image
原文地址:深入理解 Go Slice
是什么
在 Go 中,Slice(切片)是抽象在 Array(数组)之上的特殊类型。为了更好地了解 Slice,第一步需要先对 Array 进行理解。深刻了解 Slice 与 Array 之间的区别后,就能更好的对其底层一番摸索 😄
用法
Array
func main() {
nums := [3]int{}
nums[0] = 1
n := nums[0]
n = 2
fmt.Printf("nums: %v\n", nums)
fmt.Printf("n: %d\n", n)
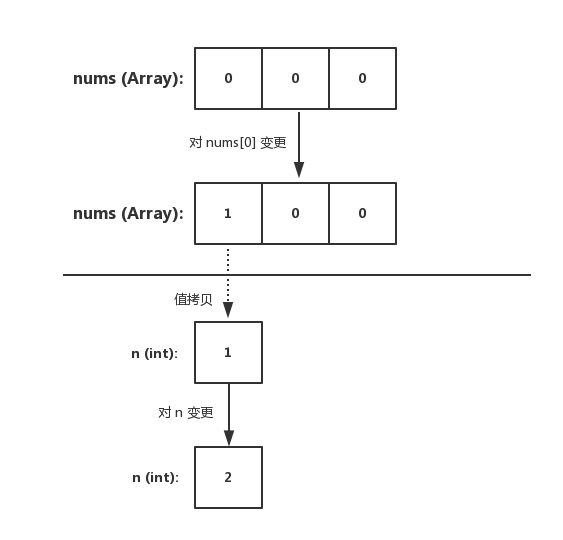
} 我们可得知在 Go 中,数组类型需要指定长度和元素类型。在上述代码中,可得知 [3]int{} 表示 3 个整数的数组,并进行了初始化。底层数据存储为一段连续的内存空间,通过固定的索引值(下标)进行检索
image
数组在声明后,其元素的初始值(也就是零值)为 0。并且该变量可以直接使用,不需要特殊操作
同时数组的长度是固定的,它的长度是类型的一部分,因此 [3]int 和 [4]int 在类型上是不同的,不能称为 “一个东西”
输出结果
nums: [1 0 0]
n: 2 Slice
func main() {
nums := [3]int{}
nums[0] = 1
dnums := nums[:]
fmt.Printf("dnums: %v", dnums)
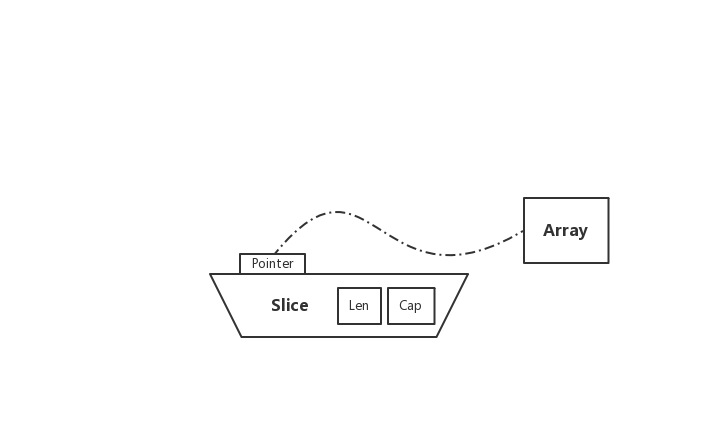
} Slice 是对 Array 的抽象,类型为 []T。在上述代码中,dnums 变量通过 nums[:] 进行赋值。需要注意的是,Slice 和 Array 不一样,它不需要指定长度。也更加的灵活,能够自动扩容
数据结构
image
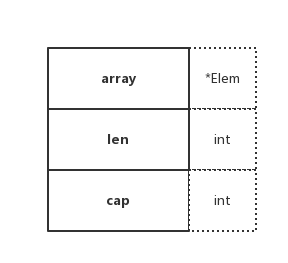
type slice struct {
array unsafe.Pointer
len int
cap int
} Slice 的底层数据结构共分为三部分,如下:
- array:指向所引用的数组指针(
unsafe.Pointer可以表示任何可寻址的值的指针) - len:长度,当前引用切片的元素个数
- cap:容量,当前引用切片的容量(底层数组的元素总数)
在实际使用中,cap 一定是大于或等于 len 的。否则会导致 panic
示例
为了更好的理解,我们回顾上小节的代码便于演示,如下:
func main() {
nums := [3]int{}
nums[0] = 1
dnums := nums[:]
fmt.Printf("dnums: %v", dnums)
} 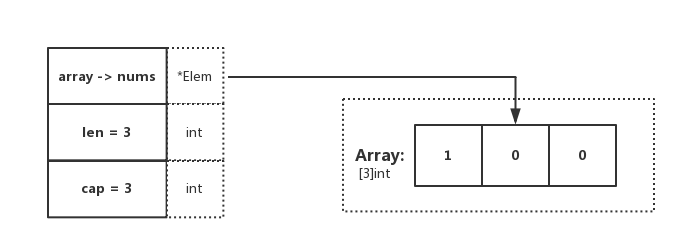
image
在代码中,可观察到 dnums := nums[:],这段代码确定了 Slice 的 Pointer 指向数组,且 len 和 cap 都为数组的基础属性。与图示表达一致
len、cap 不同
func main() {
nums := [3]int{}
nums[0] = 1
dnums := nums[0:2]
fmt.Printf("dnums: %v, len: %d, cap: %d", dnums, len(dnums), cap(dnums))
} 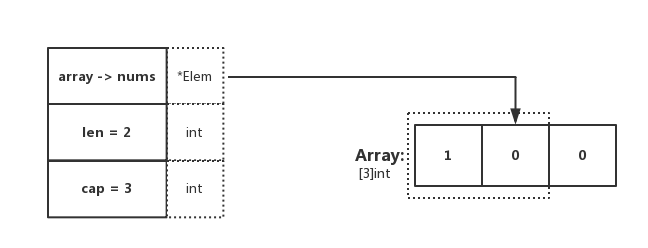
image
输出结果
dnums: [1 0], len: 2, cap: 3 显然,在这里指定了 Slice[0:2],因此 len 为所引用元素的个数,cap 为所引用的数组元素总个数。与期待一致 😄
创建
Slice 的创建有两种方式,如下:
var []T或[]T{}func make([] T,len,cap)[] T
可以留意 make 函数,我们都知道 Slice 需要指向一个 Array。那 make 是怎么做的呢?
它会在调用 make 的时候,分配一个数组并返回引用该数组的 Slice
func makeslice(et *_type, len, cap int) slice {
maxElements := maxSliceCap(et.size)
if len < 0 || uintptr(len) > maxElements {
panic(errorString("makeslice: len out of range"))
}
if cap < len || uintptr(cap) > maxElements {
panic(errorString("makeslice: cap out of range"))
}
p := mallocgc(et.size*uintptr(cap), et, true)
return slice{p, len, cap}
} - 根据传入的 Slice 类型,获取其类型能够申请的最大容量大小
- 判断 len 是否合规,检查是否在 0 < x < maxElements 范围内
- 判断 cap 是否合规,检查是否在 len < x < maxElements 范围内
- 申请 Slice 所需的内存空间对象。若为大型对象(大于 32 KB)则直接从堆中分配
- 返回申请成功的 Slice 内存地址和相关属性(默认返回申请到的内存起始地址)
扩容
当使用 Slice 时,若存储的元素不断增长(例如通过 append)。当条件满足扩容的策略时,将会触发自动扩容
那么分别是什么规则呢?让我们一起看看源码是怎么说的 😄
zerobase
func growslice(et *_type, old slice, cap int) slice {
...
if et.size == 0 {
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
...
} 当 Slice size 为 0 时,若将要扩容的容量比原本的容量小,则抛出异常(也就是不支持缩容操作)。否则,将重新生成一个新的 Slice 返回,其 Pointer 指向一个 0 byte 地址(不会保留老的 Array 指向)
扩容 - 计算策略
func growslice(et *_type, old slice, cap int) slice {
...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
...
}
}
...
} - 若 Slice cap 大于 doublecap,则扩容后容量大小为 新 Slice 的容量(超了基准值,我就只给你需要的容量大小)
- 若 Slice len 小于 1024 个,在扩容时,增长因子为 1(也就是 3 个变 6 个)
- 若 Slice len 大于 1024 个,在扩容时,增长因子为 0.25(原本容量的四分之一)
注:也就是小于 1024 个时,增长 2 倍。大于 1024 个时,增长 1.25 倍
扩容 - 内存策略
func growslice(et *_type, old slice, cap int) slice {
...
var overflow bool
var lenmem, newlenmem, capmem uintptr
const ptrSize = unsafe.Sizeof((*byte)(nil))
switch et.size {
case 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > _MaxMem
newcap = int(capmem)
...
}
if cap < old.cap || overflow || capmem > _MaxMem {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.kind&kindNoPointers != 0 {
p = mallocgc(capmem, nil, false)
memmove(p, old.array, lenmem)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
p = mallocgc(capmem, et, true)
if !writeBarrier.enabled {
memmove(p, old.array, lenmem)
} else {
for i := uintptr(0); i < lenmem; i += et.size {
typedmemmove(et, add(p, i), add(old.array, i))
}
}
}
...
} 1、获取老 Slice 长度和计算假定扩容后的新 Slice 元素长度、容量大小以及指针地址(用于后续操作内存的一系列操作)
2、确定新 Slice 容量大于老 Sice,并且新容量内存小于指定的最大内存、没有溢出。否则抛出异常
3、若元素类型为 kindNoPointers,也就是非指针类型。则在老 Slice 后继续扩容
- 第一步:根据先前计算的
capmem,在老 Slice cap 后继续申请内存空间,其后用于扩容 - 第二步:将 old.array 上的 n 个 bytes(根据 lenmem)拷贝到新的内存空间上
- 第三步:新内存空间(p)加上新 Slice cap 的容量地址。最终得到完整的新 Slice cap 内存地址
add(p, newlenmem)(ptr) - 第四步:从 ptr 开始重新初始化 n 个 bytes(capmem-newlenmem)
注:那么问题来了,为什么要重新初始化这块内存呢?这是因为 ptr 是未初始化的内存(例如:可重用的内存,一般用于新的内存分配),其可能包含 “垃圾”。因此在这里应当进行 “清理”。便于后面实际使用(扩容)
4、不满足 3 的情况下,重新申请并初始化一块内存给新 Slice 用于存储 Array
5、检测当前是否正在执行 Write Barrier(写屏障)。若正在启用 Write Barrier,则通过 memmove 采取拷贝的方式将 lenmem 个字节从 old.array 拷贝到 ptr。否则使用 typedmemmove 的方式,利用指针循环拷贝。以此达到更高的效率
注:一般会在 GC 标记阶段启用 Write Barrier,并且 Write Barrier 只针对指针启用。那么在第 5 点中,你就不难理解为什么会有两种截然不同的处理方式了
小结
这里需要注意的是,扩容时的内存管理的选择项,如下:
- 翻新扩展:当前元素为
kindNoPointers,将在老 Slice cap 的地址后继续申请空间用于扩容 - 举家搬迁:重新申请一块内存地址,整体迁移并扩容
两个小 “陷阱”
一、同根
func main() {
nums := [3]int{}
nums[0] = 1
fmt.Printf("nums: %v , len: %d, cap: %d\n", nums, len(nums), cap(nums))
dnums := nums[0:2]
dnums[0] = 5
fmt.Printf("nums: %v ,len: %d, cap: %d\n", nums, len(nums), cap(nums))
fmt.Printf("dnums: %v, len: %d, cap: %d\n", dnums, len(dnums), cap(dnums))
} 输出结果:
nums: [1 0 0] , len: 3, cap: 3
nums: [5 0 0] ,len: 3, cap: 3
dnums: [5 0], len: 2, cap: 3 在未扩容前,Slice array 指向所引用的 Array。因此在 Slice 上的变更。会直接修改到原始 Array 上(两者所引用的是同一个)
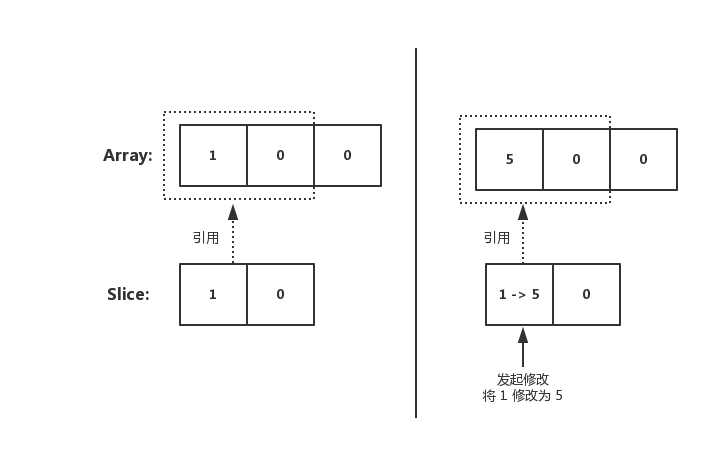
image
二、时过境迁
随着 Slice 不断 append,内在的元素越来越多,终于触发了扩容。如下代码:
func main() {
nums := [3]int{}
nums[0] = 1
fmt.Printf("nums: %v , len: %d, cap: %d\n", nums, len(nums), cap(nums))
dnums := nums[0:2]
dnums = append(dnums, []int{2, 3}...)
dnums[1] = 1
fmt.Printf("nums: %v ,len: %d, cap: %d\n", nums, len(nums), cap(nums))
fmt.Printf("dnums: %v, len: %d, cap: %d\n", dnums, len(dnums), cap(dnums))
} 输出结果:
nums: [1 0 0] , len: 3, cap: 3
nums: [1 0 0] ,len: 3, cap: 3
dnums: [1 1 2 3], len: 4, cap: 6 往 Slice append 元素时,若满足扩容策略,也就是假设插入后,原本数组的容量就超过最大值了
这时候内部就会重新申请一块内存空间,将原本的元素拷贝一份到新的内存空间上。此时其与原本的数组就没有任何关联关系了,再进行修改值也不会变动到原始数组。这是需要注意的
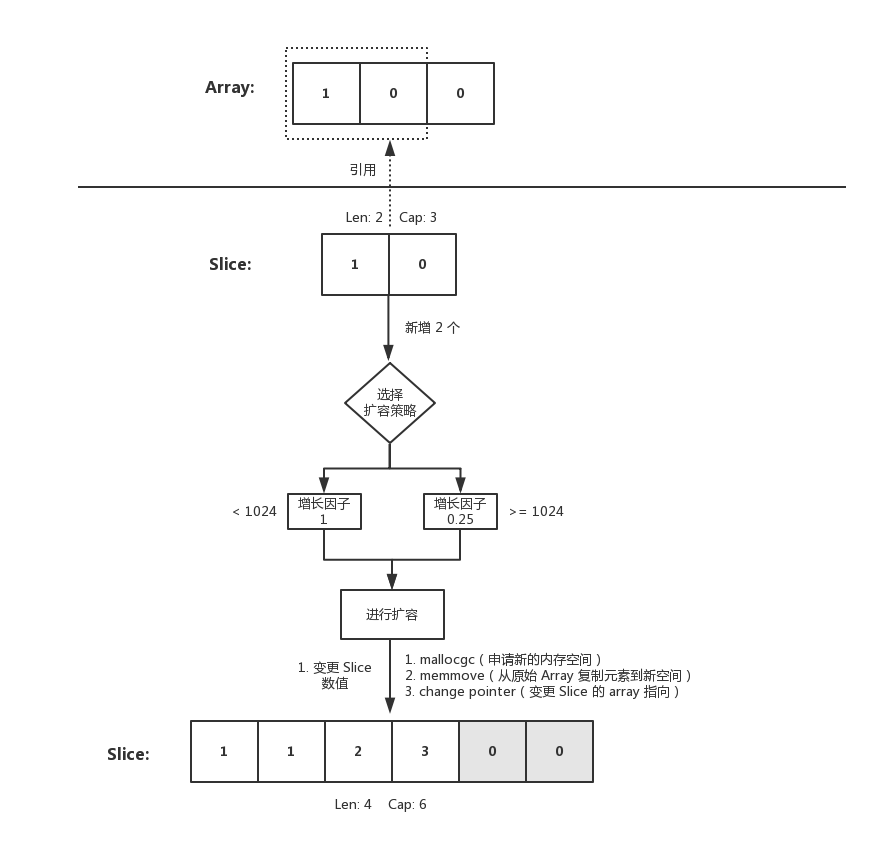
image
复制
原型
func copy(dst,src [] T)int copy 函数将数据从源 Slice复制到目标 Slice。它返回复制的元素数。
示例
func main() {
dst := []int{1, 2, 3}
src := []int{4, 5, 6, 7, 8}
n := copy(dst, src)
fmt.Printf("dst: %v, n: %d", dst, n)
} copy 函数支持在不同长度的 Slice 之间进行复制,若出现长度不一致,在复制时会按照最少的 Slice 元素个数进行复制
那么在源码中是如何完成复制这一个行为的呢?我们来一起看看源码的实现,如下:
func slicecopy(to, fm slice, width uintptr) int {
if fm.len == 0 || to.len == 0 {
return 0
}
n := fm.len
if to.len < n {
n = to.len
}
if width == 0 {
return n
}
...
size := uintptr(n) * width
if size == 1 {
*(*byte)(to.array) = *(*byte)(fm.array) // known to be a byte pointer
} else {
memmove(to.array, fm.array, size)
}
return n
} - 若源 Slice 或目标 Slice 存在长度为 0 的情况,则直接返回 0(因为压根不需要执行复制行为)
- 通过对比两个 Slice,获取最小的 Slice 长度。便于后续操作
- 若 Slice 只有一个元素,则直接利用指针的特性进行转换
- 若 Slice 大于一个元素,则从
fm.array复制size个字节到to.array的地址处(会覆盖原有的值)
"奇特"的初始化
在 Slice 中流传着两个传说,分别是 Empty 和 Nil Slice,接下来让我们看看它们的小区别 🤓
Empty
func main() {
nums := []int{}
renums := make([]int, 0)
fmt.Printf("nums: %v, len: %d, cap: %d\n", nums, len(nums), cap(nums))
fmt.Printf("renums: %v, len: %d, cap: %d\n", renums, len(renums), cap(renums))
} 输出结果:
nums: [], len: 0, cap: 0
renums: [], len: 0, cap: 0 Nil
func main() {
var nums []int
} 输出结果:
nums: [], len: 0, cap: 0 想一想
乍一看,Empty Slice 和 Nil Slice 好像一模一样?不管是 len,还是 cap 都为 0。好像没区别?我们再看看如下代码:
func main() {
var nums []int
renums := make([]int, 0)
if nums == nil {
fmt.Println("nums is nil.")
}
if renums == nil {
fmt.Println("renums is nil.")
}
} 你觉得输出结果是什么呢?你可能已经想到了,最终的输出结果:
nums is nil. 为什么
Empty
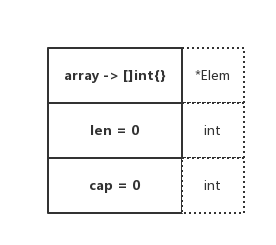
image
Nil
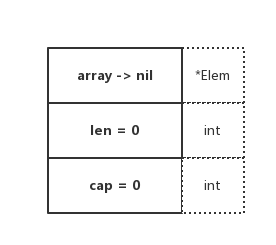
image
从图示中可以看出来,两者有本质上的区别。其底层数组的指向指针是不一样的,Nil Slice 指向的是 nil,Empty Slice 指向的是实际存在的空数组地址
你可以认为,Nil Slice 代指不存在的 Slice,Empty Slice 代指空集合。两者所代表的意义是完全不同的
总结
通过本文,可得知 Go Slice 相当灵活。不需要你手动扩容,也不需要你关注加多少减多少。对 Array 是动态引用,是 Go 类型的一个极大的补充,也因此在应用中使用的更多、更便捷
虽然有个别要注意的 “坑”,但其实是合理的。你觉得呢?😄