
我在 hibernate,mybatis,beetlsql 全面比较 中说明了BeetlSQL 在开发效率,维护性,跨数据库等各指标全面比hibernate 占优,但在ORM 方面不如Hibernate,这么多年来,hibernate已经成为Java的 ORMapping事实上的标准和方向,但我也在文章中指出,通过注解Annotation能指明java实体类的关系,但通过注解不能阐述所有的ORM查询,比如,我想查询跟订单关联的所有有效子订单,而不是所有子订单。 注解的表现力在ORMapping 中越来越不足,也使得大量ORMapping工具通过别的方式来实现ORM查询,让我们看看BeeetlSQL 新增的ORM查询是如何简单灵活的实现ORM查询的。
如下一个常用场景,以用户为中心,一个用户关联到多个订单,一个用户属于一个部门,用户和角色是多对多的关系。这个场景涉及到了一对一,一对多,多对多。让我们看看BeetlSQL是如何轻松实现 ORM查询的。(不想看文字直接看代码的可以访问 https://code.csdn.net/xiandafu/beetlsql_orm_sample/tree/master)
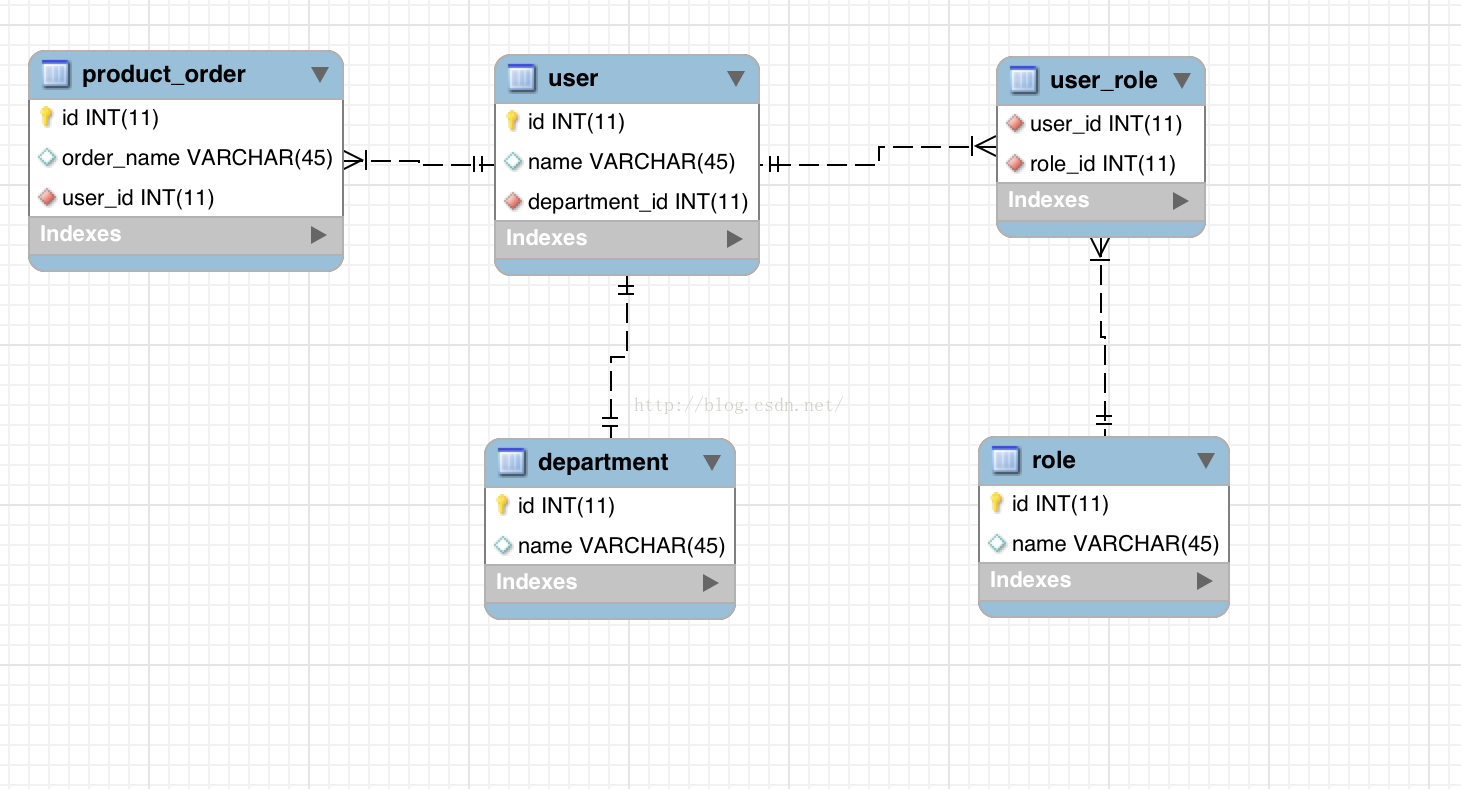
BeetSQL 实现ORM查询是在sql查询语句里使用orm.single,orm.many 俩个函数,如下例子(位于src/main/resource/sql/user.md)
queryUsers
===
select #page("*")# from user where 1=1
@if(!isEmpty()){
and name=#name#
@}
@ orm.single({"departmentId":"id"},"Department");
@ orm.many({"id":"userId"},"ProductOrder");
@ orm.many({"id":"userId"},"user.selectRole","Role");
queryUsers 是一个普通的sql查询,查询所有的用户,使用page函数来用于翻页查询,page函数可以转化成select count(1) 或者 select *,如果你不了解beetlsql 或者 支持的翻页查询函数page,可以查看beetlsql的文档,大概需要一早上就能看完。
这个普通的sql语句查询里,有使用了orm查询函数。一行一行解释如下:
orm.single({"departmentId":"id"},"Department");
single 说明user对象一对一关联到第二个参数指明的类Department。关联方式是将user对象的departmentId 属性 映射为Department的id属性。使用了 {“departmentId”:"id"},
beetlsql 看到此函数调用,将会在Department对象里发起一次单表查询,
第二个many也使用同样的方式查询ProudctOrder,关联方式是讲user对象的id属性映射到到ProductOrder 的userId属性
第三个many 是使用了一个sql查询user.selectRole 来查询用户关联的角色,输入的参数是将user的属性id映射为变量userId,传给user.selectRole查询语句
,通过查询user_role 和 role 表,语句如下
selectRole
===
select r.* from user_role ur, role r where ur.role_id=r.id and ur.user_id=#userId#
orm函数可以放到sql语句的任何地方,建议放到sql语句开始部分或者结束部分,orm函数本身不影响sql语句,他只是记录了一下映射关系配置,然后在BeetSQL查询完毕后,发现如果有映射关系存在,再发起额外的ORM查询。
因为支持了ORM查询,User对象也需要改动,但不像hibernate那样,必须显示的增加Role,Department,ProudctOrder属性,BeetSQL不需要那么做,BeetSQL有个概念叫Tail属性,意思是在sql查询中,映射不到Pojo的字段的其他sql查询结果可以放到tail里,本质上是一个Map。实现tail方式有三种,User对象采用最简单的方式,User继承TailBean,代码如下:
public class User extends TailBean {
private Integer id ;
private String name ;
private Integer departmentId;
public User() {
}
因此,上面orm查询结果将放到tail属性里,其引用的名字默认是类首字母小写开头,即department,productOrder,role。 整个java代码如下
UserDao userDao = sql.getMapper(UserDao.class);
//翻页查询
PageQuery query = new PageQuery();
// 查询user.md里面的user.queryUsers
userDao.queryUsers(query);
List
list = query.getList(); for(User user:list){
//关联订单
List
orders = (List )user.get("productOrder"); //关联部门
Department dept = (Department)user.get("department");
System.out.println("user:"+user.getName()+" department:"+dept.getName()+ " order total:"+orders.size());
//关联角色
List
roles = (List )user.get("role"); for(Role role:roles){
System.out.println("====role:"+role.getName());
}
}
如果你对Beetlsql 不熟悉,请参看官方文档,大概需要半天时间就能有初步掌握,比学其他ORM工具快多了
BeetlSQL 的ORM查询就这点新鲜知识,实现起来非常简单且功能强大,而且,也很好理解,正是我们熟悉的的ORM查询思路。另外,他比基于注解的ORM查询灵活太多了而又没有任何副作用。是一种非常棒的ORM查询方式。尽管BeetlSQL 一直宣称自己是个DAO工具而非ORM框架,但通过orm 函数,也能轻易实现其他ORM框架的功能。
如果你有兴趣了解BeetlSQl,可以查阅网站ibeetl.com,你可以直接访问 https://code.csdn.net/xiandafu/beetlsql_orm_sample/tree/master 下载代码尝试运行近一步了解BeetSQL.











