
限流是保障服务高可用的方式之一,尤其是在微服务架构中,对接口或资源进行限流可以有效地保障服务的可用性和稳定性。
之前的项目中使用的限流措施主要是Guava的RateLimiter。RateLimiter是基于令牌桶流控算法,使用非常简单,但是功能相对比较少。
而现在,我们有了一种新的选择,阿里提供的 Sentinel。
Sentinel 是阿里巴巴提供的一种限流、熔断中间件,与RateLimiter相比,Sentinel提供了丰富的限流、熔断功能。它支持控制台配置限流、熔断规则,支持集群限流,并可以将相应服务调用情况可视化。
目前已经有很多项目接入了Sentinel,而本文主要是对Sentinel的限流功能做一次详细的分析,至于Sentinel的其他能力,则不作深究。
一、总体流程
先来了解一下总体流程:
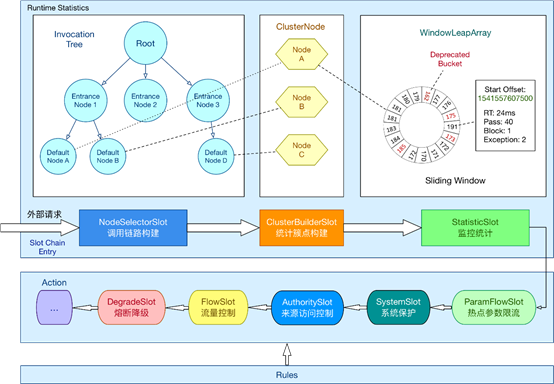
( 引用于Sentinel官网)
上面的图是官网的图,
从设计模式上来看,典型的的责任链模式。外部请求进来后,要经过责任链上各个节点的处理,而Sentinel的限流、熔断就是通过责任链上的这些节点实现的。
从限流算法来看,Sentinel使用滑动窗口算法来进行限流。要想深入了解原理,还是得从源码上入手,下面,直接进入Sentinel的源码阅读。
二、源码阅读
1. 源码阅读入口及总体流程
读源码先得找到源码入口。我们经常使用@ SentinelResource来标记一个方法,可以将这个被@ SentinelResource标记的方法看成是一个Sentinel资源。因此,我们以@ SentinelResource为入口,找到其切面,看看切面拦截后所做的工作,就可以明确Sentinel的工作原理了。直接看注解@SentinelResource的切面代码(SentinelResourceAspect)。
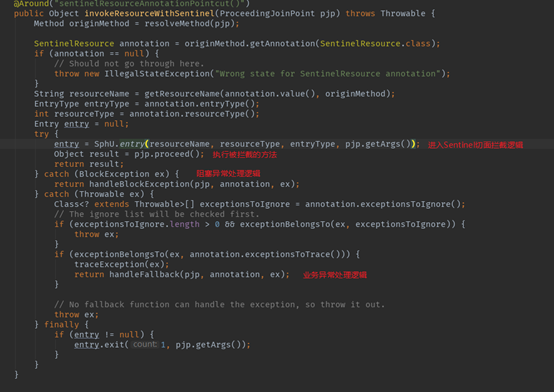
可以清晰的看到Sentinel的行为方式。进入SentinelResource切面后,会执行SphU.entry方法,在这个方法中会对被拦截方法做限流和熔断的逻辑处理。
如果触发熔断和限流,会抛出BlockException,我们可以指定blockHandler方法来处理BlockException。而对于业务上的异常,我们也可以配置fallback方法来处理被拦截方法调用产生的异常。
所以,Sentinel熔断限流的处理主要是在SphU.entry方法中,其主要处理逻辑见下图源码。
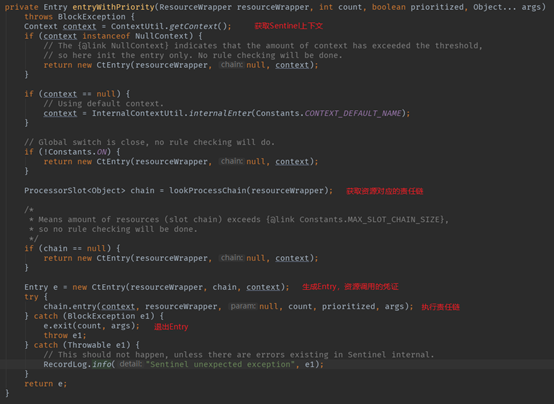
可见,在SphU.entry方法中,Sentinel实现限流、熔断等功能的流程可以总结如下:
获取Sentinel上下文(Context);
获取资源对应的责任链;
生成资源调用凭证(Entry);
执行责任链中各个节点。
接下来,围绕这几个方面,对Sentinel的服务机制做一个系统的阐述。
2. 获取Sentinel上下文(Context)
Context,顾名思义,就是Sentinel熔断限流执行的上下文,包含资源调用的节点和Entry信息。
来看看Context的特征:
- Context是线程持有的,利用ThreadLocal与当前线程绑定。

- Context包含的内容

这里就引出了Sentinel的三个比较重要的概念:Conetxt,Node,Entry。这三个类是Sentinel的核心类,提供了资源调用路径、资源调用统计等信息。
Context
Context是当前线程所持有的Sentinel上下文。
进入Sentinel的逻辑时,会首先获取当前线程的Context,如果没有则新建。当任务执行完毕后,会清除当前线程的context。Context 代表调用链路上下文,贯穿一次调用链路中的所有 Entry。
Context 维持着入口节点(entranceNode)、本次调用链路的 当前节点(curNode)、调用来源(origin)等信息。Context 名称即为调用链路入口名称。
Node
Node是对一个@SentinelResource标记的资源的统计包装。
Context中记录本当前线程资源调用的入口节点。
我们可以通过入口节点的childList,可以追溯资源的调用情况。而每个节点都对应一个@SentinelResource标记的资源及其统计数据,例如:passQps,blockQps,rt等数据。
Entry
Entry是Sentinel中用来表示是否通过限流的一个凭证,如果能正常返回,则说明你可以访问被Sentinel保护的后方服务,否则Sentinel会抛出一个BlockException。
另外,它保存了本次执行entry()方法的一些基本信息,包括资源的Context、Node、对应的责任链等信息,后续完成资源调用后,还需要更具获得的这个Entry去执行一些善后操作,包括退出Entry对应的责任链,完成节点的一些统计信息更新,清除当前线程的Context信息等。
3. 获取@SentinelResource标记资源对应的责任链
资源对应的责任链是限流逻辑具体执行的地方,采用的是典型的责任链模式。
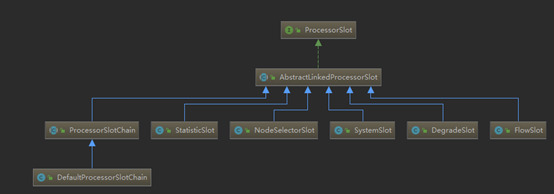
先来看看默认的的责任链的组成:
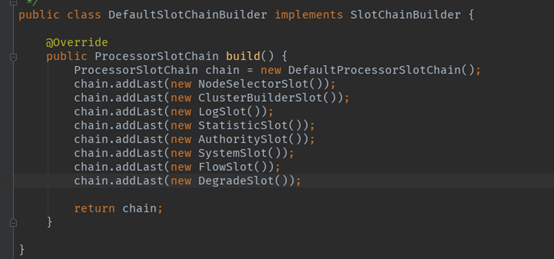
默认的责任链中的处理节点包括NodeSelectorSlot、ClusterBuilderSlot、StatisticSlot、FlowSlot、DegradeSlot等。调用链(ProcessorSlotChain)和其中包含的所有Slot都实现了ProcessorSlot接口,采用责任链的模式执行各个节点的处理逻辑,并调用下一个节点。
每个节点都有自己的作用,后面将会看到这些节点具体是干什么的。
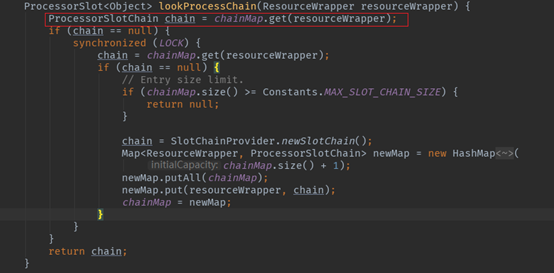
此外,相同资源(@SentinelResource标记的方法)对应的责任链是一致的。也就是说,每个资源对应一条单独的责任链,可以看下源码中资源责任链的获取逻辑:先从缓存获取,没有则新建。
4. 生成调用凭证Entry
生成的Entry是CtEntry。其构造参数包括资源包装(ResourceWrapper)、资源对应的责任链以及当前线程的Context。
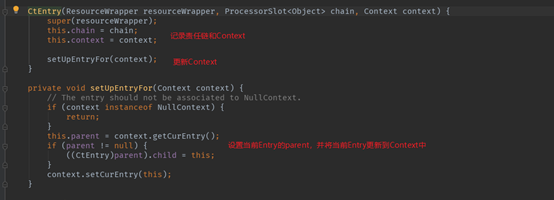
可以看到,新建CtEntry记录了当前资源的责任链和Context,同时更新Context,将Context的当前Entry设置为自己。可以看到,CtEntry是一个双向链表,构建了Sentinel资源的调用链路。
5. 责任链的执行
接下来就进入了责任链的执行。责任链和其中的Slot都实现了ProcessorSlot,责任链的entry方法会依次执行责任链各个slot,所以下面就进入了责任链中的各个Slot。为了突出重点,这次本文只研究与限流功能有关的Slot。
5.1 NodeSelectorSlot -- 获取当前资源对应Node,构建节点调用树
此节点负责获取或者构建当前资源对应的Node,这个Node被用于后续资源调用的统计及限流和熔断条件的判断。同时,NodeSelectorSlot还会完成调用链路构建。来看源码:
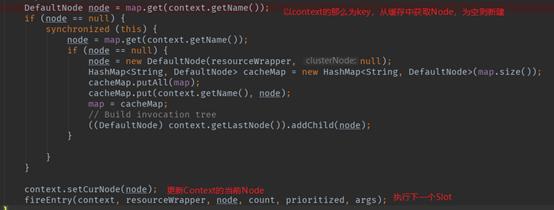

熟悉的代码风格。我们知道一个资源对应一个责任链。每个调用链中都有NodeSelectorSlot。NodeSelectSlot中的node缓存map是非静态变量,所以map只对当前这个资源共用,不同的资源对应的NodeSelectSlot及Node的缓存都是不一样的,资源和Node缓存map的关系可见下图。
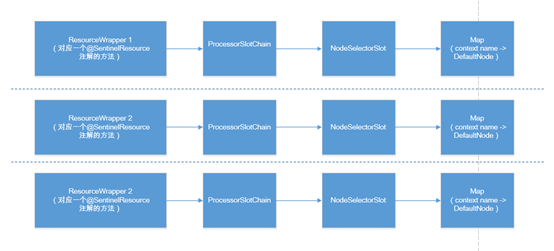
所以NodeSelectorSlot的的作用是:
在资源对应的调用链执行时,获取当前context对应的Node,这个Node代表着这个资源的调用情况。
将获取到的node设为当前node,添加到之前的node后面,形成树状的调用路径。(通过Context中的当前Entry进行)
触发下一个Slot的执行。
这里有个很有趣的问题,就是我们在责任链的NodeSelectorSlot中获取资源对应的Node时,为什么用的是Context的name,而不是SentinelResource的name呢?
首先,我们知道一个资源对应一条责任链。但是进入一个资源调用的Context却可能是不同的。如果使用资源名来作为key,获取对应的Node,那么通过不同context进来的调用方法获取到的Node就都是同一个了。所以通过这种方式,可以将相同resource对应的node按Context区分开。
举个例子,Sentinel功能的实现不仅仅可以通过@SentinelResource注解方法来实现,也可以通过引入相关依赖(sentinel-dubbo-adapter),利用Dubbo的Filter机制直接对DUBBO接口进行保护。我们来比较@SentinelResource和Dubbo方式生成Context的区别:
@SentinelResource
生成的context的name是:sentinel_default_context。所有资源对应的Context都是这个值。
Dubbo Filter方式
生成的context的name是Dubbo的接口限定名或者方法限定名。
如果出现嵌套在Dubbo Filter方式下面的其他SentinelResource的资源调用,那么这些资源调用的就会就会出现不同的Context。
所以有这样一种情况,不同的dubbo接口进来,这些dubbo接口都调用了同一个@SentinelResource标记的方法,那么这个方法对应的SentinelReource的在执行时对应的Context就是不同的。
另一个问题是,既然资源按Context分出了不同的node,那我们想看资源总数统计是怎么办呢?这就涉及到ClusterNode了。详细可见ClusterBuilderSlot。
5.2 ClusterBuilderSlot -- 聚合相同资源不同Context的Node
此节点负责聚合相同资源不同Context对应的Node,以供后续限流判断使用。
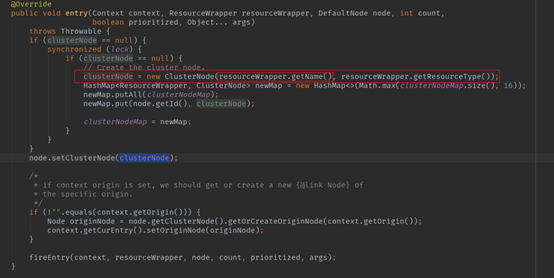
可以看到,ClusterNode的获取是以资源名为key。ClusterNode将会成为当前node的一个属性,主要目的是为了聚合同一个资源不同Context情况下的多个node。默认的限流条件判断就是依据ClusterNode中的统计信息来进行的。
5.3 StatisticSlot -- 资源调用统计
此节点主要负责资源调用的统计信息的计算和更新。与前面以及后面的slot不同,StatisticSlot的执行时先触发下一个slot的执行,等下面的slot执行完才会执行自己的逻辑。
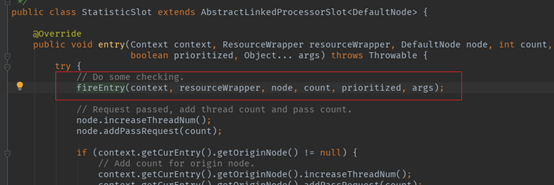
这也很好理解,作为统计组件,总要等熔断或者限流处理完之后才能做统计吧。下面看一下具体的统计过程。
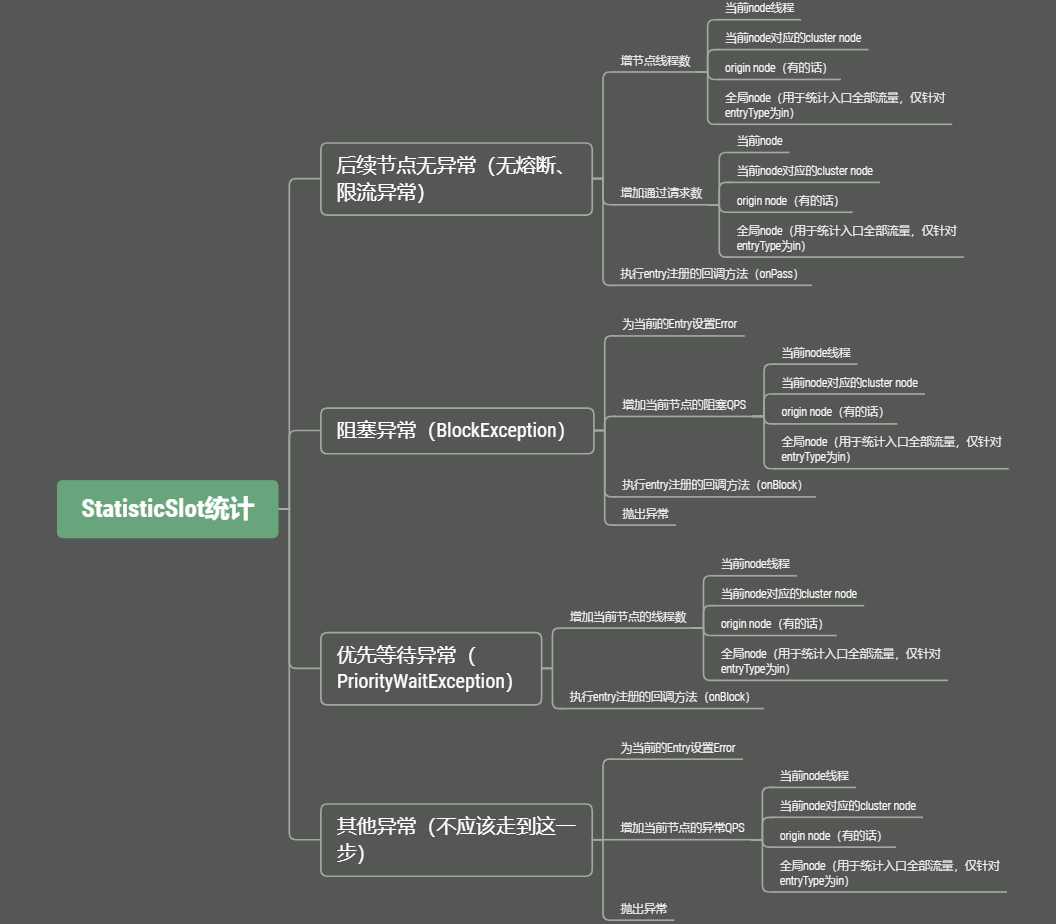
上面这张图已经很清晰的描述了StatisticSlot的数据统计的过程。可以注意一下无异常和阻塞异常的情况,主要是更新线程数、通过请求数量和阻塞请求数量。不管是DefaultNode,还是ClusterNode,都继承自StatisticNode。所以Node的数据更新要来到StatisticNode。
参考Sentinel数据统计框图,描述了Node统计数据更新的大体流程如下:
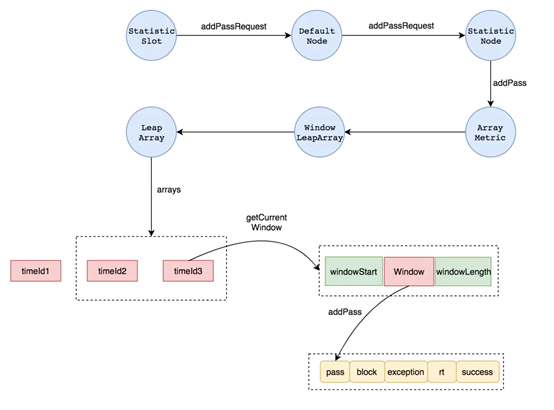
我们从StatisticNode.addPassRequest()方法入手,以passQps为例,探究StatisticNode是如何更新通过请求的QPS计数的。

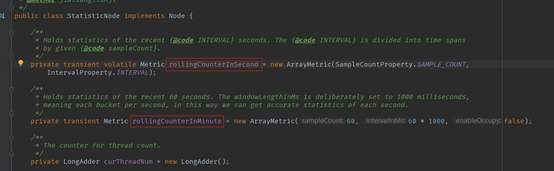
从源码可见,计数变量rollingCounterInSecond和rollingCounterInMinute都是Metric,两个变量的时间维度分别是秒和分钟。rollingCounterInSecond和rollingCounterInMinute用的是Metric的实现类ArrayMetric。
从ArrayMetric追溯下去:
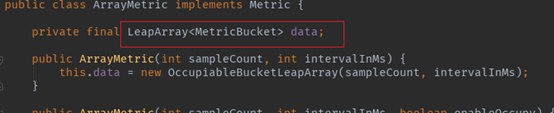

统计信息都是保存到ArrayMetric的data,也就是LeapArray

LeapArray是时间窗口数组。基本信息包括:时间窗口长度(ms,windowLengthInMs),取样数(也就是时间窗口的数量,sampleCount),时间间隔(ms,intervalInMs),以及时间窗口数组(array)。时间窗口长度、取样数及时间间隔有下面的关系:
windowLengthInMs = intervalInMs / sampleCount
代码中rollingCounterInSecond使用的intervalInMs 是1000(ms),也就是1s,sampleCount=2。所以,窗口时长就是windowLengthInMs = 500ms。rollingCounterInMinute使用的intervalInMs 是60 * 1000(ms),也就是60s。sampleCount=60,所以,windowLengthInMs = 1000ms,也就是1s。
时间窗口数组(array)是类型是AtomicReferenceArray,可见这是一个原子操作的的数组引用。数组元素类型是WindowWrap
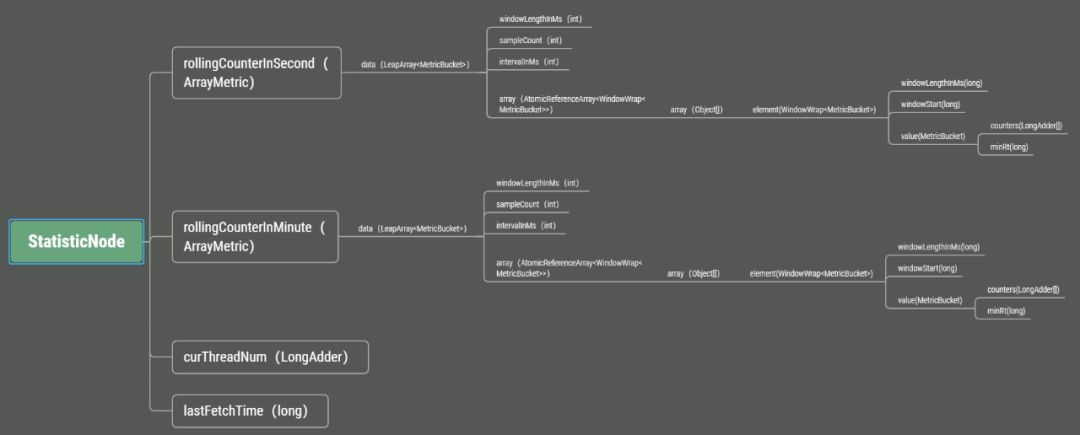
回到StatisticNode.addPassRequest方法,以rollingCounterInSecond.addPass(count)为例,探究Sentinel如何进行滑动窗口计数的。
5.3.1 获取当前时间窗口
(1)取当前时间戳对应的数组下标
long timeId = time / windowLength
int idx = (int)(timeId % array.length());
time为当前时间,windowLength为时间窗口长度,rollingCounterInSecond的时间窗口长度是500ms。array 是单位时间内时间窗口的数量,rollingCounterInSecond的单位时间(1s)时间窗口数是2。timeId是当前时间对时间窗口的整除。time每增加一个windowLength的长度,timeId就会增加1,时间窗口就会往前滑动一个。
(2)计算窗口开始时间
窗口开始时间 = 当前时间(ms)-当前时间(ms)%时间窗口长度(ms)
获取的窗口开始时间均为时间窗口的整数倍。
(3)获取时间窗口
首先,根据数组下标从LeapArray的数组中获取时间窗口。
如果获取到的时间窗口自为空,则新建时间窗口(CAS)。
如果获取到的时间窗口非空,且时间窗口的开始时间等于我们计算的开始时间,说明当前时间正好在这个时间窗口里,直接返回该时间窗口。
如果获取到的时间窗口非空,且时间窗口的开始时间小于我们计算的开始时间,说明时间窗口已经过期(距离上次获取时间窗口已经过去比较久的场景),需要更新时间窗口(加锁操作),将时间窗口的开始时间设为计算出来的开始时间,将时间窗口里的计数器重置为0。
如果获取到的时间窗口非空,且时间窗口的开始时间大于我们计算的开始时间,创建新的时间窗口。这个一般不会走进这个分支,因为说明当前时间已经落后于时间窗口了,获取到的时间窗口是将来的时间,那就没有意义了。
5.3.2 对时间窗口的计数器进行累加
时间窗口计数器是一个LongAdder数组,这个数组用于存放通过请求数、异常请求数、阻塞请求数等数据。如下图:

其中,通过计数、阻塞计数、异常计数为执行StatisticSlot的entry方法时更新。成功计数及响应时间是执行StatisticSlot的exit方法时更新。其实就是分别在被拦截方法执行前和执行后进行相应计数的更新。当然,addPass就是在计数数组的第一个元素上进行累加。
计数数组元素类型是LongAdder。LongAdder是JDK8添加到JUC中的。它是一个线程安全的、比Atomic*系工具性能更好的"计数器"。
5.4 FlowSlot -- 限流判断
FlowSlot是进行限流条件判断的节点。之前在StatisticSlot对相关资源调用做的统计,在FlowSlot限流判断时将会得到使用。
直接来到限流操作的核心逻辑–限流规则检查器(FlowRuleChecker):
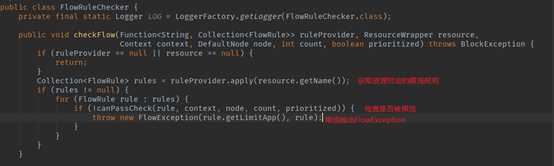
主要的流程包括:
获取资源对应的限流规则
根据限流规则检查是否被限流
如果被限流,则抛出限流异常FlowException。FlowException继承自BlockException。
那么FlowSlot检查是否限流的过程是怎么样的?
默认情况下,限流使用的节点是当前节点的cluster node。主要分析的限流方式是QPS限流。来看一下限流的关键代码(DefaultController):
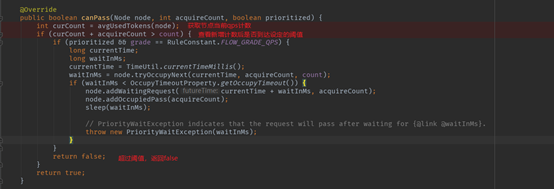
获取节点的当前qps计数;
判断获取新的计数后是否超过阈值
超过阈值单返回false,表示被限流,后面会抛出FlowException。否则返回true,不被限流。
可以看到限流判断非常简单,只需要对qps计数进行检查就可以了。这归功于StatisticSlot做的数据统计。
5.5 责任链小结
通过上面的讲解,再来看下面这张图,是不是很清晰了?
( 引用于Sentinel官网)
NodeSelectorSlot用于获取资源对应的Node,并构建Node调用树,将SentinelSource的调用链路以Node Tree的形式组起来。ClusterBuilderSlot为当前Node创建对应的ClusterNode,聚合相同资源对应的不同Context的Node,后续的限流依据就是这个ClusterNode。
ClusterNode继承自StatisticNode,记录着相应资源处理的一些统计数据。StatisticSlot用于更新资源调用的相关计数,用于后续的限流判断使用。FlowSlot根据资源对应Node的调用计数,判断是否进行限流。至此,Sentinel的责任链执行逻辑就完整了。
6. Sentienl 的收尾工作
无论执行成功还是失败,或者是阻塞,都会执行Entry.exit()方法,来看一下这个方法。
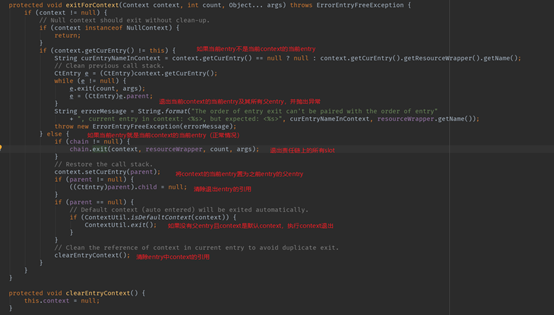
判断要退出的entry是否是当前context的当前entry;
如果要退出的entry不是当前context的当前entry,则不退出此entry,而是退出context的的当前entry及其所有父entry,并抛出异常;
如果要退出的entry是当前context的当前entry(这种是正常情况),先退出当前entry对应的责任链的所有slot。在这一步,StatisticSlot会更新node的success计数和RT计数;
将context的当前entry置为被退出的entry的父entry;
如果被退出entry的父entry为空,且context为默认context,自动退出默认context(清除ThreadLocal)。
清除被退出entry的context引用
7. 总结
通过阅读Sentinel的源码,可以很清晰的理解Sentinel的限流过程了,而对上面的源码阅读,总结如下:
三大组件Context、Entry、Node,是Sentinel的核心组件,各类信息及资源调用情况都由这三大类持有;
采用责任链模式完成Sentinel的信息统计、熔断、限流等操作;
责任链中NodeSelectSlot负责选择当前资源对应的Node,同时构建node调用树;
责任链中ClusterBuilderSlot负责构建当前Node对应的ClusterNode,用于聚合同一资源对应不同Context的Node;
责任链中的StatisticSlot用于统计当前资源的调用情况,更新Node与其对用的ClusterNode的各种统计数据;
责任链中的FlowSlot根据当前Node对应的ClusterNode(默认)的统计信息进行限流;
资源调用统计数据(例如PassQps)使用滑动时间窗口进行统计;
所有工作执行完毕后,执行退出流程,补充一些统计数据,清理Context。
三、参考文献
https://github.com/alibaba/Sentinel/wiki
作者:Sun Yi












