
一、前言
在前面几篇文章中,相信大家对vivo官网商城的前端架构演变有了一定的了解,从稳步推进前后端分离到小程序多端探索实践,团队不断创新尝试。
在本文中,我们来分享一下vivo官网商城在Node 服务端渲染(Server Side Rendering, SSR)方面的实战经验。本文主要围绕以下几个方面进行阐述:
- CSR与SSR的对比
- 性能优化
- 自动化部署
- 容灾、降级
- 日志、监控
二、背景
vivo官网商城目前前后端分离采用的是SPA单页模式,SPA会把所有 JS 整体打包,无法忽视的问题就是文件太大,导致渲染前等待很长时间。特别是网速差的时候,让用户等待白屏结束并非一个很好的体验。因此 vivo 官网商城前端团队尝试引入了SSR技术,以此来加快页面首屏的访问速度,从而提升用户体验。
三、SSR简介
3.1 什么是SSR?
页面渲染主要分为客户端渲染(Client Side Render)和服务端渲染(Server Side Rendering):
- 客户端渲染(CSR)
服务端只返回一个基本的html模板,浏览器根据html内容去加载js,获取数据,渲染出页面内容;
- 服务端渲染(SSR)
页面的内容是在服务端渲染完成,返回到浏览器直接展示。
3.2 为什么要使用SSR?
与传统 SPA (单页应用程序 (Single-Page Application)) 相比,SSR的优势主要在于:
- **更好的搜索引擎优化(SEO)**,SPA应用程序初始展示loading菊花图,然后通过Ajax获取内容,搜索引擎并不会等待异步完成后再行抓取页面内容;
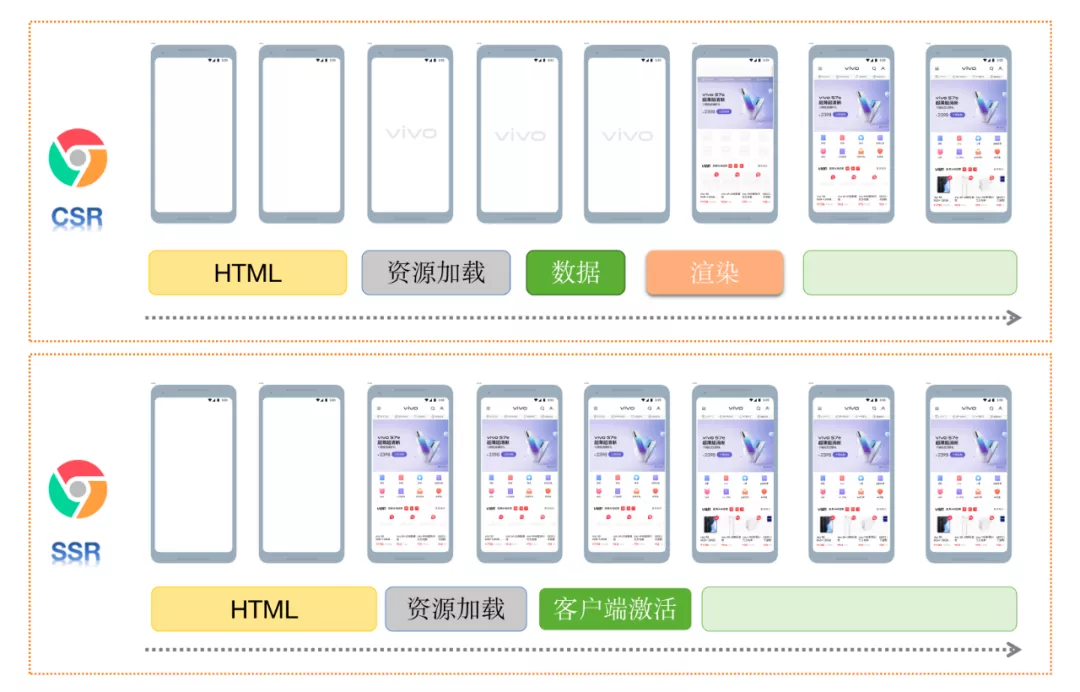
- **更快的内容到达时间 (time-to-content)**,特别是对于缓慢的网络情况或运行缓慢的设备,无需等待所有的JavaScript都完成下载并执行,才显示服务器渲染的标记,用户能够更快速地看到完整渲染的页面,提升用户体验。下图能够更直观的反应加载时效果。
CSR和SSR页面渲染对比:

四、SSR 实践
vivo官网商城项目的技术栈是Vue, 考虑到从头搭建一套服务端渲染的应用比较复杂,所以选择了Vue官方推荐的 Nuxt.js 框架,这是基于 Vue 生态的更高层的框架,为开发服务端渲染的 Vue 应用提供了极其便利的开发体验。
这里不做基础使用的分享,有兴趣的同学可以到 Nuxt.js官网 学习基础用法;我们主要聚焦于在整个实践过程中,主要遇到的一些挑战:
- 性能:如何进行性能优化,提升QPS,节约服务器资源?
- 容灾:如何做好容灾处理,实现自动降级?
- 日志:如何接入日志,方便问题定位?
- 监控:如何对Node服务进行监控?
- 部署:如何打通公司CI/CD流程,实现自动化部署?
4.1 性能优化
虽然Vue SSR渲染速度已经很快,但是由于创建组件实例和虚拟DOM节点的开销,与基于字符串拼接的模板引擎的性能相差很大,在高并发情况下,服务器响应会变慢,极大的影响用户体验,因此必须进行性能优化。
4.1.1 方案1 启用缓存
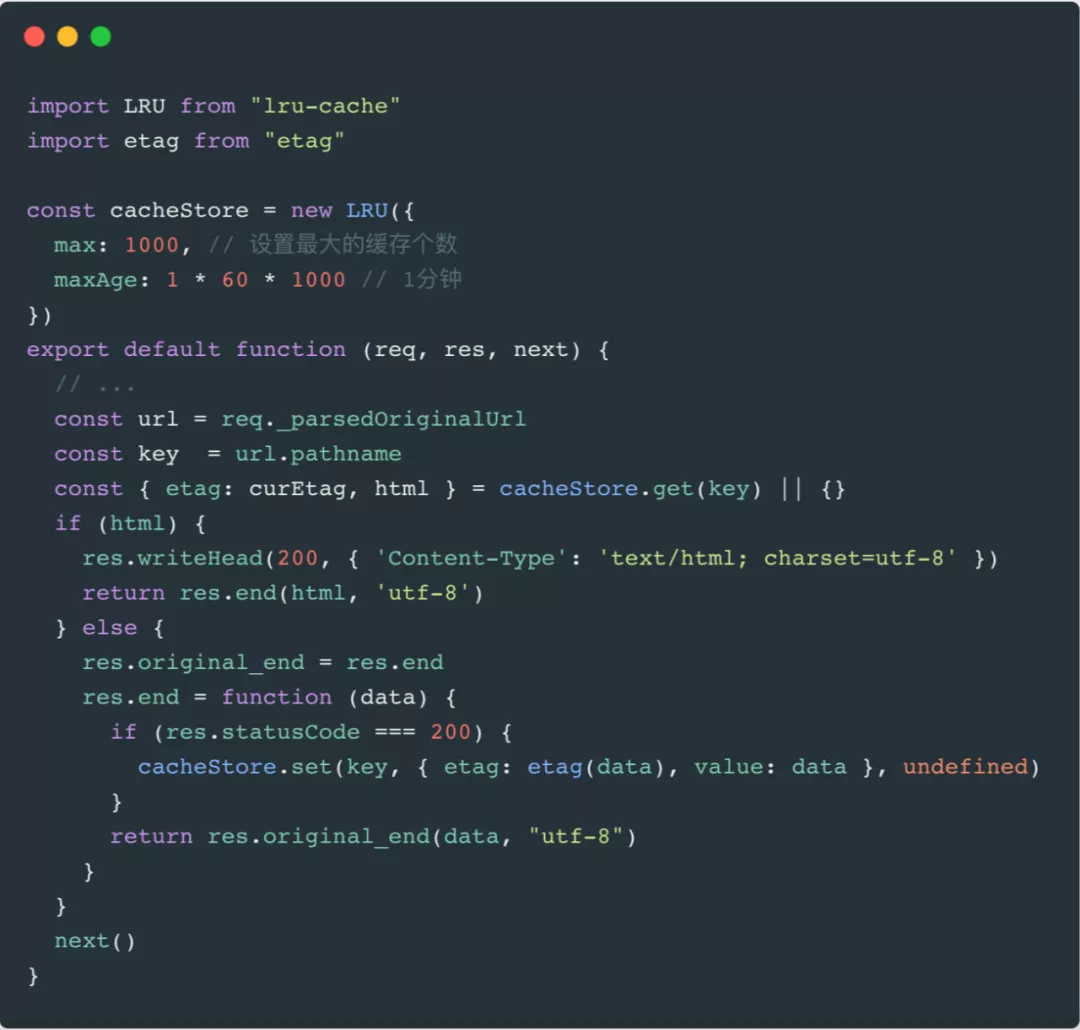
a、页面缓存: 在创建render实例时利用 LRU-Cache 来缓存渲染好的html,当再有请求访问该页面时,直接将缓存中的html字符串返回。
nuxt.config.js增加配置:
serverMiddleware: ["~/serverMiddleware/pageCache.js"]
根目录创建serverMiddleware/pageCache.js

b、组件缓存: 将渲染后的组件DOM存入缓存,定时刷新,有效期内取缓存中DOM。主要适用于重复使用的组件,多用于列表,例如商品列表。
配置文件nuxt.config.js:
const LRU = require('lru-cache')
module.exports = {
render: {
bundleRenderer: {
cache: LRU({
max: 1000, // 最大的缓存个数
maxAge: 1000 * 60 * 5 // 缓存5分钟
})
}
}
}
缓存组件增加name及serverCacheKey作为唯一键值:
export default {
name: 'productList',
props: ['productId'],
serverCacheKey: props => props.productId
}
c、API缓存: Node服务器需要先调用后台接口,获取到数据,然后才能进行渲染,获取接口速度的快慢,直接影响到渲染的时间,对接口的缓存可以加快每个请求的处理速度,更快地释放掉请求,从而提高性能。API缓存主要适用于数据基本保持不变,变更不是很频繁,与用户个人数据无关的接口。
4.1.2 方案2 接口并发请求
同一个页面,在Node层可能会同时调用多个接口,如果是串行调用,需要等待的时间会比较长,如果是并发请求,会缩小等待时间。
例如:
let data1 = await $axios.get('接口1')
let data2 = await $axios.get('接口2')
let data3 = await $axios.get('接口3')
可以改成:
let {data1,data2,data3} = await Promise.all([
$axios.get('接口1'),
$axios.get('接口2'),
$axios.get('接口3')
])
4.1.3 方案3 首屏最小化
影响用户体验主要是首屏的白屏时间,而第二屏、第三屏...,并不需要立即显示。以商品详情页为例,如下图:

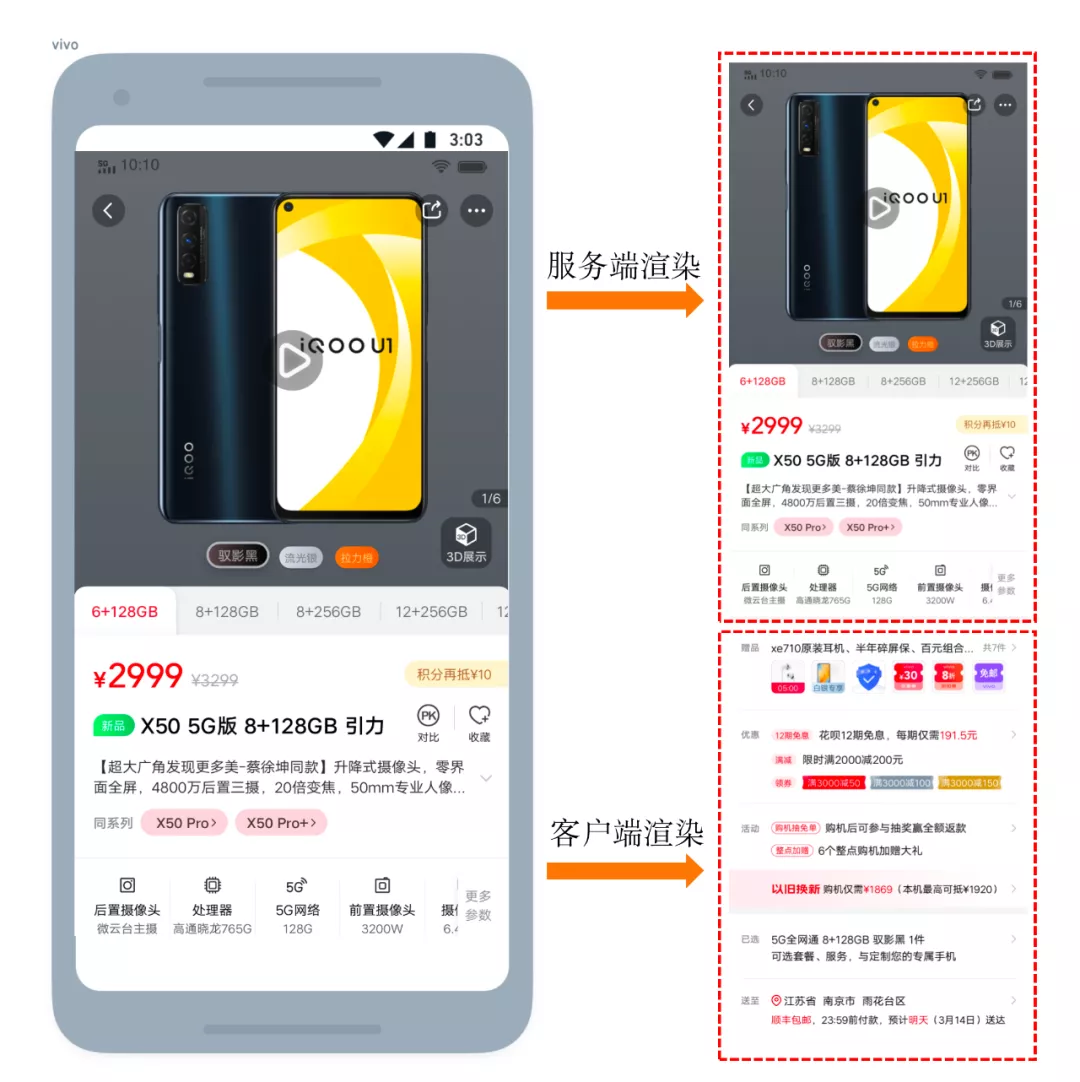
可以对页面结构进行拆分,首屏元素采用SSR,非首屏元素通过CSR;SSR数据需要通过asyncData方法来获取,CSR数据可以在mounted中获取。
CSR写法如下:
<client-only>
客户端渲染dom
</client-only>
4.1.4 方案4 部分页面采用CSR
并不是所有页面对体验、SEO要求都很高,像商城这样的业务,可以只对首页、商品详情页等核心页面做SSR,这样可以大大减少服务端的压力。
4.1.5 优化前后性能压测对比
优化前:
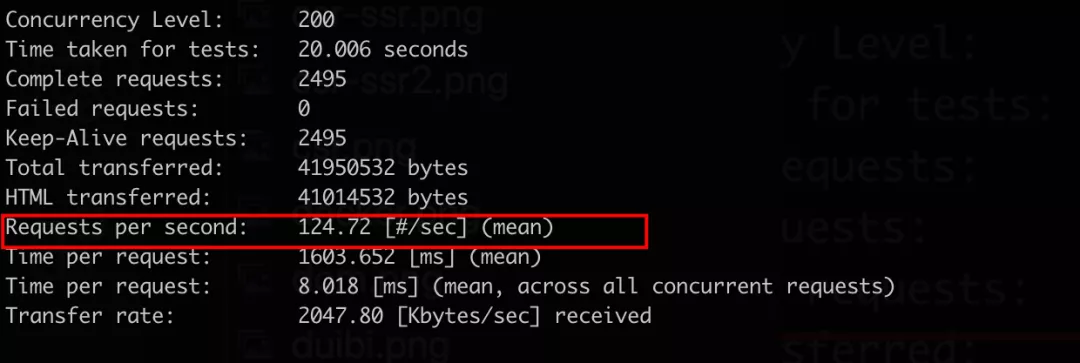

优化后:
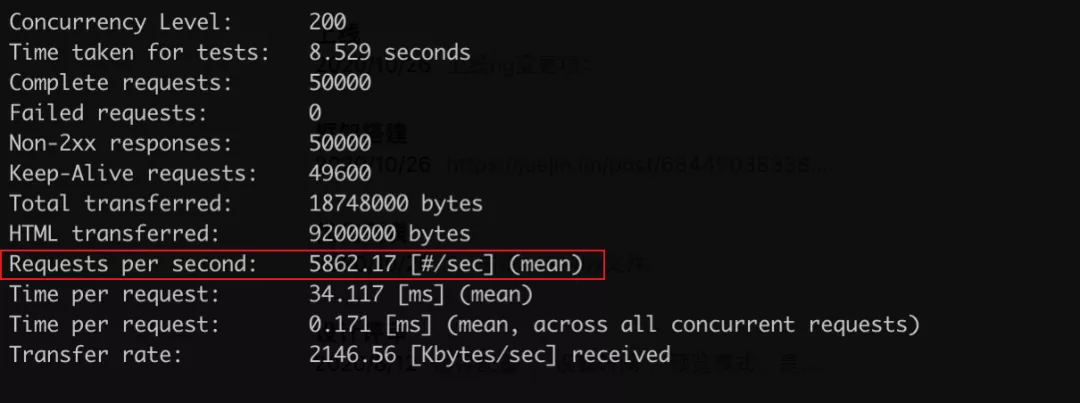

从上图可以看出,未经优化前QPS只有125,经过一系列优化QPS达到了6000,提升了接近 50倍。
这里的降级是指将SSR降级为CSR,使用Node做SSR,瓶颈在于CPU和内存,在高并发情况下,很容易导致CPU飙升,用户访问页面时间变长,如果Node服务器挂了,直接会导致页面访问不了。所以为了保证项目上线之后平稳运行,需要提供容灾、降级方案。
Nuxt.js可以同时支持CSR和SSR,我们在打包时,既生成SSR的包,同时生成CSR的包,分别进行部署。
项目中采用了以下几种降级方案:
4.2 降级策略
4.2.1 监控系统降级
Node服务器上启动一个服务,用来监测Node进程的CPU和内存使用率,设定一个阈值,当达到这个阈值时,停止SSR,直接将CSR的入口文件index.html返回,实现降级。
4.2.2 Nginx降级策略

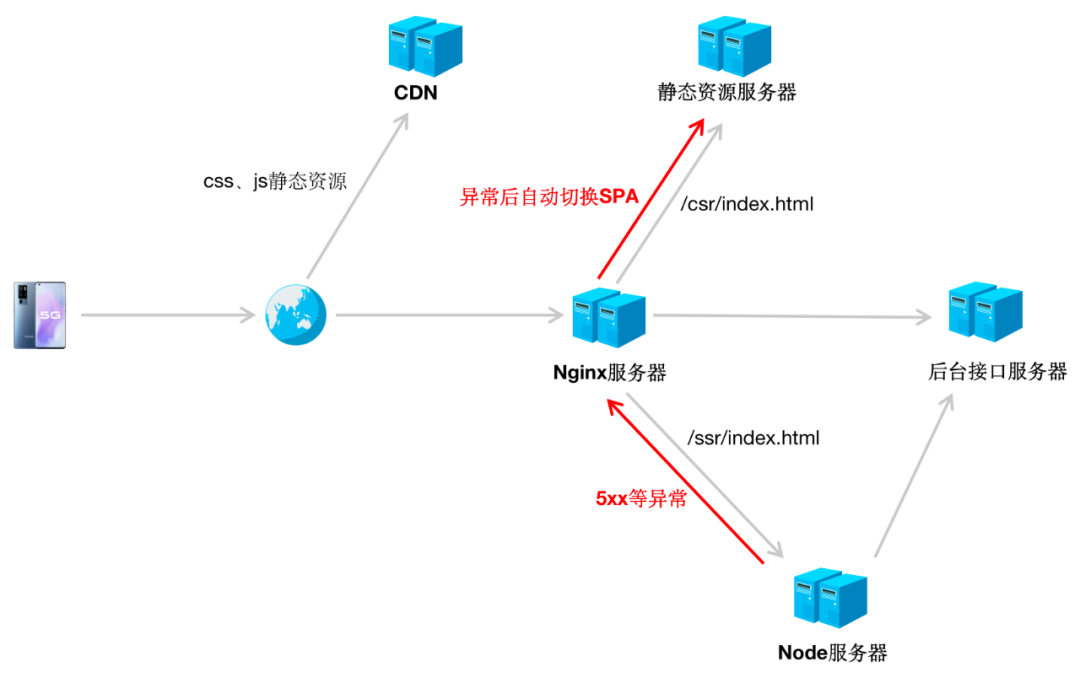
4.2.2.1 全平台降级
例如618,双11等大促期间,我们事先知道流量会很大,可以提前通过修改Nginx配置,将请求转发到静态服务器,返回index.html,切换到CSR。
4.2.2.2 单次访问降级
当偶发性的Node服务器返回5xx错误码,或者Node服务器直接挂了,我们可以通过如下Nginx配置,做到自动切换到CSR,保证用户能正常访问。
Nginx配置如下:
location / {
proxy_pass Node服务器地址;
proxy_intercept_errors on;
error_page 408 500 501 502 503 504 =200 @spa_page;
}
location @spa_page {
rewrite ^/* /spa/200.html break;
proxy_pass 静态服务器;
}
4.2.2.3 指定渲染方式
在url中增加参数isCsr=true,Nginx层对参数isCsr进行拦截,如果带上该参数,指向CSR,否则指向SSR;这样就可以通过url参数配置来进行页面分流,减轻Node服务器压力。
4.3 CI/CD 自动化部署
基于公司的CI/CD,我们实现了Docker部署和Shell脚本部署两种自动化部署方案。
4.3.1 方案1 Shell脚本构建、部署
对于Shell脚本的方式,我们主要解决的问题是如何通过脚本来安装指定Node的版本,这里我们可以分为两步:
1、安装nvm, nvm 是Node.js 的版本管理器(version manager)
2、通过nvm安装或者切换成对于的Node版本
# 定义安装nvm的方法
install_nvm() {
echo "env $app_env install nvm ..."
wget --header='Authorization:Basic dml2b2Rldm9wczp4TFFidmtMbW9ZKn4x' -nv -P .nvm http://xxx/download/nvm-master.zip
unzip -qo .nvm/nvm-master.zip
mv nvm-master/* $NVM_DIR
rm -rf .nvm
rm -rf nvm-master
. "$NVM_DIR/nvm.sh"
if [[ $? = 1 ]];
then
echo "install nvm fail"
else
echo "install nvm success"
fi
}
# 定义安装Node的方法
install_node() {
# command_args为用户自定义的Node版本号
local USE_NODEVER=$command_args
echo "will install NodeJs $USE_NODEVER"
nvm install $USE_NODEVER >/dev/null
echo "success change to NodeJs version" $(node -v)
}
# Node环境安装
prepare() {
if [[ -s "$NVM_DIR/nvm.sh" ]];
then
. "$NVM_DIR/nvm.sh"
else
install_nvm
fi
echo "nvm version $(nvm --version)"
install_node
}
4.3.2 方案2 Docker构建、部署
Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
# 基础镜像
FROM node:12.16.0
# 创建文件存放目录
RUN mkdir -p /home/docker-demo
WORKDIR /home/docker-demo
COPY . /home/docker-demo
# 安装依赖
RUN yarn install
# 打包,并把静态资源进行md5压缩
RUN yarn prod
# 静态资源部署CDN
RUN yarn deploy
# 端口号
EXPOSE 3000
# 项目启动命令
CMD npm start
相比较而言,Docker部署具有很大优势:
- 构建、部署更加方便
- 一致的运行环境「这段代码在我机器上没问题啊」
- 弹性伸缩
- 更高效的利用系统资源
- 快 - 管理操作(启动,停止,开始,重启等)都是以秒或毫秒为单位
4.4 监控、告警
监控是整个产品生命周期中非常重要的一环,事前及时预警发现故障,事后提供详实的数据用于追查定位问题。
在应用出现故障时,需要有合适的工具链来支撑问题的定位修复,我们引入了开源的企业级 Node.js 应用性能监控与线上故障定位解决方案Easy-Monitor,可以更好地监控 Node.js 应用状态,来面对性能和稳定性方面的挑战。我们在内网部署了这套系统,并进行了二次开发,集成了内网域登录,并可以通过内部聊天工具推送告警信息。

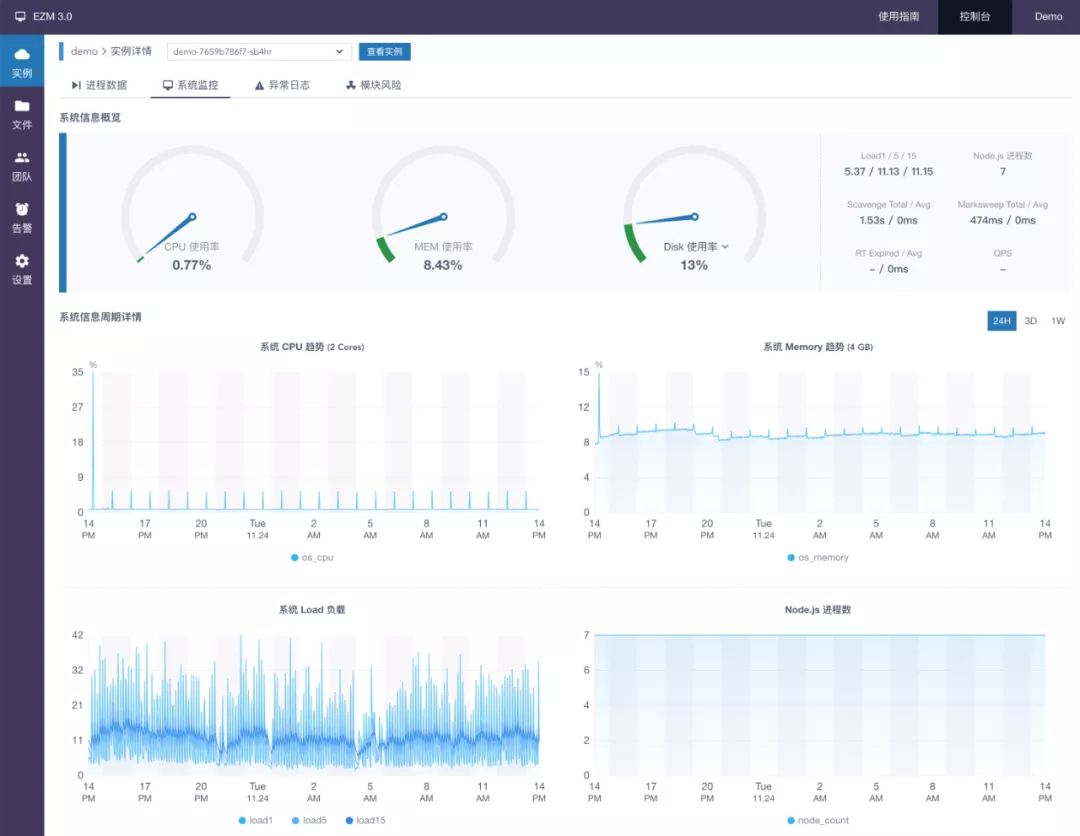
4.5 日志
应用上线后,一旦发生异常,第一件事情就是要弄清当时发生了什么,比如用户当时如何操作、数据如何响应等,此时日志信息就给我们提供了第一手资料。因此我们需要接入公司的日志系统。
4.5.1 实现
日志组件基于log4js封装,对接公司的日志中心
在nuxt.config.js中增加:
export default {
// ...
modules: [
"@vivo/nuxt-vivo-logger"
],
vivoLog: {
logPath:process.env.NODE_ENV === "dev"?"./logs":"/data/logs/",
logName:'aa.log'
}
}
4.5.2 使用
async asyncData({ $axios,$vivoLog }) {
try {
const resData = await $axios.$get('/api/aaa')
if (process.server) $vivoLog.info(resData)
} catch (e) {
if (process.server) $vivoLog.error(e)
}
},
4.5.3 结果
五、写在结尾
用户体验的提升是一个永久的话题,vivo官网商城前端团队一直致力于技术的不断创新,希望能通过技术的探索给用户带来更好的体验;以上是vivo官网商城前端团队在SSR技术方面实践的一些经验,分享出来希望能和大家一起学习、探讨。
作者:vivo 官网商城前端团队











