果要存储的内容不在set列表中,则截断为空值。
SET数据类型占用的空间大小和SET成员数量M有关,计算方式为(M+7)/8取整。所以:
1-8个成员占用1个字节;
9-16个成员占用2个字节;
17-24个成员占用3字节;
25-32个成员占用4个字节;
33-64个成员占用8字节。
MySQL/MariaDB限制最多只能有64个成员。
存储SET数据类型的数据时忽略重复成员并按照枚举时的顺序存储。如set('b','b','a'),存储'a,b,a','b,a,b'的结果都是'b,a'。
mysql> create table test8(a set('d','b','a'));
mysql> insert into test8 values('b,b,a'),('b,a,b'),('bab');
Query OK, 3 rows affected
Records: 3 Duplicates: 0 Warnings: 1
mysql> select * from test8;
+-----+
| a |
+-----+
| b,a |
| b,a |
| |
+-----+
3 rows in set 使用find_in_set(set_value,set_column_name)可以检索出包含指定set值set_value的行。例如检索a字段中包含成员b的行:
mysql> select * from test8 where find_in_set('b',a);
+-----+
| a |
+-----+
| b,a |
| b,a |
+-----+
2 rows in set 1.3 数据类型属性:unsigned
unsigned属性就是让数值类型的数据变得无符号化。使用unsigned属性将会改变数值数据类型的范围,例如tinyint类型带符号的范围是-128到127,而使用unsigned时范围将变成0到255。同时unsigned也会限制该列不能插入负数值。
create table t(a int unsigned,b int unsigned);
insert into t select 1,2;
insert into t select -1,-2; 上面的语句中,在执行第二条语句准备插入负数时将会报错,提示超出范围。
使用unsigned在某些情况下确有其作用,例如一般的ID主键列不会允许使用负数,它相当于实现了一个check约束。但是使用unsigned有时候也会出现些不可预料的问题:在进行数值运算时如果得到负数将会报错。例如上面的表t中,字段a和b都是无符号的列,且有一行a=1,b=2。
mysql> select * from t;
+---+---+
| a | b |
+---+---+
| 1 | 2 |
+---+---+
1 row in set 此时如果计算a-b将会出错,不仅如此,只要是unsigned列参与计算并将得到负数都会出错。
mysql> select a-b from t;
1690 - BIGINT UNSIGNED value is out of range in '(`test`.`t`.`a` - `test`.`t`.`b`)'
mysql> select a-2 from t;
1690 - BIGINT UNSIGNED value is out of range in '(`test`.`t`.`a` - 2)' 如果计算结果不是负数时将没有影响。
mysql> select 2-a,a*3 from t;
+-----+-----+
| 2-a | a*3 |
+-----+-----+
| 1 | 3 |
+-----+-----+
1 row in set 这并不是MySQL/MariaDB中的bug,在C语言中的unsigned也一样有类似的问题。这个问题在MySQL/MariaDB中设置set sql_mode='no_unsigned_subtraction'即可解决。
所以个人建议不要使用unsigned属性修饰字段。
1.4 数据类型属性:zerofill
zerofill修饰字段后,不足字段显示部分将使用0来代替空格填充,启用zerofill后将自动设置unsigned。zerofill一般只在设置了列的显示宽度后一起使用。关于列的显示宽度在上文已经介绍过了。
mysql> create table t1(id int(4) zerofill);
mysql> select * from t1;
+-------+
| id |
+-------+
| 0001 |
| 0002 |
| 0011 |
| 83838 |
+-------+
4 rows in set (0.00 sec) zerofill只是修饰显示结果,不会影响存储的数据值。











