
12月19日,2020中国 .NET开发者大会在苏州召开。本次会议以“开源、共享、创新”为主题,结合线下、线上实时同步直播的方式,征集了来自微软、龙芯等知名企业的40余位技术大咖,为50 余万名开发者带来了近50场技术讲座和 .NET应用实践。
葡萄城的表格技术负责人王鸿先生,有幸作为本次大会的演讲嘉宾,向在场的 .NET 开发者分享了葡萄城高性能表格技术调优方面的经验积累。

王鸿,作为葡萄城表格技术的负责人,自 2014年起,便一直聚焦于企业高性能表格技术领域的研究,为葡萄城设计了全新的表格组件架构,并带领研发团队推出了一款性能在业界领先的电子表格组件GcExcel, 积累了大量高并发、高可用性表格组件的架构设计经验。

在本次分享中,王鸿从葡萄城研发电子表格组件的背景与初衷出发,详细对比了 Excel 与原生 C# 代码的读取性能差异,并总结了若干针对prototype 原型进行性能调优的手段,如减少垃圾回收的影响、共享对象提升性能、压缩数据降低内存、充分利用高速缓存等方式。
以下是王鸿老师的主要分享内容:
1. 葡萄城研发电子表格组件的背景与初衷
早在30 多年前,电子表格就已经作为办公软件中的一个基础功能套件,首次出现在个人电脑中。近些年,随着网络信息化的进一步加强,电子表格的应用越来越广泛和深入。
如今“表格”也已经成为数据的一种重要表现形式,广泛应用于各类桌面软件、应用系统和 SaaS 平台的存储结构、系统构成中。人们已经习惯使用表格工具来处理财税、金融、证券、保险、工业制造、物流仓储等行业的大规模数据,其中典型代表包括微软的 Excel、谷歌的 Spreadsheet,以及 WPS 等。
葡萄城,作为全球领先的开发技术提供商,很早便投入了研发精力,开拓并探索如何将电子表格以组件的方式嵌入到各类系统中。经过近 30 年的研究,葡萄城的表格技术已经实现了在保留用户 Excel 使用习惯的同时,也能基于用户的经验和积累在业务系统中提供高效的数据处理和可视化能力。
2. 通过 C# 代码,测试 Excel 文件读取的极限性能
电子表格的应用场景一般都较为复杂,开发实现它们会碰到很多技术难点,其中最为典型的便是性能问题。
葡萄城为实现高性能的表格组件,克服了很多性能挑战:如怎样快速打开和保存一个电子表格文件、如何计算海量的公式函数、如何让用户快速完成大量单元格的值和样式设置等。
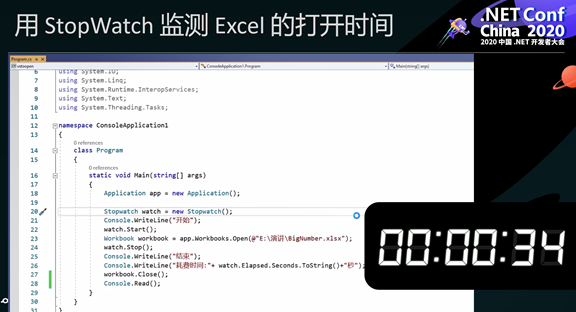
为了测试 C# 代码对 Excel 文件的读取性能,王鸿老师选取了一个日常生活中很容易碰到的场景:当一个电子表格文件很大的时候(包含30列、1,000,000行、30,000,000 个单元格数据),用Excel打开它需要等待 34 秒。
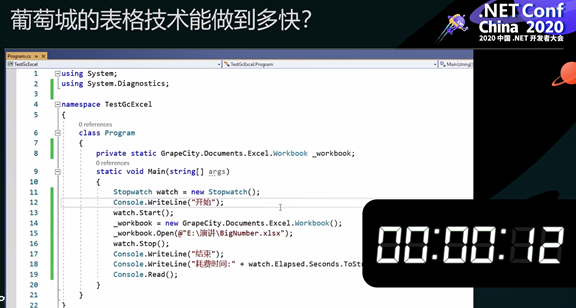
如果用户想要用更短的时间打开这样的大文件时,有没有办法实现呢?答案是有,经过测试,用葡萄城的表格组件 GcExcel 打开这样一份文件,仅需 12 秒。
3. 葡萄城表格技术优化:减少垃圾回收的影响
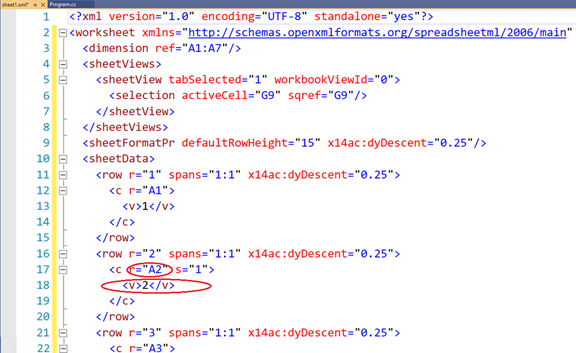
从Office 2007 开始,Excel 文件就是一个标准的 Zip 文件,对其解压后,找到一个名为“Worksheets”的文件夹,在其中的“sheet1.xml”文件中,存放了每个 Excel 文件单元格对应的位置和值。
如何通过更高效的算法取出这些位置和值,便是葡萄城表格技术的优化方向。对于一段未经优化的 C# 代码而言,把每个单元格的值读出来,存放在一个List中,需要27秒。在这里,我们仅仅将代码中的 object 改为 double,就可以让其在20秒完成。
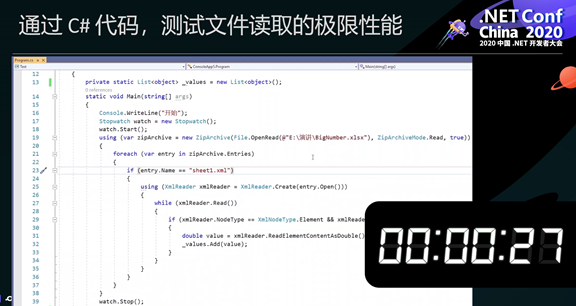
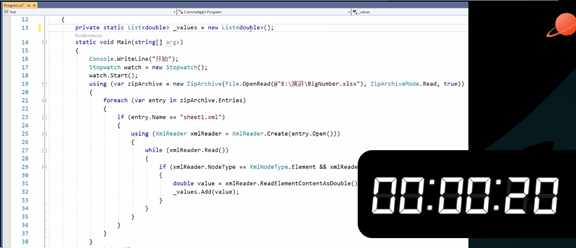
这 7秒差距,便是由于垃圾回收带来的影响。在 List中有太多的object对象,这耗费了大量的垃圾回收时间,尽管它没有被回收掉,但因为它们是object,所以在垃圾回收的过程中,需要不断的检测它们是否可以回收,将 object 改为 double,垃圾回收的时间便可以忽略不计。
葡萄城表格技术如何克服垃圾回收的影响?
消除单元格概念。因为单元格的数量太多了,保留这个概念就很难把object的数量降得很低。葡萄城把原来在单元格类型里得数据分开处理,把样式剔除出去另外处理,这里只考虑单元格值。电子表格中单元格的值可能有四种类型:数字、文本、布尔和错误,数字在内部都是用double类型来表示,布尔和错误也可以用double来存储。对于文本,不能用常规方法存储,但我们可以想一个办法,让double也可以存文本,这个后面详细讲。总之,用double可以存储所有的Excel数据,这样我们就可以设计一个简单单元格的数据对象,它是一个结构体,不是object。
行存储改成列存储。电子表格行的数量最大为2的20次方(约1048576),而列的数量最大为2的14次方(约16384),所以把行存储改成列存储,可以减少对象的数量。利用C# 的泛型,让字典中存储值类型数据。经过这样一改造,object的数量会从九千多万下降到一万多,垃圾回收的影响基本忽略不计。
4. 葡萄城表格技术优化:共享存储及样式压缩
所谓共享存储,就是把整个软件中共同的对象只生成一份,放在一个全局的地方,每个对象用一个数字做ID,其它地方地方只存这个ID。以下面的文本为例,所有的文本集中存储在一个表中,每个文本有一个唯一的ID,单元格中只存储这个ID。
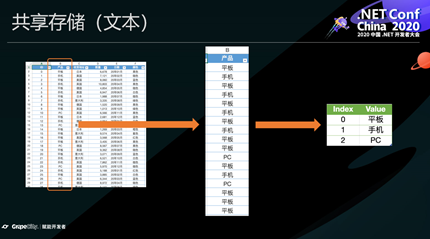
共享存储有很多优点,对降低内存和提升性能有非常明显的作用:
降低内存消耗。对一个数据量很大的软件,会有很多数据都是重复的,比如电子表格中,如果文本的数量很大,那么重复率就非常高,把这些文本集中存储,相同的只存一份,你会发现,不同的文本数量其实很少,这会极大降低内存消耗。
提升性能。以对字符串做查找、替换为例,如果没有共享集中存储,必须要扫描所有的单元,对每一个单元格文本都做一次比较操作。但有了共享存储,就只需要查找“字典”就可以了;在字符串比较时,只需要比较数字是否相等就可以了;在排序等操作中,只需先把表中的字符串建立一个索引,排好序,后面需要时利用这个索引就可以了。
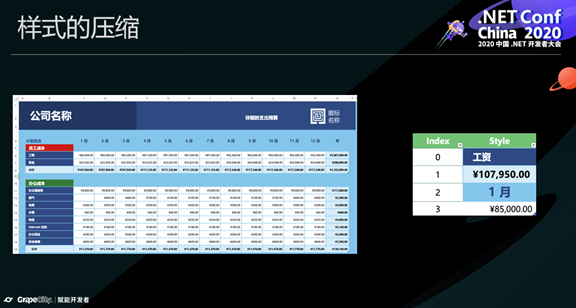
通过共享存储,葡萄城表格技术已经把内存的消耗降低了很多,但我们还可以进一步优化。大家观察这个图,我们在每一个单元格存储了一个数字,指向全局样式表的一格样式对象。但我们发现,这些数字的重复率很高,因为电子表格中,一片区域的样式往往是一样的,针对这个特点,我们很容易就想到一个优化的方法。
我们不需要在每个单元格中存储一个数字,而是建立图上这样一个表,表的一栏记录一个区域(一个矩形),另一栏记录这个区域对应的样式的ID,通过这样的方式,我们又可以把样式的存储空间降低很多。极端一点讲,如果整个工作表都是同一种样式,那么我们这里只需要存储一个矩形和一个数字。

5. 葡萄城表格技术优化:充分利用高速缓存
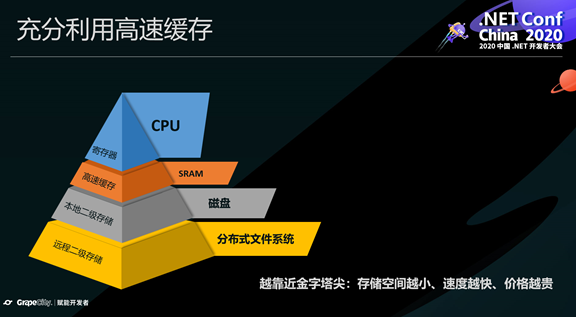
现在的CPU都有高速缓存,它能提升CPU处理数据的性能。这个图展示了不同存储介质和CPU的关系:越高速的存储介质离CPU更近,速度越快、空间更小、价格越贵。
CPU在读取数据的时候,先从最近的缓存中读,只有没命中,才从下一级缓存中读。因此,提升缓存命中率对改善性能意义重大。
同时,我们还要清楚,当数据从较慢的存储介质往较快的存储介质复制时,不是依次进行,而是一块一块的复制,也就是说,当我们访问内存中某一个数据时,它周围相邻的数据也一起读入了离CPU最近的高速缓存。因此,如果下一个时刻就读相邻的数据,便可以直接在缓存中找到,读取速度就会非常快。
知道了高速缓存的原理,如何编写缓存友好的代码?
· 在组件设计的时候,选择什么样的数据结构得注意,比如数组和字典,受缓存的影响可能不一样。
· 在访问数据的时候,要注意数据的存储方式。
6. 葡萄城表格技术优化:其他实践
除了上述优化方法,葡萄城的表格技术还有更多优化实践。如创建Cache、使用基于集合的操作运算、利用SIMD计算大量数据等。
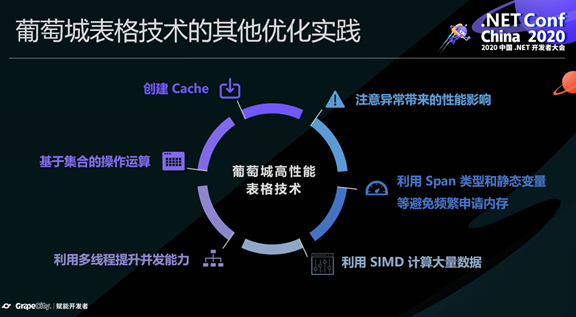
以上就是王鸿老师分享的主要内容,通过一个个鲜活的示例代码+时间对比,也让大家对葡萄城高性能的表格技术形成了非常深刻的认识。
于此同时,王鸿老师在大会上分享的高性能表格技术,均已经实现落地。在前端,纯前端表格控件 SpreadJS可针对Excel、Grid数据进行在线编辑、计算和展示;在后端,服务端表格组件 GrapeCity Documents for Excel (简称:GcExcel)可批量处理 Excel 文档,执行更高效的导出与打印。









