
1.技术背景
在SQL语句复杂、处理数据量大的AP场景下,单个查询对内存的需求越来越大,多个语句的并发很容易将系统的内存吃满,造成内存不足的问题。为了应对这种问题,GaussDB for DWS引入了内存自适应控制的技术,在上述场景下能够对运行的作业进行内存级的管控,避免高并发场景下内存不足产生的各种问题。
2. GaussDB的静态内存管理机制及缺陷
GaussDB的执行引擎继承自PG,对于优化器生成的执行计划树,总体采取执行算子+流水线的处理方式,如下图所示。
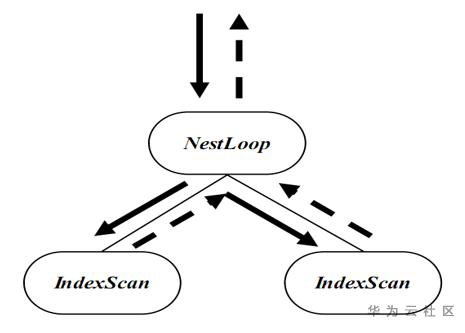
对于NestLoop算子节点,需要首先从左树的IndexScan算子节点获取元组,然后到右子树的IndexScan算子节点进行连接,匹配元组后进行输出。流水线的执行方式使得对于NestLoop, IndexScan类的一般算子,同时只有一定数量的元组处于内存中,对于行引擎每个算子仅占用一条元组的空间,对于列引擎占用一个batch(最多1000条元组)的空间,占用的空间较小,基本可以忽略不计。
但是,GaussDB中也有一些需要将所有数据收集后进行处理的算子,在执行时需要使用较多的内存,通常我们称这类算子为物化算子。GaussDB中主要存在如下不同种类的物化算子:
(1)HashJoin:Hash连接操作符,主要思想是计算左右两表连接列的hash值,通过hash值比较减少元组比较的次数,需要将一个表建立hash表,另一个表进行hash值比较操作,建立hash表需要在内存中进行。
(2)HashAgg:Hash聚集操作符,主要思想同HashJoin类似,通过hash值比较减少元组去重比较的次数,需要将不同值的元组保存的内存中。
(3)Sort:排序操作符,需要获取所有元组后进行排序操作,待排序元组均存在于内存中。
(4)Materialize:物化操作符,通常在需要重复扫描时使用,通过将结果存储在内存中,保证重复扫描时的效率。
同时,GaussDB也提供下盘的机制,当上述操作符需要使用的内存太大时,可以将部分或全部的数据下盘处理,提高内存的使用效率,但相应的查询性能也会受到影响。PG使用 work_mem参数来控制算子可使用内存的阈值,当使用内存超过阈值时,就需要做下盘处理。GaussDB的静态内存管理机制也延续了PG的处理机制,使用work_mem来控制单算子的内存使用上限。
GaussDB的静态内存管理存在较大弊端,需要调优人员能够根据数据量、语句复杂程度和系统的内存大小设置合理的work_mem,既避免work_mem设置太大导致系统资源不够用,还要考虑到数据规模,保证大部分算子不下盘。通常情况下,这个是很难做到的,有以下几点原因:
(1)通常情况下,复杂语句的执行计划中包含多个复杂算子,每个算子的内存使用上限是work_mem,我们没有办法计算一个语句要使用多少内存,因此也就不容易设置一个最优的work_mem参数,保证尽可能不下盘,同时内存又够用。并发场景更无法设置了。
(2)work_mem只是每个算子内存使用的上限,并不是预分配;如果数据量没有那么大的话,实际内存使用是达不到work_mem的。因此也会影响work_mem的设置。
(3)每个语句的场景不一样,有的语句包含多个物化算子,而另外的语句只有一个物化算子,而这个算子对内存的需求会比较大,因此无法全局统一地进行设置。
3. GaussDB的内存自适应技术介绍
针对静态内存管理机制的弊端,我们设计了内存自适应控制技术,目的有两个:
(1)去除静态内存管理对work_mem的依赖。可以由SQL引擎优化器模块自动估算每个算子所需的内存。
(2)避免大并发场景下内存不足现象的发生。资源管理模块根据SQL引擎优化器对于每个查询内存的估算值,对每个查询进行调度,如果超过系统可用内存,则进行排队。
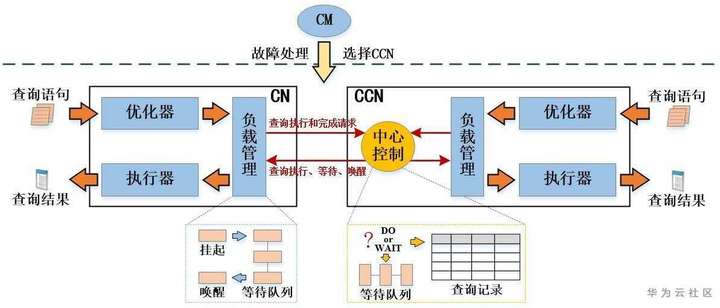
如上图所示,动态资源管理与内存自适应技术的组件图如上图所示。我们从多个CN中选择一个CN,命名为CCN(Central CN),进行语句队列的管理。对于每个查询SQL,CN在生成完执行计划后,为每个物化算子分配合适的内存,同时计算整个语句内存使用量,并将语句及对应的内存使用量发给CCN。CCN维护系统可用的内存值,对于新来的语句,如果语句内存使用量小于可用内存值,则允许其下发到DN执行,否则挂起,等到有语句结束释放内存后再次将其唤醒,是否可以下发。
为了达到上述目的,SQL引擎实现了内存自适应控制技术,步骤如下:
(1)对于每个SQL,生成计划前首先从资源管理模块获取系统当前的最大可用内存(Query Max Mem)和当前可用内存(System Available Mem)。最大可用内存通常为每个DN的最大可用内存去除系统预分配内存,例如:数据缓存等,表示语句可用的最大内存,如果语句使用内存超过该值,必须下盘。当前可用内存用于表示当前系统的繁忙程度,如果当前可用内存比较小,倾向于选择耗费内存少的计划。
(2)依据当前可用内存生成计划,同时根据SQL引擎优化器计划生成过程中的cost估算值估算每个物化算子的内存使用量,以及流水线场景下整个查询使用的内存总量估算值。如果该值大于当前可用内存,则尝试将整个查询的内存使用量调到当前可用内存以下,此时会造成部分算子下盘。
(3)将语句及估算的语句内存发送到CCN,如果当前可用内存小于语句估算内存,则估算语句的内存进一步减少是否对查询性能造成较大的影响,如果根据cost评估影响不大,则进一步减少算子的内存使用,使语句内存使用满足当前可用内存,将语句下发执行,否则则进入排队状态。
(4)由于每个算子的内存使用量是基于cost评估获得,可能存在一定的误差。因此,在SQL语句执行时,支持内存的动态调整,包括:执行算子内存的自动扩展和提前下盘。当算子达到估算的内存值上限,但系统还有宽裕的内存时,会进行算子内存的扩展,继续保持不下盘的状态。当系统已用内存达到80%或更高时,如果算子已有最小内存保证,则会触发提前下盘逻辑,保证不会由于内存不足而报错。
4.GaussDB内存自适应的使用和参数控制
通过开启use_workload_manager和enable_dynamic_workload两个参数开启GaussDB for DWS的内存自适应控制机制。
使用内存自适应机制时,打印SQL语句的explain performance执行计划运行信息时,会包含以下额外的信息辅助定位问题:
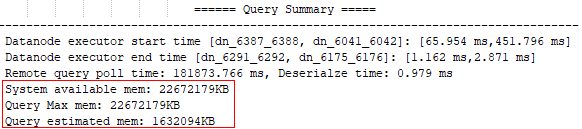
(1)在最下方的Query Summary一栏中,会显示出System available mem、Query max mem和Query estimated mem,分别表示:系统当前可用内存、语句可用最大内存(系统可用最大内存),语句估算内存使用量,均为单DN的衡量值。下图表示当前语句的语句最大可用内存和系统当前可用内存均为22G,语句估算内存使用为1.6G。
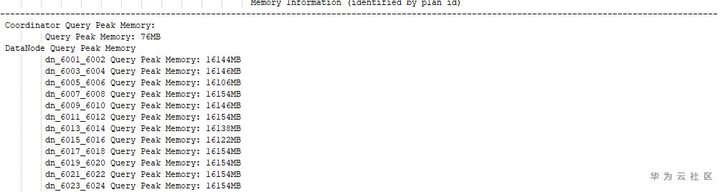
(2)在Memory Information一栏,会显示CN和每个DN的内存使用峰值,如下图所示,语句实际内存使用,单DN使用16GB,CN使用76MB。
(3)在Memory Information一栏下方每个算子对应的位置,会显示每个算子单DN的内存峰值,同时会显示每个DN上内存使用的自动扩展和提前下盘情况,例如下图,可以看出第15号HashJoin算子,每个SMP线程的内存使用均为3.8GB,估算内存是860MB,经历了五次内存自动扩展,在第五次扩展后,系统内存告急,算子未用到第五次扩展后的峰值即提前下盘。

(4)在explain performance最顶层的表格中,汇总了每个算子的估算内存和实际使用内存的情况,见下图的E-memory和Peak Memory两列所示。与上面信息对应,第15号算子单SMP线程的peak memory,最大值为3766MB,最小值为3753MB,估算内存值(单DN4个SMP线程)为860MB。

可以看出,上面例子由于cost估算不准导致内存估算值较小,实际场景也会出现内存估算值较大的场景,会导致CCN预留内存较多,阻塞其它作业的执行。因此,可以使用参数query_mem来控制语句最大可用内存上限(单DN),相当于代替了Query max mem。此参数默认为0,表示未开启。当此值大于32MB(最小语句内存分配值)时,表示开启,此时使用work_mem控制系统当前可用内存进行估算,相当于代替了System available mem进行估算。此时,CCN会使用query_mem值进行语句内存估算值的预留和排队,提高并发场景下的内存使用效率。
5.总结
内存自适应控制技术是GaussDB for DWS的资源管理结合SQL引擎所做的一次尝试,当然还存在一些不足,比如:cost估算对内存的评估影响较大,部分场景存在失真需要进行参数控制;系统中内存使用情况比较复杂,还存在部分内存不在管控范围内需要增强。欢迎各位在实用过程中,将遇到的各种问题及时反馈,也帮助我们更好的改进!












