1、主从架构的核心原理
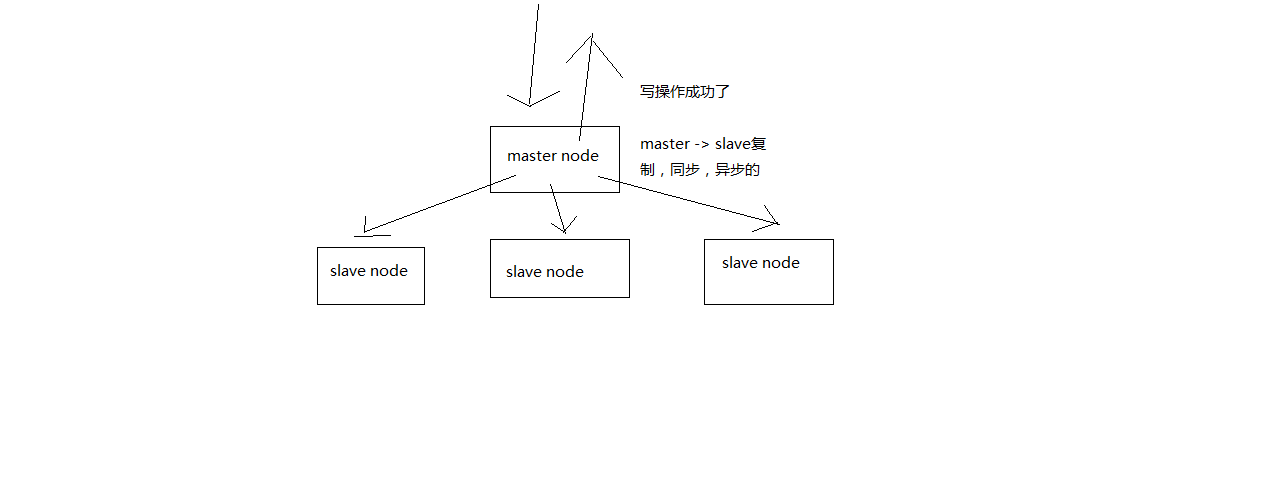
当启动一个slave node的时候,它会发送一个PSYNC命令给master node
如果这是slave node重新连接master node,那么master node仅仅会复制给slave部分缺少的数据; 否则如果是slave node第一次连接master node,那么会触发一次full resynchronization
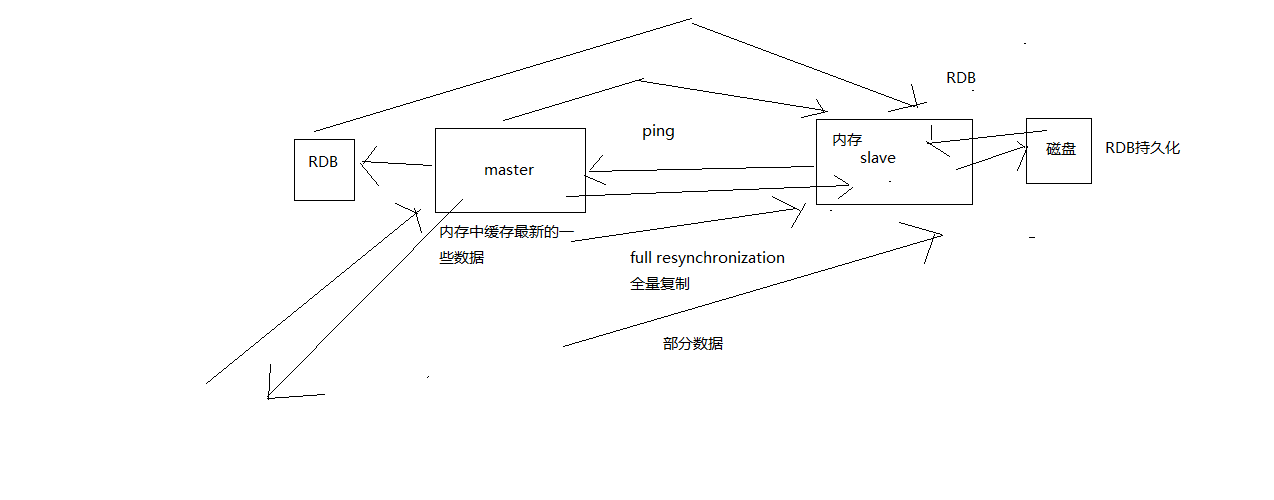
开始full resynchronization的时候,master会启动一个后台线程,开始生成一份RDB快照文件,同时还会将从客户端收到的所有写命令缓存在内存中。RDB文件生成完毕之后,master会将这个RDB发送给slave,slave会先写入本地磁盘,然后再从本地磁盘加载到内存中。然后master会将内存中缓存的写命令发送给slave,slave也会同步这些数据。
slave node如果跟master node有网络故障,断开了连接,会自动重连。master如果发现有多个slave node都来重新连接,仅仅会启动一个rdb save操作,用一份数据服务所有slave node。
 、
、
2、主从复制的断点续传
从redis 2.8开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制一份
master node会在内存中常见一个backlog,master和slave都会保存一个replica offset还有一个master id,offset就是保存在backlog中的。如果master和slave网络连接断掉了,slave会让master从上次的replica offset开始继续复制
但是如果没有找到对应的offset,那么就会执行一次resynchronization
3、无磁盘化复制
master在内存中直接创建rdb,然后发送给slave,不会在自己本地落地磁盘了
repl-diskless-sync
repl-diskless-sync-delay,等待一定时长再开始复制,因为要等更多slave重新连接过来
4、过期key处理
slave不会过期key,只会等待master过期key。如果master过期了一个key,或者通过LRU淘汰了一个key,那么会模拟一条del命令发送给slave。