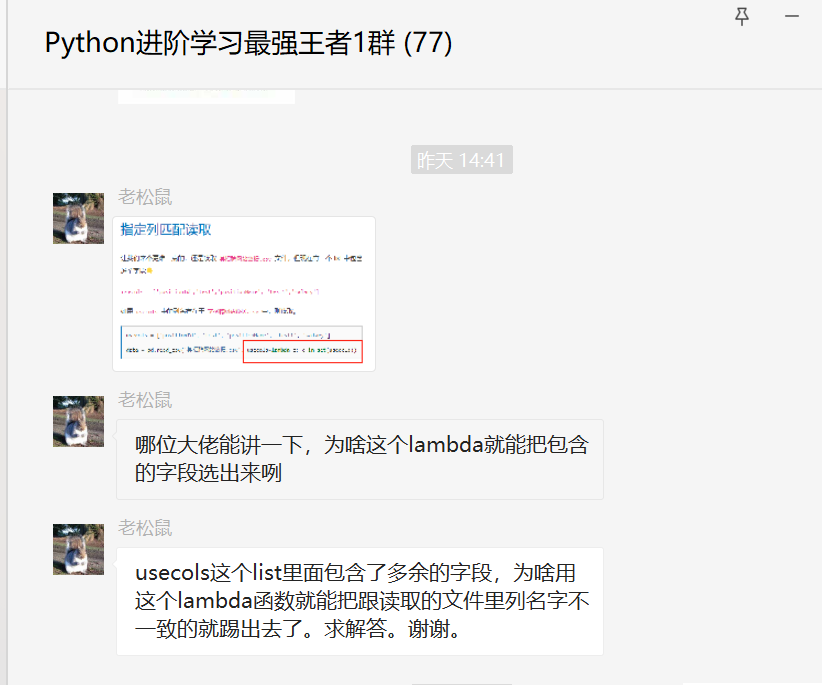
大家好,我是皮皮。
一、前言
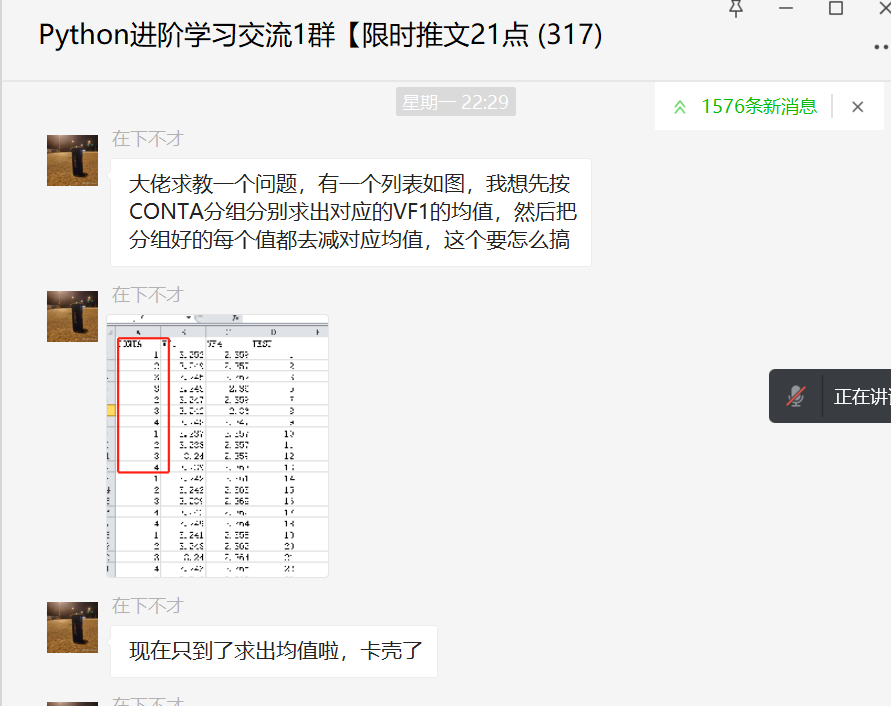
前几天在Python星耀交流群有个叫【在下不才】的粉丝问了一个Pandas的问题,按照A列进行分组并计算出B列每个分组的平均值,然后对B列内的每个元素减去分组平均值,这里拿出来给大家分享下,一起学习。
二、解决过程
这个看上去倒是不太难,但是实现的时候,总是一看就会,一用就废。这里给出【瑜亮老师】的三个解法,一起来看看吧!
方法一:使用自定义函数
代码如下:
import pandas as pd
lv = [1, 2, 2, 3, 3, 4, 2, 3, 3, 3, 3]
num = [122, 111, 222, 444, 555, 555, 333, 666, 666, 777, 888]
df = pd.DataFrame({'lv': lv, 'num': num})
def demean(arr):
return arr - arr.mean()
# 按照"lv"列进行分组并计算出"num"列每个分组的平均值,然后"num"列内的每个元素减去分组平均值
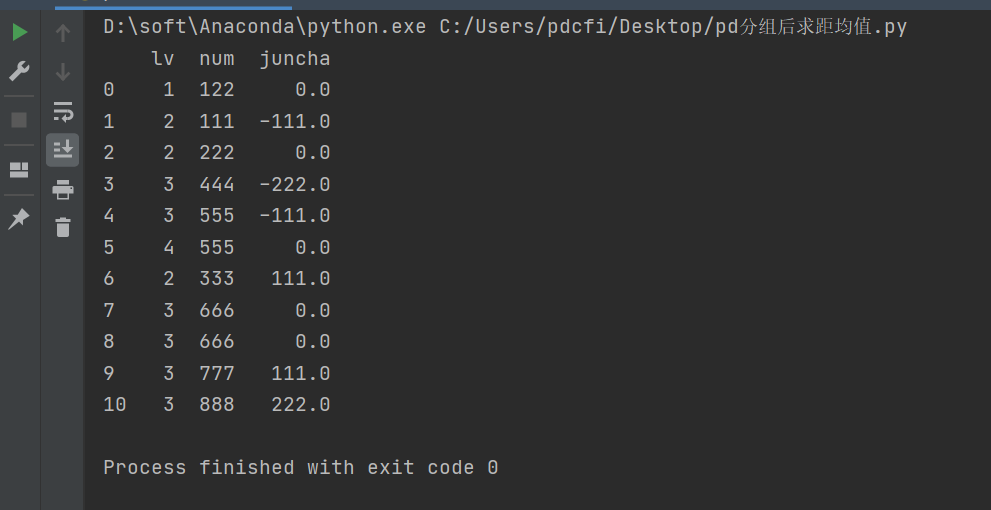
df["juncha"] = df.groupby("lv")["num"].transform(demean)
print(df
# transform 也支持 lambda 函数,效果是一样的,更简洁一些
# df["juncha"] = df.groupby("lv")["num"].transform(lambda x: x - x.mean())
# print(df)方法二:使用内置函数
代码如下:
import pandas as pd
lv = [1, 2, 2, 3, 3, 4, 2, 3, 3, 3, 3]
num = [122, 111, 222, 444, 555, 555, 333, 666, 666, 777, 888]
df = pd.DataFrame({'lv': lv, 'num': num})
gp_mean = df.groupby('lv')["num"].mean().rename("gp_mean").reset_index()
df2 = df.merge(gp_mean)
df2["juncha"] = df2["num"] - df2["gp_mean"]
print(df2)
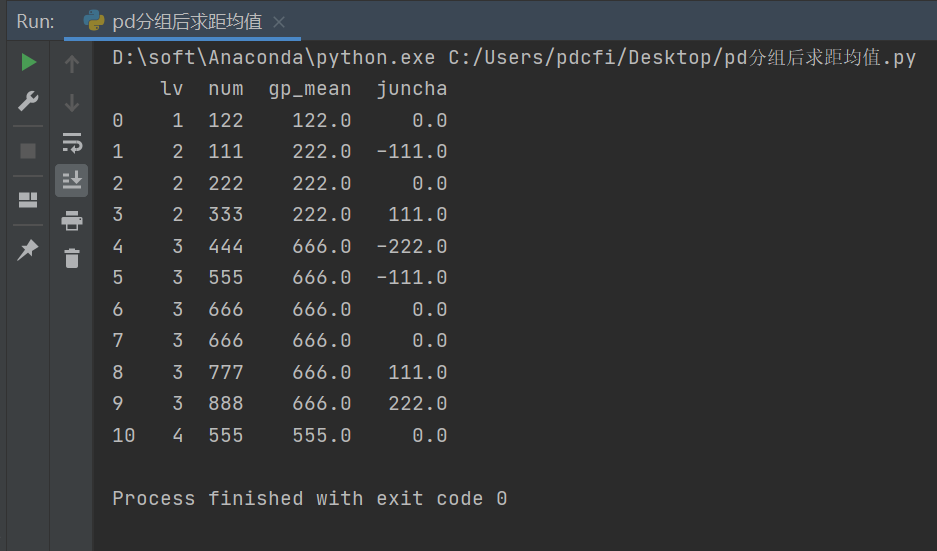
方法三:使用 transform
transform能返回完整数据,输出的形状和输入一致(输入是num列,输出也是一列),代码如下:
import pandas as pd
lv = [1, 2, 2, 3, 3, 4, 2, 3, 3, 3, 3]
num = [122, 111, 222, 444, 555, 555, 333, 666, 666, 777, 888]
df = pd.DataFrame({'lv': lv, 'num': num})
# 方法三: 使用 transform。
df["gp_mean"] = df.groupby('lv')["num"].transform('mean')
df["juncha"] = df["num"] - df["gp_mean"]
print(df)
# 直接输出结果,省略分组平均值列
df["juncha"] = df["num"] - df.groupby('lv')["num"].transform('mean')
print(df)
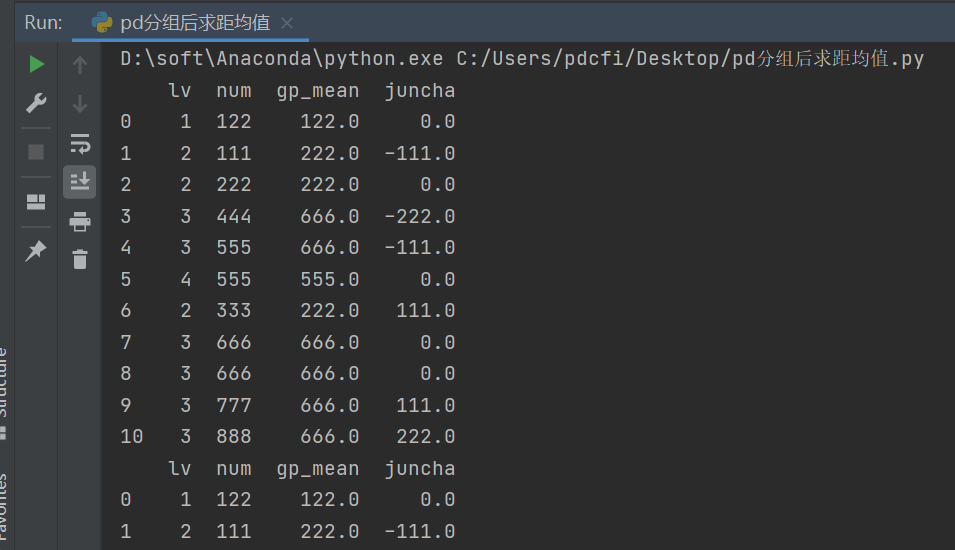
这样问题就完美地解决啦!
后面他还想用类的方式写,不过看上去没有那么简单。
三、总结
大家好,我是皮皮。这篇文章主要分享了Pandas处理相关知识,基于粉丝提出的按照A列进行分组并计算出B列每个分组的平均值,然后对B列内的每个元素减去分组平均值的问题,给出了3个行之有效的方法,帮助粉丝顺利解决了问题。
最后感谢粉丝【在下不才】提问,感谢【德善堂小儿推拿-瑜亮老师】给出的具体解析和代码演示,感谢【月神】提供的思路,感谢【dcpeng】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。