
满目山河空念远,落花风雨更伤春。

ClickHouse概述
什么是ClickHouse?
ClickHouse 是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
什么是列式存储 ?
以下面表为例
id
website
wechat
1
https://niocoder.com/
java干货
2
http://www.merryyou.cn/
javaganhuo
采用行式存储时,数据在磁盘上的组织结构为:
Row1
Row2
1
https://niocoder.com/
java干货
2
http://www.merryyou.cn/
javaganhuo
好处是想查某条记录所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有记录wechat时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
而采用列式存储时,数据在磁盘上的组织结构为:
col1
col2
col3
1
2
https://niocoder.com/
http://www.merryyou.cn/
java干货
javaganhuo
这时想查所有记录的wechat只需把col3那一列拿出来即可。
集群环境搭建
在 安装ClickHouse 具体开始前, 先来搭建一下环境,软件包下载见末尾。
创建虚拟机
安装虚拟机 VMWare
安装Vmware虚拟机
导入 CentOS
将下载的CentOS系统中导入到 VMWare中
注意事项:windows系统确认所有的关于VmWare的服务都已经启动,
确认好VmWare生成的网关地址,另外确认VmNet8网卡已经配置好了IP地址。
更多关于VmWare网络模式参考VMware虚拟机三种网络模式详解
集群规划
IP
主机名
环境配置
安装
ClickHouse
192.168.10.100
node01
关防火墙, host映射, 时钟同步
JDK, Zookeeper
clickhouse-server 9000 clickhouse-server 9001
192.168.10.110
node02
关防火墙, host映射, 时钟同步
JDK, Zookeeper
clickhouse-server 9000 clickhouse-server 9001
192.168.10.120
node03
关防火墙, host映射, 时钟同步
JDK, Zookeeper
clickhouse-server 9000 clickhouse-server 9001
配置每台主机
更改ip地址和HWADDR地址
vim /etc/sysconfig/network-scripts/ifcfg-eth0
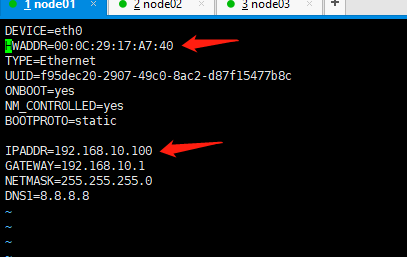
HWADDR地址查看
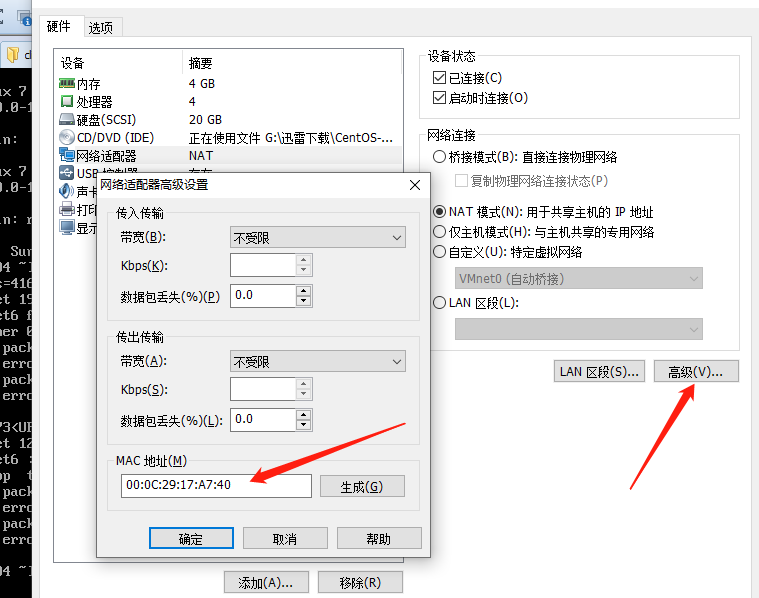
修改主机名(重启后永久生效)
vim /etc/hostname
设置hosts域名映射
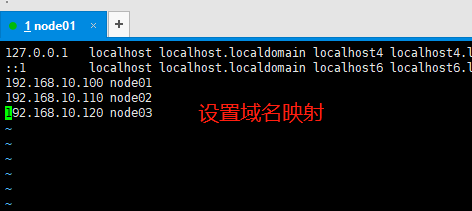
vim /etc/hosts
关闭防火墙
三台机器执行以下命令
systemctl status firewalld.service #查看防火墙状态 systemctl stop firewalld.service #关闭防火墙 systemctl disable firewalld.service #永久关闭防火墙
免密登录
为了方便传输文件,三台机器之前配置免密登录.
- 免密 SSH 登录的原理
- 需要先在 B节点 配置 A节点 的公钥
- A节点 请求 B节点 要求登录
- B节点 使用 A节点 的公钥, 加密一段随机文本
- A节点 使用私钥解密, 并发回给 B节点
- B节点 验证文本是否正确
三台机器生成公钥与私钥
在三台机器执行以下命令,生成公钥与私钥
ssh-keygen -t rsa
执行该命令之后,按下三个回车即可
拷贝公钥到node01机器
三台机器将拷贝公钥到node01机器
三台机器执行命令:
ssh-copy-id node01
复制node01机器的认证到其他机器
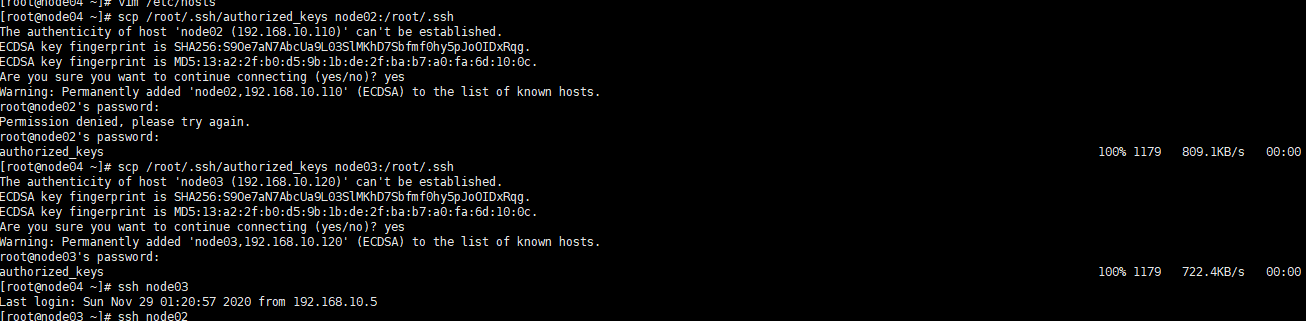
将第一台机器的公钥拷贝到其他机器上
在node01机器上面执行以下命令
scp /root/.ssh/authorized_keys node02:/root/.ssh
scp /root/.ssh/authorized_keys node03:/root/.ssh
设置时钟同步服务
为什么需要时间同步
- 因为很多分布式系统是有状态的, 比如说存储一个数据, A节点 记录的时间是 1, B节点 记录的时间是 2, 就会出问题
安装
yum install -y ntp
启动定时任务
crontab -e
随后在输入界面键入
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
安装JDK
上传jdk并解压然后配置环境变量
所有软件的安装路径
mkdir -p /export/servers #node01,node02,node03机器上执行
所有软件压缩包的存放路径
mkdir -p /export/softwares # 创建文件夹
安装rz和sz命令
yum -y install lrzsz # 安装rz sz 命令
上传jdk安装包到/export/softwares路径下去,并解压
tar -zxvf jdk-8u141-linux-x64.tar.gz -C ../servers/
配置环境变量
vim /etc/profile
export JAVA_HOME=/export/servers/jdk1.8.0_141
export PATH=:$JAVA_HOME/bin:$PATH
执行以下命令将jdk安装包分发到node02和node03节点上
scp -r /export/servers/jdk1.8.0_141/ node02:/export/servers/ scp -r /export/servers/jdk1.8.0_141/ node03:/export/servers/ scp /etc/profile node02:/etc/profile scp /etc/profile node03:/etc/profile
刷新环境变量
source /etc/profile
安装Zookeeper
服务器IP
主机名
myid的值
192.168.10.100
node01
1
192.168.10.110
node02
2
192.168.10.120
node03
3
上传zookeeper安装包到/export/softwares路径下去,并解压
tar -zxvf zookeeper-3.4.9.tar.gz -C ../servers/
node01修改配置文件如下
cd /export/servers/zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg
# 创建数据存放节点
mkdir -p /export/servers/zookeeper-3.4.9/zkdatas/
vim zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkdatas
# 保留多少个快照
autopurge.snapRetainCount=3
# 日志多少小时清理一次
autopurge.purgeInterval=1
# 集群中服务器地址
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
在node01机器上
/export/servers/zookeeper-3.4.9/zkdatas/这个路径下创建一个文件,文件名为myid ,文件内容为1
echo 1 > /export/servers/zookeeper-3.4.9/zkdatas/myid
安装包分发到其他机器
node01机器上面执行以下两个命令
scp -r /export/servers/zookeeper-3.4.9/ node02:/export/servers/
scp -r /export/servers/zookeeper-3.4.9/ node03:/export/servers/
node02机器上修改myid的值为2
echo 2 > /export/servers/zookeeper-3.4.9/zkdatas/myid
node03机器上修改myid的值为3
echo 3 > /export/servers/zookeeper-3.4.9/zkdatas/myid
启动zookeeper服务
node01,node02,node03机器都要执行
/export/servers/zookeeper-3.4.9/bin/zkServer.sh start
查看启动状态
/export/servers/zookeeper-3.4.9/bin/zkServer.sh status
安装前准备
CPU是否支持SSE4.2
查看CPU是否支持SSE4.2指令集
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
安装必要依赖
yum install -y unixODBC libicudata
yum install -y libxml2-devel expat-devel libicu-devel
安装ClickHouse
单机模式
上传4个文件到node01机器/opt/software/
[root@node01 softwares]# ll
total 306776
-rw-r--r--. 1 root root 6384 Nov 2 22:43 clickhouse-client-20.8.3.18-1.el7.x86_64.rpm
-rw-r--r--. 1 root root 69093220 Nov 2 22:48 clickhouse-common-static-20.8.3.18-1.el7.x86_64.rpm
-rw-r--r--. 1 root root 36772044 Nov 2 22:51 clickhouse-server-20.8.3.18-1.el7.x86_64.rpm
-rw-r--r--. 1 root root 14472 Nov 2 22:43 clickhouse-server-common-20.8.3.18-1.el7.x86_64.rpm
分别安装这4个rpm安装包
[root@node01 softwares]# rpm -ivh clickhouse-common-static-20.8.3.18-1.el7.x86_64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:clickhouse-common-static-20.8.3.1################################# [100%]
[root@node01 softwares]# rpm -ivh clickhouse-server-common-20.8.3.18-1.el7.x86_64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:clickhouse-server-common-20.8.3.1################################# [100%]
[root@node01 softwares]# rpm -ivh clickhouse-server-20.8.3.18-1.el7.x86_64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:clickhouse-server-20.8.3.18-1.el7################################# [100%]
Create user clickhouse.clickhouse with datadir /var/lib/clickhouse
[root@node01 softwares]# rpm -ivh clickhouse-client-20.8.3.18-1.el7.x86_64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:clickhouse-client-20.8.3.18-1.el7################################# [100%]
Create user clickhouse.clickhouse with datadir /var/lib/clickhouse
rpm安装完毕后,clickhouse-server和clickhouse-client配置目录如下
[root@node01 softwares]# ll /etc/clickhouse-server/
total 44
-rw-r--r--. 1 root root 33738 Oct 6 06:05 config.xml
-rw-r--r--. 1 root root 5587 Oct 6 06:05 users.xml
[root@node01 softwares]# ll /etc/clickhouse-client/
total 4
drwxr-xr-x. 2 clickhouse clickhouse 6 Nov 28 22:19 conf.d
-rw-r--r--. 1 clickhouse clickhouse 1568 Oct 6 04:44 config.xml
/etc/clickhouse-server/的config.xml为ClickHouse核心配置文件,主要内容如下
<?xml version="1.0"?>
<yandex>
<!-- 日志 -->
<logger>
<level>trace</level>
<log>/data1/clickhouse/log/server.log</log>
<errorlog>/data1/clickhouse/log/error.log</errorlog>
<size>1000M</size>
<count>10</count>
</logger>
<!-- 端口 -->
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<interserver_http_port>9009</interserver_http_port>
<!-- 本机域名 -->
<interserver_http_host>这里需要用域名,如果后续用到复制的话</interserver_http_host>
<!-- 监听IP -->
<listen_host>0.0.0.0</listen_host>
<!-- 最大连接数 -->
<max_connections>64</max_connections>
<!-- 没搞懂的参数 -->
<keep_alive_timeout>3</keep_alive_timeout>
<!-- 最大并发查询数 -->
<max_concurrent_queries>16</max_concurrent_queries>
<!-- 单位是B -->
<uncompressed_cache_size>8589934592</uncompressed_cache_size>
<mark_cache_size>10737418240</mark_cache_size>
<!-- 存储路径 -->
<path>/data1/clickhouse/</path>
<tmp_path>/data1/clickhouse/tmp/</tmp_path>
<!-- user配置 -->
<users_config>users.xml</users_config>
<default_profile>default</default_profile>
<log_queries>1</log_queries>
<default_database>default</default_database>
<remote_servers incl="clickhouse_remote_servers" />
<zookeeper incl="zookeeper-servers" optional="true" />
<macros incl="macros" optional="true" />
<!-- 没搞懂的参数 -->
<builtin_dictionaries_reload_interval>3600</builtin_dictionaries_reload_interval>
<!-- 控制大表的删除 -->
<max_table_size_to_drop>0</max_table_size_to_drop>
<include_from>/data1/clickhouse/metrika.xml</include_from>
</yandex>
启动ClickHouse
[root@node01 softwares]# service clickhouse-server start
Start clickhouse-server service: Path to data directory in /etc/clickhouse-server/config.xml: /var/lib/clickhouse/
DONE
[root@node01 softwares]#
使用client链接server
[root@node01 softwares]# clickhouse-client -m
ClickHouse client version 20.8.3.18.
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 20.8.3 revision 54438.
node01 :) show databases;
SHOW DATABASES
┌─name───────────────────────────┐
│ _temporary_and_external_tables │
│ default │
│ system │
└────────────────────────────────┘
3 rows in set. Elapsed: 0.007 sec.
node01 :) select 1;
SELECT 1
┌─1─┐
│ 1 │
└───┘
1 rows in set. Elapsed: 0.005 sec.
node01 :)
分布式集群安装
在node02,node03上面执行之前的所有的操作
node01机器修改配置文件config.xml
[root@node01 softwares]# vim /etc/clickhouse-server/config.xml
<!-- 打开这个 -->
<listen_host>::</listen_host>
<!-- Same for hosts with disabled ipv6: -->
<!-- <listen_host>0.0.0.0</listen_host> -->
<!-- 新增外部配置文件metrika.xml -->
<include_from>/etc/clickhouse-server/metrika.xml</include_from>
将修改后的配置分发到node02,node03机器上
scp config.xml node02:/etc/clickhouse-server/config.xml
scp config.xml node03:/etc/clickhouse-server/config.xml
node01机器/etc/clickhouse-server/目录下创建metrika.xml文件
<yandex>
<!-- 集群配置 -->
<clickhouse_remote_servers>
<!-- 3分片1备份 -->
<cluster_3shards_1replicas>
<!-- 数据分片1 -->
<shard>
<replica>
<host>node01</host>
<port>9000</port>
</replica>
</shard>
<!-- 数据分片2 -->
<shard>
<replica>
<host>node02</host>
<port> 9000</port>
</replica>
</shard>
<!-- 数据分片3 -->
<shard>
<replica>
<host>node03</host>
<port>9000</port>
</replica>
</shard>
</cluster_3shards_1replicas>
</clickhouse_remote_servers>
</yandex>
配置说明
cluster_3shards_1replicas集群名称,可随意定义- 共设置3个分片,每个分片只有1个副本;
将metrika.xml配置文件分发到node02,node03机器上
scp metrika.xml node02:/etc/clickhouse-server/metrika.xml
scp metrika.xml node03:/etc/clickhouse-server/metrika.xml
重启ClickHouse-server 打开client查看集群
[root@node01 clickhouse-server]# service clickhouse-server restart
Stop clickhouse-server service: DONE
Start clickhouse-server service: Path to data directory in /etc/clickhouse-server/config.xml: /var/lib/clickhouse/
DONE
[root@node01 clickhouse-server]# clickhouse-client -m
ClickHouse client version 20.8.3.18.
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 20.8.3 revision 54438.
node01 :) select * from system.clusters;
SELECT *
FROM system.clusters
┌─cluster───────────────────────────┬─shard_num─┬─shard_weight─┬─replica_num─┬─host_name─┬─host_address───┬─port─┬─is_local─┬─user────┬─default_database─┬─errors_count─┬─estimated_recovery_time─┐
│ cluster_3shards_1replicas │ 1 │ 1 │ 1 │ node01 │ 192.168.10.100 │ 9000 │ 1 │ default │ │ 0 │ 0 │
│ cluster_3shards_1replicas │ 2 │ 1 │ 1 │ node02 │ 192.168.10.110 │ 9000 │ 0 │ default │ │ 0 │ 0 │
│ cluster_3shards_1replicas │ 3 │ 1 │ 1 │ node03 │ 192.168.10.120 │ 9000 │ 0 │ default │ │ 0 │ 0 │
│ test_cluster_two_shards │ 1 │ 1 │ 1 │ 127.0.0.1 │ 127.0.0.1 │ 9000 │ 1 │ default │ │ 0 │ 0 │
│ test_cluster_two_shards │ 2 │ 1 │ 1 │ 127.0.0.2 │ 127.0.0.2 │ 9000 │ 0 │ default │ │ 0 │ 0 │
│ test_cluster_two_shards_localhost │ 1 │ 1 │ 1 │ localhost │ ::1 │ 9000 │ 1 │ default │ │ 0 │ 0 │
│ test_cluster_two_shards_localhost │ 2 │ 1 │ 1 │ localhost │ ::1 │ 9000 │ 1 │ default │ │ 0 │ 0 │
│ test_shard_localhost │ 1 │ 1 │ 1 │ localhost │ ::1 │ 9000 │ 1 │ default │ │ 0 │ 0 │
│ test_shard_localhost_secure │ 1 │ 1 │ 1 │ localhost │ ::1 │ 9440 │ 0 │ default │ │ 0 │ 0 │
│ test_unavailable_shard │ 1 │ 1 │ 1 │ localhost │ ::1 │ 9000 │ 1 │ default │ │ 0 │ 0 │
│ test_unavailable_shard │ 2 │ 1 │ 1 │ localhost │ ::1 │ 1 │ 0 │ default │ │ 0 │ 0 │
└───────────────────────────────────┴───────────┴──────────────┴─────────────┴───────────┴────────────────┴──────┴──────────┴─────────┴──────────────────┴──────────────┴─────────────────────────┘
11 rows in set. Elapsed: 0.008 sec. │ 0 │
可以看到cluster_3shards_1replicas就是我们定义的集群名称,一共有三个分片,每个分片有一份数据。剩下的为配置文件默认自带的集群配置.
测试分布式集群
在node01,node02,node03上分别创建本地表cluster3s1r_local
CREATE TABLE default.cluster3s1r_local
(
`id` Int32,
`website` String,
`wechat` String,
`FlightDate` Date,
Year UInt16
)
ENGINE = MergeTree(FlightDate, (Year, FlightDate), 8192);
在node01节点上创建分布式表
CREATE TABLE default.cluster3s1r_all AS cluster3s1r_local
ENGINE = Distributed(cluster_3shards_1replicas, default, cluster3s1r_local, rand());
往分布式表cluster3s1r_all插入数据,cluster3s1r_all 会随机插入到三个节点的cluster3s1r_local里
插入数据
INSERT INTO default.cluster3s1r_all (id,website,wechat,FlightDate,Year)values(1,'https://niocoder.com/','java干货','2020-11-28',2020);
INSERT INTO default.cluster3s1r_all (id,website,wechat,FlightDate,Year)values(2,'http://www.merryyou.cn/','javaganhuo','2020-11-28',2020);
INSERT INTO default.cluster3s1r_all (id,website,wechat,FlightDate,Year)values(3,'http://www.xxxxx.cn/','xxxxx','2020-11-28',2020);
查询分布式表和本地表
node01 :) select * from cluster3s1r_all; # 查询总量查分布式表
SELECT *
FROM cluster3s1r_all
┌─id─┬─website─────────────────┬─wechat─────┬─FlightDate─┬─Year─┐
│ 2 │ http://www.merryyou.cn/ │ javaganhuo │ 2020-11-28 │ 2020 │
└────┴─────────────────────────┴────────────┴────────────┴──────┘
┌─id─┬─website──────────────┬─wechat─┬─FlightDate─┬─Year─┐
│ 3 │ http://www.xxxxx.cn/ │ xxxxx │ 2020-11-28 │ 2020 │
└────┴──────────────────────┴────────┴────────────┴──────┘
┌─id─┬─website───────────────┬─wechat───┬─FlightDate─┬─Year─┐
│ 1 │ https://niocoder.com/ │ java干货 │ 2020-11-28 │ 2020 │
└────┴───────────────────────┴──────────┴────────────┴──────┘
3 rows in set. Elapsed: 0.036 sec.
node01 :) select * from cluster3s1r_local; # node01本地表
SELECT *
FROM cluster3s1r_local
┌─id─┬─website─────────────────┬─wechat─────┬─FlightDate─┬─Year─┐
│ 2 │ http://www.merryyou.cn/ │ javaganhuo │ 2020-11-28 │ 2020 │
└────┴─────────────────────────┴────────────┴────────────┴──────┘
1 rows in set. Elapsed: 0.012 sec.
node02 :) select * from cluster3s1r_local; # node02本地表
SELECT *
FROM cluster3s1r_local
Ok.
0 rows in set. Elapsed: 0.016 sec.
node03 :) select * from cluster3s1r_local; ## node03 本地表
SELECT *
FROM cluster3s1r_local
┌─id─┬─website──────────────┬─wechat─┬─FlightDate─┬─Year─┐
│ 3 │ http://www.xxxxx.cn/ │ xxxxx │ 2020-11-28 │ 2020 │
└────┴──────────────────────┴────────┴────────────┴──────┘
┌─id─┬─website───────────────┬─wechat───┬─FlightDate─┬─Year─┐
│ 1 │ https://niocoder.com/ │ java干货 │ 2020-11-28 │ 2020 │
└────┴───────────────────────┴──────────┴────────────┴──────┘
2 rows in set. Elapsed: 0.006 sec.
下载

关注微信公众号java干货回复 【clickhouse】











