
Influxdb原理详解
来源: https://www.cnblogs.com/gaoguangjun/p/8513054.html
本文属于《 InfluxDB系列教程》文章系列,该系列共包括以下 15 部分:
- InfluxDB学习之InfluxDB的安装和简介
- InfluxDB学习之InfluxDB的基本概念
- InfluxDB学习之InfluxDB的基本操作
- InfluxDB学习之InfluxDB的HTTP API写入操作
- InfluxDB学习之InfluxDB数据保留策略(Retention Policies)
- InfluxDB学习之InfluxDB连续查询(Continuous Queries)
- InfluxDB学习之InfluxDB的HTTP API查询操作
- InfluxDB学习之InfluxDB的关键概念
- InfluxDB学习之InfluxDB常用函数(一)聚合类函数
- InfluxDB学习之InfluxDB常用函数(二)选择类函数
- InfluxDB学习之InfluxDB常用函数(三)变换类函数
- InfluxDB学习之再说连续查询
- Influxdb原理详解
- InfluxDB安装后web页面无法访问的解决方案
- InfluxDB数据备份和恢复方法,支持本地和远程备份
系列详情请看:《InfluxDB系列教程》
文章目录
InfluxDB是一款Go语言写的时序数据库,本文主要介绍下Influxdb的架构和基本原理。
更多InfluxDB详细教程请看:InfluxDB系列学习教程目录
InfluxDB技术交流群:580487672(点击加入)
一、InfluxDB特点
- 可以设置metric的保存时间。
- 支持通过条件过滤以及正则表达式删除数据。
- 支持类似 sql 的语法。
- 可以设置数据在集群中的副本数。
- 支持定期采样数据,写入另外的measurement,方便分粒度存储数据。
二、InfluxDB概念
1)数据格式 Line Protocol
在 InfluxDB 中,我们可以粗略的将要存入的一条数据看作一个虚拟的 key 和其对应的 value(field value),格式如下:
cpu_usage,host=server01,region=us-west value=0.64 1434055562000000000
虚拟的 key 包括以下几个部分: database, retention policy, measurement, tag sets, field name, timestamp。 database 和 retention policy 在上面的数据中并没有体现,通常在插入数据时在 http 请求的相应字段中指定。
database: 数据库名,在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的,存放在磁盘上的不同目录。
retention policy: 存储策略,用于设置数据保留的时间,每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,之后用户可以自己设置,例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。InfluxDB 会定期清除过期的数据。
measurement: 测量指标名,例如 cpu_usage 表示 cpu 的使用率。
tag sets: tags 在 InfluxDB 中会按照字典序排序,不管是 tagk 还是 tagv,只要不一致就分别属于两个 key,例如
host=server01,region=us-west和host=server02,region=us-west就是两个不同的 tag set。field name: 例如上面数据中的
value就是 fieldName,InfluxDB 中支持一条数据中插入多个 fieldName,这其实是一个语法上的优化,在实际的底层存储中,是当作多条数据来存储。timestamp: 每一条数据都需要指定一个时间戳,在 TSM 存储引擎中会特殊对待,以为了优化后续的查询操作。
2)Point
InfluxDB 中单条插入语句的数据结构,series + timestamp 可以用于区别一个 point,也就是说一个 point 可以有多个 field name 和 field value。
3)Series
series 相当于是 InfluxDB 中一些数据的集合,在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
series 的 key 为 measurement + 所有 tags 的序列化字符串,这个 key 在之后会经常用到。
代码中的结构如下:
type Series struct { mu sync.RWMutex Key string // series key Tags map[string]string // tags id uint64 // id measurement *Measurement // measurement }4)Shard
shard 在 InfluxDB 中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
创建数据库时会自动创建一个默认存储策略,永久保存数据,对应的在此存储策略下的 shard 所保存的数据的时间段为 7 天,计算的函数如下:
func shardGroupDuration(d time.Duration) time.Duration { if d >= 180*24*time.Hour || d == 0 { // 6 months or 0 return 7 * 24 * time.Hour } else if d >= 2*24*time.Hour { // 2 days return 1 * 24 * time.Hour } return 1 * time.Hour }如果创建一个新的 retention policy 设置数据的保留时间为 1 天,则单个 shard 所存储数据的时间间隔为 1 小时,超过1个小时的数据会被存放到下一个 shard 中。
三、存储引擎 - TSM Tree
从 LevelDB(LSM Tree),到 BoltDB(mmap B+树),现在InfluxDB使用的是自己实现的 TSM Tree 的算法,类似 LSM Tree,针对 InfluxDB 的使用做了特殊优化。
TSM Tree 是 InfluxDB 根据实际需求在 LSM Tree 的基础上稍作修改优化而来。
TSM 存储引擎主要由几个部分组成: cache、wal、tsm file、compactor。
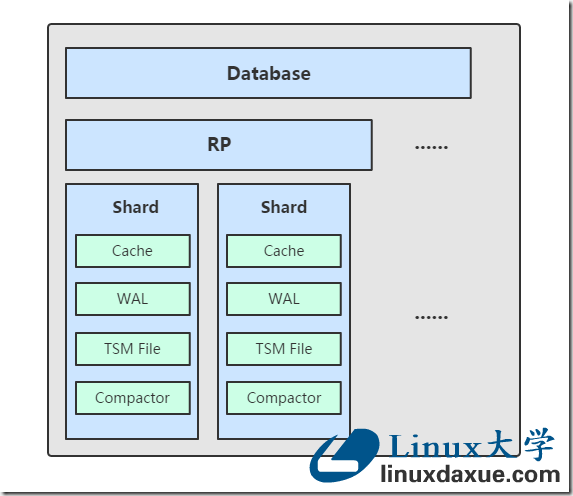
1)Shard
shard 并不能算是其中的一个组件,因为这是在 tsm 存储引擎之上的一个概念。在 InfluxDB 中按照数据的时间戳所在的范围,会去创建不同的 shard,每一个 shard 都有自己的 cache、wal、tsm file 以及 compactor,这样做的目的就是为了可以通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。
在 LSM Tree 中删除数据是通过给指定 key 插入一个删除标记的方式,数据并不立即删除,需要等之后对文件进行压缩合并时才会真正地将数据删除,所以删除大量数据在 LSM Tree 中是一个非常低效的操作。
而在 InfluxDB 中,通过 retention policy 设置数据的保留时间,当检测到一个 shard 中的数据过期后,只需要将这个 shard 的资源释放,相关文件删除即可,这样的做法使得删除过期数据变得非常高效。
2)Cache
cache 相当于是 LSM Tree 中的 memtable,在内存中是一个简单的 map 结构,这里的 key 为 seriesKey + 分隔符 + filedName,目前代码中的分隔符为 #!~#,entry 相当于是一个按照时间排序的存放实际值的数组,具体结构如下:
type Cache struct { commit sync.Mutex mu sync.RWMutex store map[string]*entry size uint64 // 当前使用内存的大小 maxSize uint64 // 缓存最大值 // snapshots are the cache objects that are currently being written to tsm files // they're kept in memory while flushing so they can be queried along with the cache. // they are read only and should never be modified // memtable 快照,用于写入 tsm 文件,只读 snapshot *Cache snapshotSize uint64 snapshotting bool // This number is the number of pending or failed WriteSnaphot attempts since the last successful one. snapshotAttempts int stats *CacheStatistics lastSnapshot time.Time }插入数据时,实际上是同时往 cache 与 wal 中写入数据,可以认为 cache 是 wal 文件中的数据在内存中的缓存。当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache,这样即使系统出现故障,也不会导致数据的丢失。
cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB,每当 cache 中的数据达到阀值后,会将当前的 cache 进行一次快照,之后清空当前 cache 中的内容,再创建一个新的 wal 文件用于写入,剩下的 wal 文件最后会被删除,快照中的数据会经过排序写入一个新的 tsm 文件中。
目前的 cache 的设计有一个问题,当一个快照正在被写入一个新的 tsm 文件时,当前的 cache 由于大量数据写入,又达到了阀值,此时前一次快照还没有完全写入磁盘,InfluxDB 的做法是让后续的写入操作失败,用户需要自己处理,等待恢复后继续写入数据。
3)WAL
wal 文件的内容与内存中的 cache 相同,其作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据。
由于数据是被顺序插入到 wal 文件中,所以写入效率非常高。但是如果写入的数据没有按照时间顺序排列,而是以杂乱无章的方式写入,数据将会根据时间路由到不同的 shard 中,每一个 shard 都有自己的 wal 文件,这样就不再是完全的顺序写入,对性能会有一定影响。看到官方社区有说后续会进行优化,只使用一个 wal 文件,而不是为每一个 shard 创建 wal 文件。
wal 单个文件达到一定大小后会进行分片,创建一个新的 wal 分片文件用于写入数据。
4)TSM file
单个 tsm file 大小最大为 2GB,用于存放数据。
TSM file 使用了自己设计的格式,对查询性能以及压缩方面进行了很多优化,在后面的章节会具体说明其文件结构。
5)Compactor
compactor 组件在后台持续运行,每隔 1 秒会检查一次是否有需要压缩合并的数据。
主要进行两种操作,一种是 cache 中的数据大小达到阀值后,进行快照,之后转存到一个新的 tsm 文件中。
另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,使每一个文件尽量达到单个文件的最大大小,减少文件的数量,并且一些数据的删除操作也是在这个时候完成。
四、目录与文件结构
InfluxDB 的数据存储主要有三个目录。
默认情况下是 meta, wal 以及 data 三个目录。
meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件。
wal 目录存放预写日志文件,以 .wal 结尾。data 目录存放实际存储的数据文件,以 .tsm 结尾。这两个目录下的结构是相似的,其基本结构如下:
# wal 目录结构 -- wal -- mydb -- autogen -- 1 -- _00001.wal -- 2 -- _00035.wal -- 2hours -- 1 -- _00001.wal # data 目录结构 -- data -- mydb -- autogen -- 1 -- 000000001-000000003.tsm -- 2 -- 000000001-000000001.tsm -- 2hours -- 1 -- 000000002-000000002.tsm其中 mydb 是数据库名称,autogen 和 2hours 是存储策略名称,再下一层目录中的以数字命名的目录是 shard 的 ID 值,比如 autogen 存储策略下有两个 shard,ID 分别为 1 和 2,shard 存储了某一个时间段范围内的数据。再下一级的目录则为具体的文件,分别是 .wal 和 .tsm 结尾的文件。
1)WAL 文件
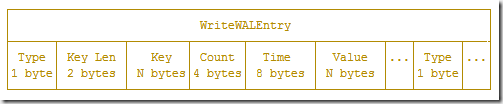
wal 文件中的一条数据,对应的是一个 key(measument + tags + fieldName) 下的所有 value 数据,按照时间排序。
Type (1 byte): 表示这个条目中 value 的类型。
Key Len (2 bytes): 指定下面一个字段 key 的长度。
Key (N bytes): 这里的 key 为 measument + tags + fieldName。
Count (4 bytes): 后面紧跟着的是同一个 key 下数据的个数。
Time (8 bytes): 单个 value 的时间戳。
Value (N bytes): value 的具体内容,其中 float64, int64, boolean 都是固定的字节数存储比较简单,通过 Type 字段知道这里 value 的字节数。string 类型比较特殊,对于 string 来说,N bytes 的 Value 部分,前面 4 字节用于存储 string 的长度,剩下的部分才是 string 的实际内容。
2)TSM 文件
单个 tsm 文件的主要格式如下:

主要分为四个部分: Header, Blocks, Index, Footer。
其中 Index 部分的内容会被缓存在内存中,下面详细说明一下每一个部分的数据结构。
Header
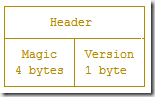
MagicNumber (4 bytes): 用于区分是哪一个存储引擎,目前使用的 tsm1 引擎,MagicNumber 为
0x16D116D1。Version (1 byte): 目前是 tsm1 引擎,此值固定为
1。Blocks
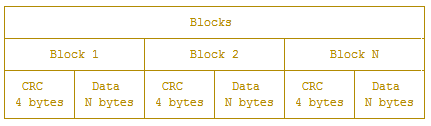
Blocks 内部是一些连续的 Block,block 是 InfluxDB 中的最小读取对象,每次读取操作都会读取一个 block。每一个 Block 分为 CRC32 值和 Data 两部分,CRC32 值用于校验 Data 的内容是否有问题。Data 的长度记录在之后的 Index 部分中。
Data 中的内容根据数据类型的不同,在 InfluxDB 中会采用不同的压缩方式,float 值采用了 Gorilla float compression,而 timestamp 因为是一个递增的序列,所以实际上压缩时只需要记录时间的偏移量信息。string 类型的 value 采用了 snappy 算法进行压缩。
Data 的数据解压后的格式为 8 字节的时间戳以及紧跟着的 value,value 根据类型的不同,会占用不同大小的空间,其中 string 为不定长,会在数据开始处存放长度,这一点和 WAL 文件中的格式相同。
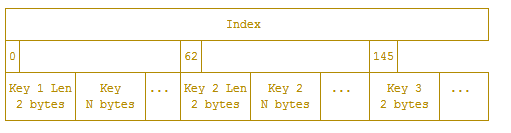
Index

Index 存放的是前面 Blocks 里内容的索引。索引条目的顺序是先按照 key 的字典序排序,再按照 time 排序。InfluxDB 在做查询操作时,可以根据 Index 的信息快速定位到 tsm file 中要查询的 block 的位置。
这张图只展示了其中一部分,用结构体来表示的话类似下面的代码:
type BlockIndex struct { MinTime int64 MaxTime int64 Offset int64 Size uint32 } type KeyIndex struct { KeyLen uint16 Key string Type byte Count uint32 Blocks []*BlockIndex } type Index []*KeyIndexKey Len (2 bytes): 下面一个字段 key 的长度。
Key (N bytes): 这里的 key 指的是 seriesKey + 分隔符 + fieldName。
Type (1 bytes): fieldName 所对应的 fieldValue 的类型,也就是 Block 中 Data 内的数据的类型。
Count (2 bytes): 后面紧跟着的 Blocks 索引的个数。
后面四个部分是 block 的索引信息,根据 Count 中的个数会重复出现,每个 block 索引固定为 28 字节,按照时间排序。
Min Time (8 bytes): block 中 value 的最小时间戳。
Max Time (8 bytes): block 中 value 的最大时间戳。
Offset (8 bytes): block 在整个 tsm file 中的偏移量。
Size (4 bytes): block 的大小。根据 Offset + Size 字段就可以快速读取出一个 block 中的内容。
间接索引
间接索引只存在于内存中,是为了可以快速定位到一个 key 在详细索引信息中的位置而创建的,可以被用于二分查找来实现快速检索。

offsets 是一个数组,其中存储的值为每一个 key 在 Index 表中的位置,由于 key 的长度固定为 2字节,所以根据这个位置就可以找到该位置上对应的 key 的内容。
当指定一个要查询的 key 时,就可以通过二分查找,定位到其在 Index 表中的位置,再根据要查询的数据的时间进行定位,由于 KeyIndex 中的 BlockIndex 结构是定长的,所以也可以进行一次二分查找,找到要查询的数据所在的 BlockIndex 的内容,之后根据偏移量以及 block 长度就可以从 tsm 文件中快速读取出一个 block 的内容。
Footer

tsm file 的最后8字节的内容存放了 Index 部分的起始位置在 tsm file 中的偏移量,方便将索引信息加载到内存中。
五、数据查询与索引结构
由于 LSM Tree 的原理就是通过将大量的随机写转换为顺序写,从而极大地提升了数据写入的性能,与此同时牺牲了部分读的性能。TSM 存储引擎是基于 LSM Tree 开发的,所以情况类似。通常设计数据库时会采用索引文件的方式(例如 LevelDB 中的 Mainfest 文件) 或者 Bloom filter 来对 LSM Tree 这样的数据结构的读取操作进行优化。
InfluxDB 中采用索引的方式进行优化,主要存在两种类型的索引。
1)元数据索引
一个数据库的元数据索引通过 DatabaseIndex 这个结构体来存储,在数据库启动时,会进行初始化,从所有 shard 下的 tsm file 中加载 index 数据,获取其中所有 Measurement 以及 Series 的信息并缓存到内存中。
type DatabaseIndex struct { measurements map[string]*Measurement // 该数据库下所有 Measurement 对象 series map[string]*Series // 所有 Series 对象,SeriesKey = measurement + tags name string // 数据库名 }这个结构体中最主要存放的就是该数据下所有 Measurement 和 Series 的内容,其数据结构如下:


type Measurement struct { Name string `json:"name,omitempty"` fieldNames map[string]struct{} // 此 measurement 中的所有 filedNames // 内存中的索引信息 // id 以及其对应的 series 信息,主要是为了在 seriesByTagKeyValue 中存储Id节约内存 seriesByID map[uint64]*Series // lookup table for series by their id // 根据 tagk 和 tagv 的双重索引,保存排好序的 SeriesID 数组 // 这个 map 用于在查询操作时,可以根据 tags 来快速过滤出要查询的所有 SeriesID,之后根据 SeriesKey 以及时间范围从文件中读取相应内容 seriesByTagKeyValue map[string]map[string]SeriesIDs // map from tag key to value to sorted set of series ids // 此 measurement 中所有 series 的 id,按照 id 排序 seriesIDs SeriesIDs // sorted list of series IDs in this measurement } type Series struct { Key string // series key Tags map[string]string // tags id uint64 // id measurement *Measurement // 所属 measurement // 在哪些 shard 中存在 shardIDs map[uint64]bool // shards that have this series defined }

元数据查询
InfluxDB 支持一些特殊的查询语句(支持正则表达式匹配),可以查询一些 measurement 以及 tags 相关的数据,例如
SHOW MEASUREMENTS SHOW TAG KEYS FROM "measurement_name" SHOW TAG VALUES FROM "measurement_name" WITH KEY = "tag_key"例如我们需要查询 cpu_usage 这个 measurement 上传数据的机器有哪些,一个可能的查询语句为:
SHOW TAG VALUES FROM "cpu_usage" WITH KEY = "host"首先根据 measurement 可以在 DatabaseIndex.measurements 中拿到 cpu_usage 所对应的 Measurement 对象。
通过 Measurement.seriesByTagKeyValue 获取 tagk=host 所对应的以 tagv 为键的 map 对象。
遍历这个 map 对象,所有的 key 则为我们需要获取的数据。
普通数据查询的定位
对于普通的数据查询语句,则可以通过上述的元数据索引快速定位到要查询的数据所包含的所有 seriesKey,fieldName 和时间范围。
举个例子,假设查询语句为获取 server01 这台机器上 cpu_usage 指标最近一小时的数据:
`SELECT value FROM "cpu_usage" WHERE host='server01' AND time > now() - 1h`先根据 measurement=cpu_usage 从 DatabaseIndex.measurements 中获取到 cpu_usage 对应的 Measurement 对象。
之后通过 DatabaseIndex.measurements["cpu_usage"].seriesByTagKeyValue["host"]["server01"] 获取到所有匹配的 series 的 ID值,再通过 Measurement.seriesByID 这个 map 对象根据 series ID 获取它们的实际对象。
注意这里虽然只指定了 host=server01,但不代表 cpu_usage 下只有这一个 series,可能还有其他的 tags 例如 user=1 以及 user=2,这样获取到的 series ID 实际上有两个,获取数据时需要获取所有 series 下的数据。
在 Series 结构体中的 shardIDs 这个 map 变量存放了哪些 shard 中存在这个 series 的数据。而 Measurement.fieldNames 这个 map 可以帮助过滤掉 fieldName 不存在的情况。
至此,我们在 o(1) 的时间复杂度内,获取到了所有符合要求的 series key、这些 series key 所存在的 shardID,要查询数据的时间范围,之后我们就可以创建数据迭代器从不同的 shard 中获取每一个 series key 在指定时间范围内的数据。后续的查询则和 tsm file 中的 Index 的在内存中的缓存相关。
2)TSM File 索引
上文中对于 tsm file 中的 Index 部分会在内存中做间接索引,从而可以实现快速检索的目的。这里看一下具体的数据结构:
type indirectIndex struct { b []byte // 下层详细索引的字节流 offsets []int32 // 偏移量数组,记录了一个 key 在 b 中的偏移量 minKey, maxKey string minTime, maxTime int64 // 此文件中的最小时间和最大时间,根据这个可以快速判断要查询的数据在此文件中是否存在,是否有必要读取这个文件 tombstones map[string][]TimeRange // 用于记录哪些 key 在指定范围内的数据是已经被删除的 }b 直接对应着 tsm file 中的 Index 部分,通过对 offsets 进行二分查找,可以获取到指定 key 的所有 block 的索引信息,之后根据 offset 和 size 信息可以取出一个指定的 block 中的所有数据。
type indexEntries struct { Type byte entries []IndexEntry } type IndexEntry struct { // 一个 block 中的 point 都在这个最小和最大的时间范围内 MinTime, MaxTime int64 // block 在 tsm 文件中偏移量 Offset int64 // block 的具体大小 Size uint32 }在上一节中说明了通过元数据索引可以获取到所有 符合要求的 series key,它们对应的 shardID,时间范围。通过 tsm file 索引,我们就可以根据 series key 和 时间范围快速定位到数据在 tsm file 中的位置。
从 tsm file 中读取数据
InfluxDB 中的所有数据读取操作都通过 Iterator 来完成。
Iterator 是一个抽象概念,并且支持嵌套,一个 Iterator 可以从底层的其他 Iterator 中获取数据并进行处理,之后再将结果传递给上层的 Iterator。
这部分的代码逻辑比较复杂,这里不展开说明。实际上 Iterator 底层最主要的就是通过 cursor 来获取数据。
type cursor interface { next() (t int64, v interface{}) } type floatCursor interface { cursor nextFloat() (t int64, v float64) } // 底层主要是 KeyCursor,每次读取一个 block 的数据 type floatAscendingCursor struct { // 内存中的 value 对象 cache struct { values Values pos int } tsm struct { tdec TimeDecoder // 时间序列化对象 vdec FloatDecoder // value 序列化对象 buf []FloatValue values []FloatValue // 从 tsm 文件中读取到的 FloatValue 的缓存 pos int keyCursor *KeyCursor } }cursor 提供了一个 next() 方法用于获取一个 value 值。每一种数据类型都有一个自己的 cursor 实现。
底层实现都是 KeyCursor,KeyCursor 会缓存每个 Block 的数据,通过 Next() 函数依次返回,当一个 Block 中的内容读完后再通过 ReadBlock() 函数读取下一个 Block 中的内容。











