
想写这个系列很久了,对自己也是个总结与提高。原来在学JAVA时,那些JAVA入门书籍会告诉你一些规律还有法则,但是用的时候我们一般很难想起来,因为我们用的少并且不知道为什么。知其所以然方能印象深刻并学以致用。
首先我们从所有类的父类Object开始:
1. Object类
(1)hashCode方法和equals方法
public native int hashCode();
public boolean equals(Object obj) {
return (this == obj);
}
Java内规定,hashCode方法的结果需要与equals方法一致。也就是说,如果两个对象的hashCode相同,那么两个对象调用equals方法的结果需要一致。那么也就是在以后的java程序设计中,你需要同时覆盖这两个方法来保证一致性。
在Object代码中,hashCode是native的,非java代码实现。主要原因是它的实现方法是通过将对象在内存中所处于的位置转换成数字,这个数字就是hashCode。但是这个内存地址实际上java程序并不关心也是不可知的。这个地址是由JVM维护并保存的,所以实现是native的。
如果两个Object的hashCode一样,那么就代表两个Object的内存地址一样,实际上他们就是同一个对象。所以,Object的equals实现就是看两个对象指针是否相等(是否是同一个对象)
在JAVA程序设计中,对于hashCode方法需要满足:
1.在程序运行过程中,同一个对象的hashCode无论执行多少次都要保持一致。但是,在程序重启后同一个对象的hashCode不用和之前那次运行的hashCode保持一致。但是考虑如果在分布式的情况下,如果对象作为key,最好还是保证无论在哪台机器上运行多少次,重启多少次,不同机器上,同一个对象(指的是两个equals对象),的hashCode值都一样(原因之后会说的)。
例如这里的Object对于hashCode的实现,在当前次运行,这个对象的存储地址是不变的。所以hashCode不变,但是程序重启后就不一定了。对于String的hashCode实现:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
String就是一种典型的适合在分布式的情况下作为key的存储对象。无论程序何时在哪里运行,同一个String的hashCode结果都是一样的。
2.如果两个对象是euqal的,那么hashCode要相同
3.建议但不强制对于不相等的对象的hashCode一定要不同。这样可以有效减少hash冲突
hashCode主要用于集合类中的hashmap(hashset的底层实现也是hashmap)。之后我们在Set源代码部分会继续细说。
对于equals方法的实现,则需要满足:
1. 自反性:对于任意非null的x,x.equals(x)为true
2. 对称性:对于任意非null的x和y,如果x.equals(y),那么y.equals(x)
3. 传递性:对于任意非null的x,y和z,如果x.equals(y)并且y.equals(z),那么x.equals(z)
4. 一致性:对于任意非null的x和y,无论执行多少次x.equals(y)结果都是一样的
5. 对于任意非null的x,x.equals(null)返回false
自己实现这些方法一定要满足这些条件,否则再用Java其他数据结构时会有意想不到的结果,后面会在回顾这个问题。
(2)toString( )方法——打印对象的信息
这个没啥好说的,默认的实现就是class名字@hashcode(如果hashCode()方法也是默认的话,那么就是如之前所述地址)
public String toString() {
return getClass().getName()+"@"+Integer.toHexString(hashCode());
}
(3) wait(), notify(), notifyAll()
这些属于基本的Java多线程同步类的API,都是native实现:
public final native void wait(long timeout) throws InterruptedException;
public final native void notify();
public final native void notifyAll();
那么底层实现是怎么回事呢?
首先我们需要先明确JDK底层实现共享内存锁的基本机制。
每个Object都有一个ObjectMonitor,这个ObjectMonitor中包含三个特殊的数据结构,分别是CXQ(实际上是Contention List),EntryList还有WaitSet;一个线程在同一时间只会出现在他们三个中的一个中。首先来看下CXQ: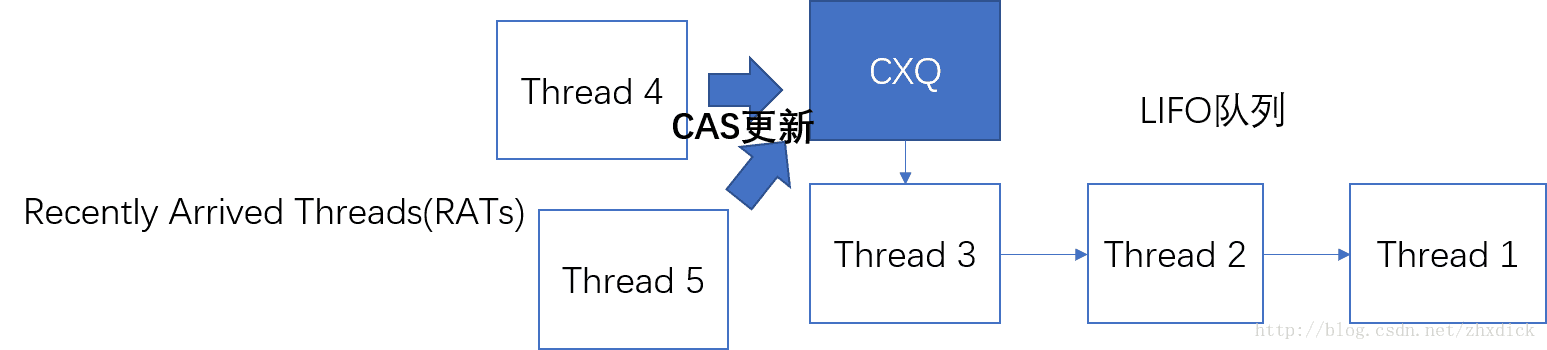
一个尝试获取Object锁的线程,如果首次尝试(就是尝试CAS更新轻量锁)失败,那么会进入CXQ;进入的方法就是CAS更新CXQ指针指向自己,如果成功,自己的next指向剩余队列;CXQ是一个LIFO队列,设计成LIFO主要是为了:
1. 进入CXQ队列后,每个线程先进入一段时间的spin自旋状态,尝试获取锁,获取失败的话则进入park状态。这个自旋的意义在于,假设锁的hold时间非常短,如果直接进入park状态的话,程序在用户态和系统态之间的切换会影响锁性能。这个spin可以减少切换;
2. 进入spin状态如果成功获取到锁的话,需要出队列,出队列需要更新自己的头指针,如果位于队列前列,那么需要操作的时间会减少
但是,如果全部依靠这个机制,那么理所当然的,CAS更新队列头的操作会非常频繁。所以,引入了EntryList来减少争用: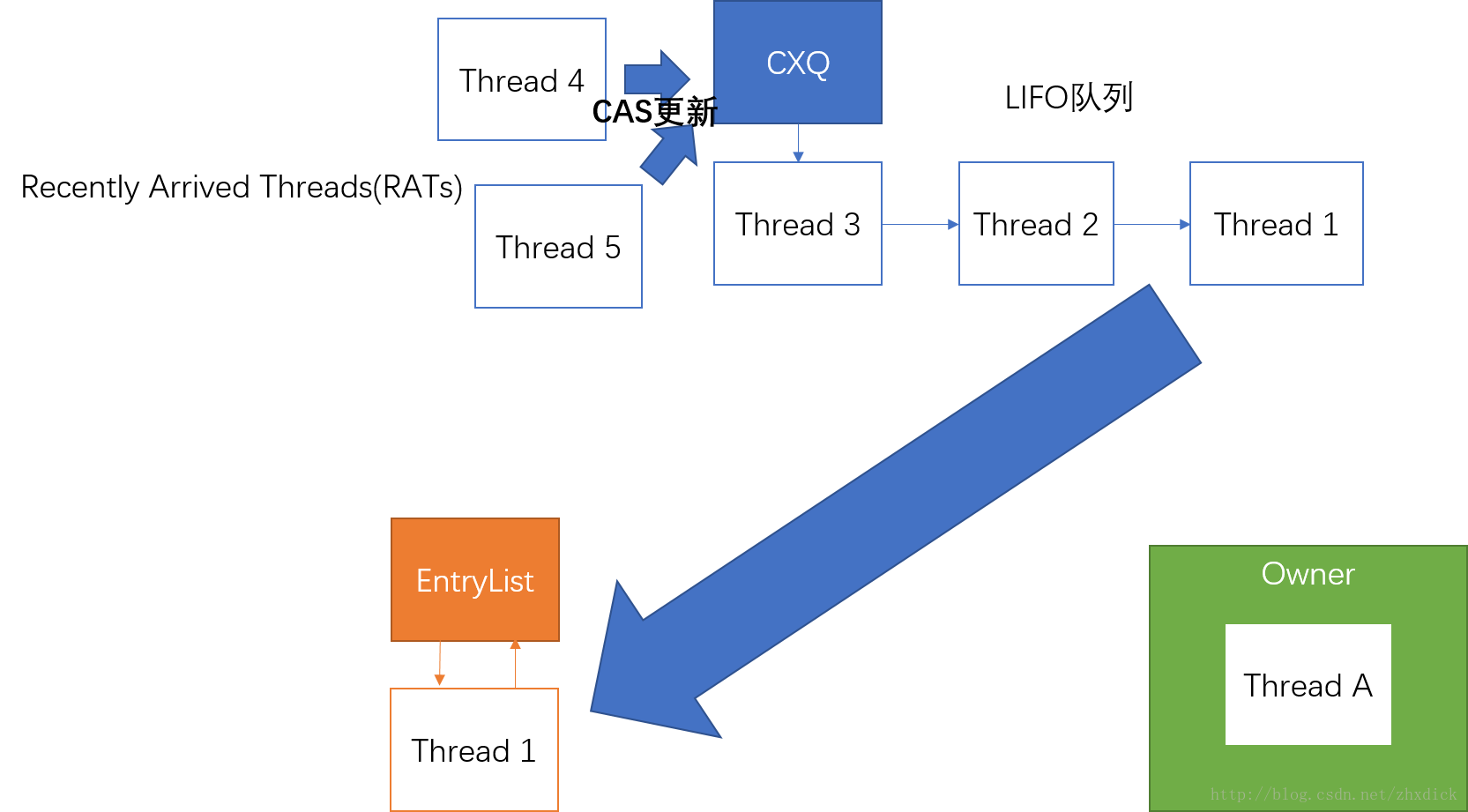
假设Thread A是当前锁的Owner,接下来他要释放锁了,那么如果EntryList为null并且cxq不为null,就会从cxq末尾取出一个线程,放入EntryList(注意,EntryList为双向队列),并且标记EntryList其中一个线程为Successor(一般是头节点,这个EntryList的大小可能大于一,一般在notify时,后面会说到),这个Successor接下来会进入spin状态尝试获取锁(注意,在第一次自旋过去后,之后线程一直处于park状态)。如果获取成功,则成为owner,否则,回到EntryList中。
这种利用两个队列减少争用的算法,可以参考: Michael Scott’s “2Q” algorithm
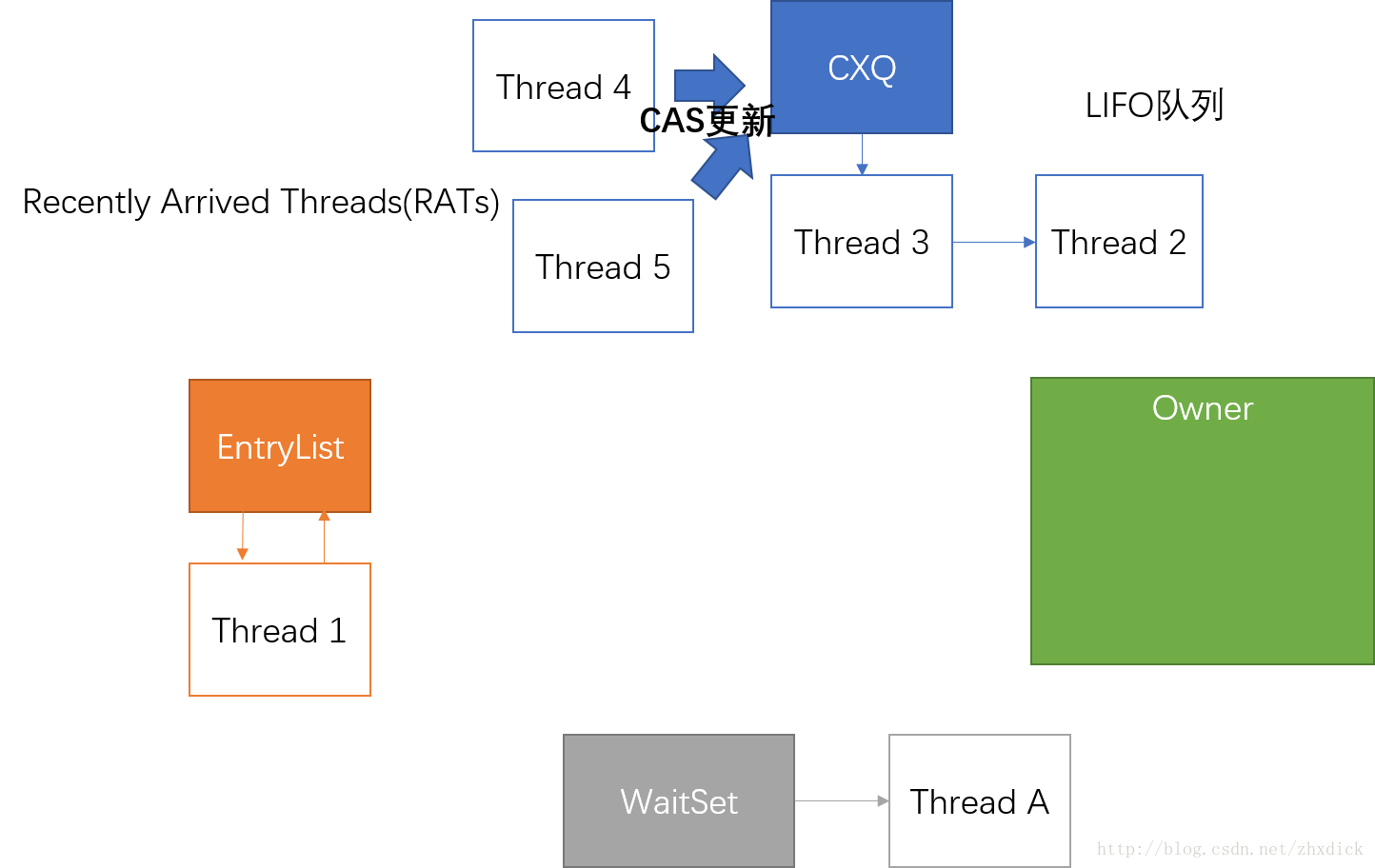
接下来,进入我们的正题,wait方法。如果一个线程成为owner后,执行了wait方法,则会进入WaitSet:
Object.wait()底层实现
void ObjectMonitor::wait(jlong millis, bool interruptible, TRAPS) {
//检查线程合法性
Thread *const Self = THREAD;
assert(Self->is_Java_thread(), "Must be Java thread!");
JavaThread *jt = (JavaThread *) THREAD;
DeferredInitialize();
//检查当前线程是否拥有锁
CHECK_OWNER();
EventJavaMonitorWait event;
// 检查中断位
if (interruptible && Thread::is_interrupted(Self, true) && !HAS_PENDING_EXCEPTION) {
if (JvmtiExport::should_post_monitor_waited()) {
JvmtiExport::post_monitor_waited(jt, this, false);
}
if (event.should_commit()) {
post_monitor_wait_event(&event, 0, millis, false);
}
TEVENT(Wait - ThrowIEX);
THROW(vmSymbols::java_lang_InterruptedException());
return;
}
TEVENT(Wait);
assert(Self->_Stalled == 0, "invariant");
Self->_Stalled = intptr_t(this);
jt->set_current_waiting_monitor(this);
//建立放入WaitSet中的这个线程的封装对象
ObjectWaiter node(Self);
node.TState = ObjectWaiter::TS_WAIT;
Self->_ParkEvent->reset();
OrderAccess::fence();
//用自旋方式获取操作waitset的lock,因为一般只有owner线程会操作这个waitset(无论是wait还是notify),所以竞争概率很小(除非响应interrupt事件才会有争用),采用spin方式效率高
Thread::SpinAcquire(&_WaitSetLock, "WaitSet - add");
//添加到waitset
AddWaiter(&node);
//释放锁,代表现在线程已经进入了waitset,接下来要park了
Thread::SpinRelease(&_WaitSetLock);
if ((SyncFlags & 4) == 0) {
_Responsible = NULL;
}
intptr_t save = _recursions; // record the old recursion count
_waiters++; // increment the number of waiters
_recursions = 0; // set the recursion level to be 1
exit(true, Self); // exit the monitor
guarantee(_owner != Self, "invariant");
// 确保没有unpark事件冲突影响本次park,方法就是主动post一次unpark
if (node._notified != 0 && _succ == Self) {
node._event->unpark();
}
// 接下来就是park操作了
。。。。。。。。。
。。。。。。。。。
}
当另一个owner线程调用notify时,根据Knob_MoveNotifyee这个值,决定将从waitset里面取出的一个线程放到哪里(cxq或者EntrySet)
Object.notify()底层实现
void ObjectMonitor::notify(TRAPS) {
//检查当前线程是否拥有锁
CHECK_OWNER();
if (_WaitSet == NULL) {
TEVENT(Empty - Notify);
return;
}
DTRACE_MONITOR_PROBE(notify, this, object(), THREAD);
//决定取出来的线程放在哪里
int Policy = Knob_MoveNotifyee;
//同样的,用自旋方式获取操作waitset的lock
Thread::SpinAcquire(&_WaitSetLock, "WaitSet - notify");
ObjectWaiter *iterator = DequeueWaiter();
if (iterator != NULL) {
TEVENT(Notify1 - Transfer);
guarantee(iterator->TState == ObjectWaiter::TS_WAIT, "invariant");
guarantee(iterator->_notified == 0, "invariant");
if (Policy != 4) {
iterator->TState = ObjectWaiter::TS_ENTER;
}
iterator->_notified = 1;
Thread *Self = THREAD;
iterator->_notifier_tid = Self->osthread()->thread_id();
ObjectWaiter *List = _EntryList;
if (List != NULL) {
assert(List->_prev == NULL, "invariant");
assert(List->TState == ObjectWaiter::TS_ENTER, "invariant");
assert(List != iterator, "invariant");
}
if (Policy == 0) { // prepend to EntryList
if (List == NULL) {
iterator->_next = iterator->_prev = NULL;
_EntryList = iterator;
} else {
List->_prev = iterator;
iterator->_next = List;
iterator->_prev = NULL;
_EntryList = iterator;
}
} else if (Policy == 1) { // append to EntryList
if (List == NULL) {
iterator->_next = iterator->_prev = NULL;
_EntryList = iterator;
} else {
// CONSIDER: finding the tail currently requires a linear-time walk of
// the EntryList. We can make tail access constant-time by converting to
// a CDLL instead of using our current DLL.
ObjectWaiter *Tail;
for (Tail = List; Tail->_next != NULL; Tail = Tail->_next);
assert(Tail != NULL && Tail->_next == NULL, "invariant");
Tail->_next = iterator;
iterator->_prev = Tail;
iterator->_next = NULL;
}
} else if (Policy == 2) { // prepend to cxq
// prepend to cxq
if (List == NULL) {
iterator->_next = iterator->_prev = NULL;
_EntryList = iterator;
} else {
iterator->TState = ObjectWaiter::TS_CXQ;
for (;;) {
ObjectWaiter *Front = _cxq;
iterator->_next = Front;
if (Atomic::cmpxchg_ptr(iterator, &_cxq, Front) == Front) {
break;
}
}
}
} else if (Policy == 3) { // append to cxq
iterator->TState = ObjectWaiter::TS_CXQ;
for (;;) {
ObjectWaiter *Tail;
Tail = _cxq;
if (Tail == NULL) {
iterator->_next = NULL;
if (Atomic::cmpxchg_ptr(iterator, &_cxq, NULL) == NULL) {
break;
}
} else {
while (Tail->_next != NULL) Tail = Tail->_next;
Tail->_next = iterator;
iterator->_prev = Tail;
iterator->_next = NULL;
break;
}
}
} else {
ParkEvent *ev = iterator->_event;
iterator->TState = ObjectWaiter::TS_RUN;
OrderAccess::fence();
ev->unpark();
}
if (Policy < 4) {
iterator->wait_reenter_begin(this);
}
// _WaitSetLock protects the wait queue, not the EntryList. We could
// move the add-to-EntryList operation, above, outside the critical section
// protected by _WaitSetLock. In practice that's not useful. With the
// exception of wait() timeouts and interrupts the monitor owner
// is the only thread that grabs _WaitSetLock. There's almost no contention
// on _WaitSetLock so it's not profitable to reduce the length of the
// critical section.
}
//释放waitset的lock
Thread::SpinRelease(&_WaitSetLock);
if (iterator != NULL && ObjectMonitor::_sync_Notifications != NULL) {
ObjectMonitor::_sync_Notifications->inc();
}
}
对于NotifyAll就很好推测了,这里不再赘述;
(4)clone方法
默认的是浅拷贝,至于为什么,这里不赘述,我们直接看源码:
对于object的clone,我们需要考虑是否为数组,还有jvm环境等等,具体可以参考我的另一篇文章:垃圾收集分析(1)-Java对象结构(上)
void LibraryCallKit::copy_to_clone(Node* obj, Node* alloc_obj, Node* obj_size, bool is_array, bool card_mark) {
//首先做一些基本判断,例如对象不为空
assert(obj_size != NULL, "");
Node* raw_obj = alloc_obj->in(1);
assert(alloc_obj->is_CheckCastPP() && raw_obj->is_Proj() && raw_obj->in(0)->is_Allocate(), "");
AllocateNode* alloc = NULL;
if (ReduceBulkZeroing) {
// We will be completely responsible for initializing this object -
// mark Initialize node as complete.
alloc = AllocateNode::Ideal_allocation(alloc_obj, &_gvn);
// The object was just allocated - there should be no any stores!
guarantee(alloc != NULL && alloc->maybe_set_complete(&_gvn), "");
// Mark as complete_with_arraycopy so that on AllocateNode
// expansion, we know this AllocateNode is initialized by an array
// copy and a StoreStore barrier exists after the array copy.
alloc->initialization()->set_complete_with_arraycopy();
}
//分配初始指针
Node* src = obj;
Node* dest = alloc_obj;
Node* size = _gvn.transform(obj_size);
// 根据是否为数组决定对象头结构
int base_off = is_array ? arrayOopDesc::length_offset_in_bytes() :
instanceOopDesc::base_offset_in_bytes();
// base_off:
// 8 - 32-bit VM
// 12 - 64-bit VM, compressed klass
// 16 - 64-bit VM, normal klass
if (base_off % BytesPerLong != 0) {
assert(UseCompressedClassPointers, "");
if (is_array) {
// Exclude length to copy by 8 bytes words.
base_off += sizeof(int);
} else {
// Include klass to copy by 8 bytes words.
base_off = instanceOopDesc::klass_offset_in_bytes();
}
assert(base_off % BytesPerLong == 0, "expect 8 bytes alignment");
}
src = basic_plus_adr(src, base_off);
dest = basic_plus_adr(dest, base_off);
// Compute the length also, if needed:
Node* countx = size;
countx = _gvn.transform(new (C) SubXNode(countx, MakeConX(base_off)));
countx = _gvn.transform(new (C) URShiftXNode(countx, intcon(LogBytesPerLong) ));
const TypePtr* raw_adr_type = TypeRawPtr::BOTTOM;
bool disjoint_bases = true;
generate_unchecked_arraycopy(raw_adr_type, T_LONG, disjoint_bases,
src, NULL, dest, NULL, countx,
/*dest_uninitialized*/true);
// If necessary, emit some card marks afterwards. (Non-arrays only.)
if (card_mark) {
assert(!is_array, "");
// Put in store barrier for any and all oops we are sticking
// into this object. (We could avoid this if we could prove
// that the object type contains no oop fields at all.)
Node* no_particular_value = NULL;
Node* no_particular_field = NULL;
int raw_adr_idx = Compile::AliasIdxRaw;
post_barrier(control(),
memory(raw_adr_type),
alloc_obj,
no_particular_field,
raw_adr_idx,
no_particular_value,
T_OBJECT,
false);
}
// Do not let reads from the cloned object float above the arraycopy.
if (alloc != NULL) {
// Do not let stores that initialize this object be reordered with
// a subsequent store that would make this object accessible by
// other threads.
// Record what AllocateNode this StoreStore protects so that
// escape analysis can go from the MemBarStoreStoreNode to the
// AllocateNode and eliminate the MemBarStoreStoreNode if possible
// based on the escape status of the AllocateNode.
insert_mem_bar(Op_MemBarStoreStore, alloc->proj_out(AllocateNode::RawAddress));
} else {
insert_mem_bar(Op_MemBarCPUOrder);
}
}
(5) finalize()方法——对象的回收
当确定一个对象不会被其他方法再使用时,该对象就没有存在的意义了,就只能等待JVM的垃圾回收线程来回收了。垃圾回收是以占用一定内存资源为代价的。System.gc();就是启动垃圾回收线程的语句。当用户认为需要回收时,可以使用Runtime.getRuntime( ).gc( );或者System.gc();来回收内存。(System.gc();调用的就是Runtime类的gc( )方法)
当一个对象在回收前想要执行一些操作,就要覆写Object类中的finalize( )方法。
protected void finalize() throws Throwable { }
注意到抛出的是Throwable,说明除了常规的异常Exceprion外,还有可能是JVM错误。说明调用该方法不一定只会在程序中产生异常,还有可能产生JVM错误。










