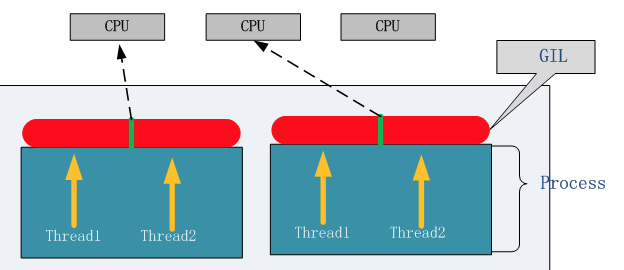
一.GIL锁
什么是GIL? 全局解释器锁,是加在解释器上的互斥锁
GC是python自带的内存管理机制,GC的工作原理:python中的内存管理使用的是应用计数,每个数会被加上一个整型的计数器,表示这个数据被引用的次数,当这个整数变为0时则表示该数据已经没有人使用,成为了垃圾数据,当内存占用达到某个阈值,GC会将其他线程挂起,然后执行垃圾清理操作,垃圾清理也是一串代码,也就需要一条线程来执行.
为什么需要GIL?
由于CPython的内存管理机制是非线程安全,于是CPython就给解释器加了一个锁,解决了安全问题,但是降低了效率,另外,虽然有解决方案,但是由于牵涉太多,一旦修改则很多基于GIL的程序都需要修改,所以变成了历史遗留问题.
GIL加锁,解锁的时机?
加锁时机:在调用解释器时立即加锁
解锁时机:①当前线程遇到IO时释放 ②当前线程执行时间超过设定值时释放,解释器会检测线程的执行时间,一旦到达某个阈值,通知线程保存状态切换线程.
GIL带来的问题:即使是多核处理器下也无法真正的并行.
总结:
①在单核情况下,无论是IO密集型还是计算密集型,GIL都不会产生影响,而多线程开销小,并且节约资源,所以使用多线程.
②在多核情况下,IO密集型会受到GIL的影响,但是很明显IO速度远比计算速度慢,所以两者执行的时间差不多,基本可以忽略不计,而在这个情况下我们考虑到多线程开销小,并且节约资源,所以多核情况下,IO密集型我们使用多线程.
③对于计算密集型,在多核情况下,CPython中多线程是无法并行的,为了解决这一弊端,Python推出了多进程技术,可以良好的利用多核处理器来完成计算的任务.
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
多进程与多线程效率对比:
现在的电脑都是多核系统
#多进程解决计算密集型
from multiprocessing import Process
import time
a = 10
def task():
for i in range(10000000):
global a
a +=1
a*10/2-3
if __name__ == '__main__':
start = time.time()
ps = []
for i in range(3):
p = Process(target=task)
p.start()
ps.append(p)
for p in ps:
p.join()
print(time.time()-start)
结果:5.455920934677124
#多线程解决计算密集型
from threading import Thread
import time
a = 10
def task():
for i in range(10000000):
global a
a +=1
a*10/2-3
if __name__ == '__main__':
start = time.time()
ts = []
for i in range(3):
t = Thread(target=task)
t.start()
ts.append(t)
for t in ts:
t.join()
print(time.time()-start)
结果:8.375339031219482
#多进程解决IO密集型
from multiprocessing import Process
import time
def task():
path =r'E:\python试学视频\day27、28选课系统\11 测试程序2.mp4'
with open(path,mode='rb') as f:
while True:
data = f.read(1024)
if not data:
break
if __name__ == '__main__':
start = time.time()
ps = []
for i in range(3):
p = Process(target=task)
p.start()
ps.append(p)
for p in ps:
p.join()
print(time.time()-start)
结果:0.3124856948852539
#多线程解决IO密集型
from threading import Thread
import time
a = 10
def task():
path =r'E:\python试学视频\day27、28选课系统\11 测试程序2.mp4'
with open(path,mode='rb') as f:
while True:
data = f.read(1024)
if not data:
break
if __name__ == '__main__':
start = time.time()
ts = []
for i in range(3):
t = Thread(target=task)
t.start()
ts.append(t)
for t in ts:
t.join()
print(time.time()-start)
结果:0.1250016689300537
二.GIL锁与自定义锁的区别
GIL是用于保护解释器相关的数据,解释器也是一段程序,肯定有其定义的各种数据
GIL并不能保证自己定义的数据的安全,所以当程序中出现多线程共享数据的时候就需要自定义加锁.
三.线程池与进程池
什么是进程池/线程池?
池表示是一个容器,本质就是一个存储进程或线程的列表
IO密集型使用线程池,计算密集型使用进程池
为什么需要线程池/进程池?
很多情况下需要控制进程或者线程在一个合理的范围内,线程/进程池不仅帮我们控制线程/进程的数量,还帮我们完成了线程/进程的创建,销毁,以及任务的分配
线程池的使用:
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread,active_count
import time
#创建线程池,指定最大线程数为3 如果不指定 默认为cpu核心数*5
pool = ThreadPoolExecutor(3) #不会立即开启子线程
def task():
print('%s running..'%current_thread().name)
print(active_count())
time.sleep(2)
#提交任务到线程池
for i in range(10):
pool.submit(task)
进程池的使用:
from concurrent.futures import ProcessPoolExecutor
import time,os
#创建进程池,最大进程数为3,默认为cpu个数
pool = ProcessPoolExecutor(3)#不会立即开启子进程
def task():
print('%s running..'%os.getpid())
time.sleep(2)
if __name__ == '__main__':
#提交任务到进程池
for i in range(10):
pool.submit(task)
#第一次提交任务时会创建进程后续提交任务直接交给已经存在的进程来完成,如果没有空闲进程就等待
结果:
1464 running..
11732 running..
8236 running..
1464 running..
11732 running..
8236 running..
1464 running..
11732 running..
8236 running..
1464 running..
案例:TCP中的应用
首先要明确,TCP是IO密集型,应该使用线程池
#多线程TCP服务器
from concurrent.futures import ThreadPoolExecutor
import socket
server = socket.socket()
server.bind(('192.168.12.207',4396))
server.listen()
pool = ThreadPoolExecutor(3) #线程池,控制可以连接到服务器的客户端的个数
def task(client):
while True:
try:
data = client.recv(1024)
if not data:
client.close()
break
client.send(data.upper())
except ConnectionResetError:
client.close()
break
while True:
client,addr = server.accept()
t = pool.submit(task,client)
#多线程TCP客户端
#使用多线程是为了可以一直输入,不用等输出了才可以输入
from threading import Thread
import socket
client = socket.socket()
client.connect(('192.168.12.207',4396))
def send_msg():
while True:
msg = input('>>:').strip()
if not msg:
continue
client.send(msg.encode('utf-8'))
send_t = Thread(target=send_msg)
send_t.start()
while True:
try: #这个也要自定义抛出异常,如果服务器终止,客户端也会报错
data = client.recv(1024)
print(data.decode('utf-8'))
except:
client.close()
break
与信号量的区别:
信号量也是一种锁,适用于保证同一时间能有多少个进程或线程访问
而线程池和进程池,没有对数据访问进行限制仅仅是控制数量
四.同步与异步
同步(调用/执行/任务/提交),发起任务后必须等待任务结束,拿到一个结果才能继续运行
异步 发起任务后不需要关系任务的执行过程,可以继续往下运行,但还是需要结果
异步效率高于同步但是并不是所有任务都可以异步执行,判断一个任务是否可以异步的条件是,任务发起方是否立即需要执行结果
同步不等于阻塞 异步不等于非阻塞当使用异步方式发起任务时 任务中可能包含io操作 异步也可能阻塞同步提交任务 也会卡主程序 但是不等同阻塞,因为任务中可能在做一些计算任务,CPU没有切换到其他程序
from concurrent.futures import ThreadPoolExecutor
import time
pool = ThreadPoolExecutor()
def task():
time.sleep(1)
print('sub thread run...')
for i in range(10):
pool.submit(task) #submit是以异步的方式提交任务
print('over')
from concurrent.futures import ThreadPoolExecutor
import time
pool = ThreadPoolExecutor()
def task(i):
time.sleep(1)
print('sub thread run ...')
i += 1
return i
for i in range(10):
f = pool.submit(task,i)
print(f)
print(f.result()) #result是阻塞的,会等到这个任务执行完毕才能继续执行,会将异步变为同步
print('over')
#同步又变为了异步
from concurrent.futures import ThreadPoolExecutor
import time
pool = ThreadPoolExecutor()
def task(i):
time.sleep(1)
print('sub thread run ...')
i += 1
return i
fs = []
for i in range(10):
f = pool.submit(task,i)
fs.append(f)
#是一个阻塞函数,会等到池子中的所有任务完成后继续执行
pool.shutdown() #里面有一个wait参数:默认值是True
#注意:shutdown之后就不能提交新任务了
for i in fs:
print(i.result())
print('over')