
作者:Sijie Guo
编辑:Irene
转自:StreamNative
Apache Flink 和 Apache Pulsar 的开源数据技术框架可以以不同的方式融合,来提供大规模弹性数据处理。4 月 2 日,我司 CEO 郭斯杰受邀在 Flink Forward San Francisco 2019 大会上发表演讲,介绍了 Flink 和 Pulsar 在批流应用程序的融合情况。这篇文章会简要介绍 Apache Pulsar 及其与其他消息系统的不同之处,并讲解如何融合 Pulsar 和 Flink 协同工作,为大规模弹性数据处理提供无缝的开发人员体验。
Apache Pulsar 简介
Apache Pulsar 是一个开源的分布式发布-订阅消息系统, 由 Apache 软件基金会管理,并于 2018 年 9 月成为 Apache 顶级开源项目。 Pulsar 是一种多租户、高性能解决方案,用于服务器到服务器消息传递,包括多个功能,例如,在一个 Pulsar 实例中对多个集群提供原生支持、集群间消息跨地域的无缝复制、发布和端到端的低延迟、超过一百万个主题的无缝扩展以及由 Apache BookKeeper 提供的持久消息存储保证消息传递。现在我们来讨论 Pulsar 和其他发布-订阅消息传递框架之间的主要区别:
区别一
虽然 Pulsar 提供了灵活的发布-订阅消息传递系统,但它也由持久的日志存储支持——因此需在一个框架下集成消息传递和存储功能。由于 Pulsar 采用了分层架构,它可以即时故障恢复、支持独立可扩展性和无需均衡的集群扩展。
Pulsar 的架构与其他发布-订阅系统类似,框架由主题组成,而主题是主要数据实体。如下图所示,生产者向主题发送数据,消费者从主题接收数据。
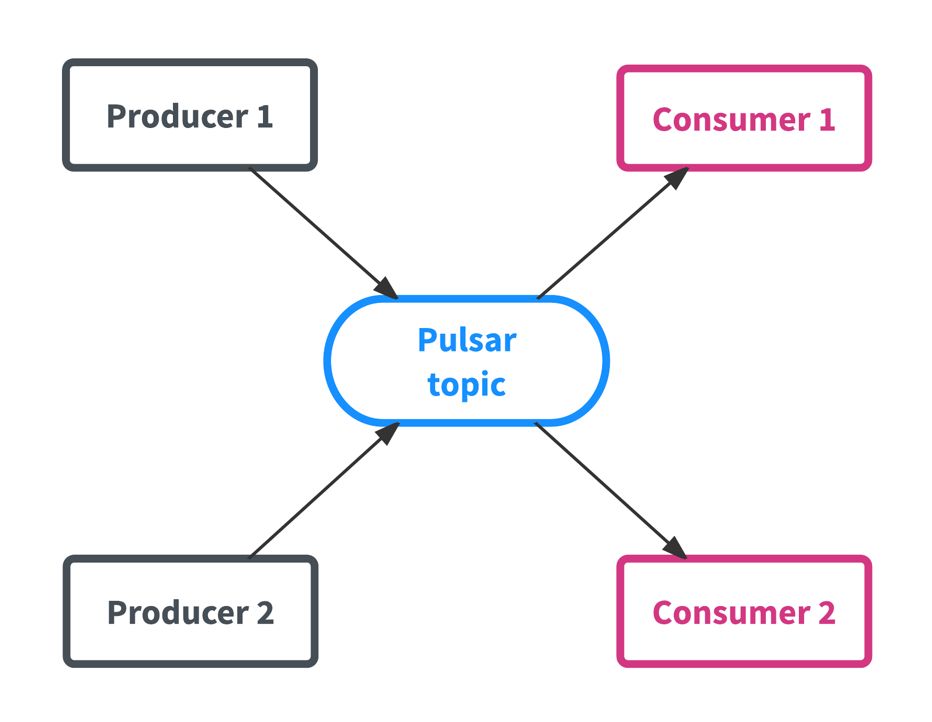
区别二
第二个区别是,Pulsar 的框架构建从一开始就考虑到了多租户。这意味着每个 Pulsar 主题都有一个分层的管理结构,使得资源分配、资源管理和团队协作变得高效而容易。由于 Pulsar 提供属性(租户)级、命名空间级和主题级的资源隔离,Pulsar 的多租户特性不仅能使数据平台管理人员轻松扩展新的团队,还能跨集群共享数据,简化团队协作。
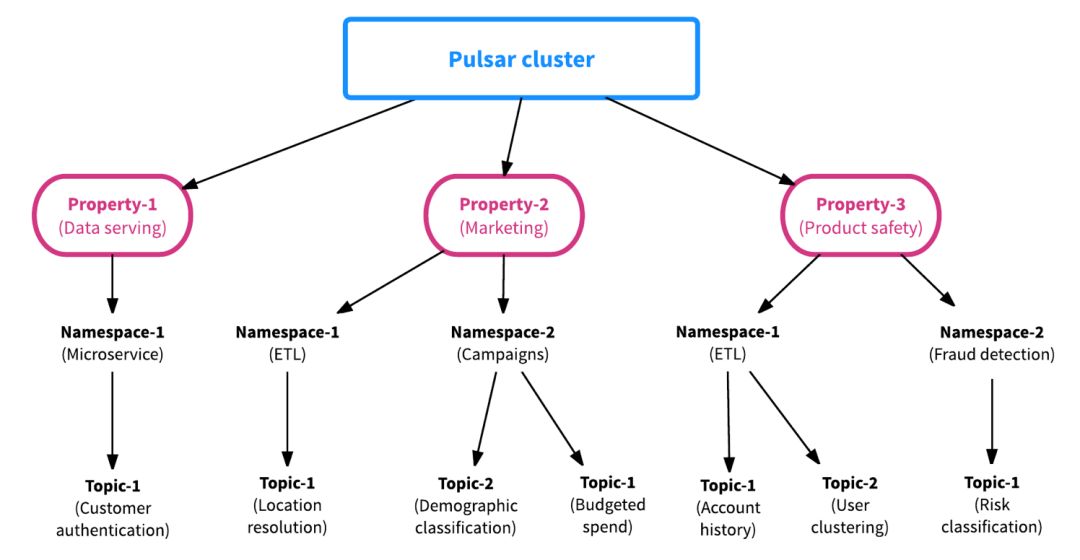
区别三
Pulsar 灵活的消息传递框架统一了流式和队列数据消费模型,并提供了更大的灵活性。如下图所示,Pulsar 保存主题中的数据,而多个团队可以根据其工作负载和数据消费模式独立地消费数据。
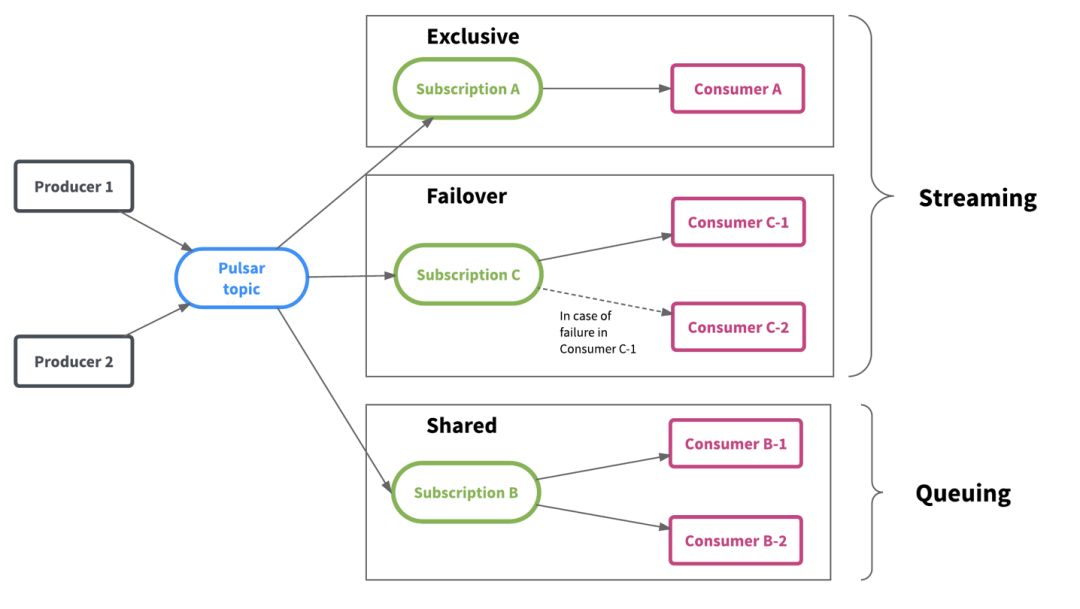
Pulsar 数据视图:****分片数据流
Apache Flink 是一个流式优先计算框架,它将批处理视为流处理的特殊情况。在对数据流的看法上,Flink 区分了有界和无界数据流之间的批处理和流处理,并假设对于批处理工作负载数据流是有限的,具有开始和结束。
在数据层上,Apache Pulsar 与 Apache Flink 的观点相似。该框架也使用流作为所有数据的统一视图,分层架构允许传统发布-订阅消息传递,用于流式工作负载和连续数据处理;并支持分片流(Segmented Streams)和有界数据流的使用,用于批处理和静态工作负载。
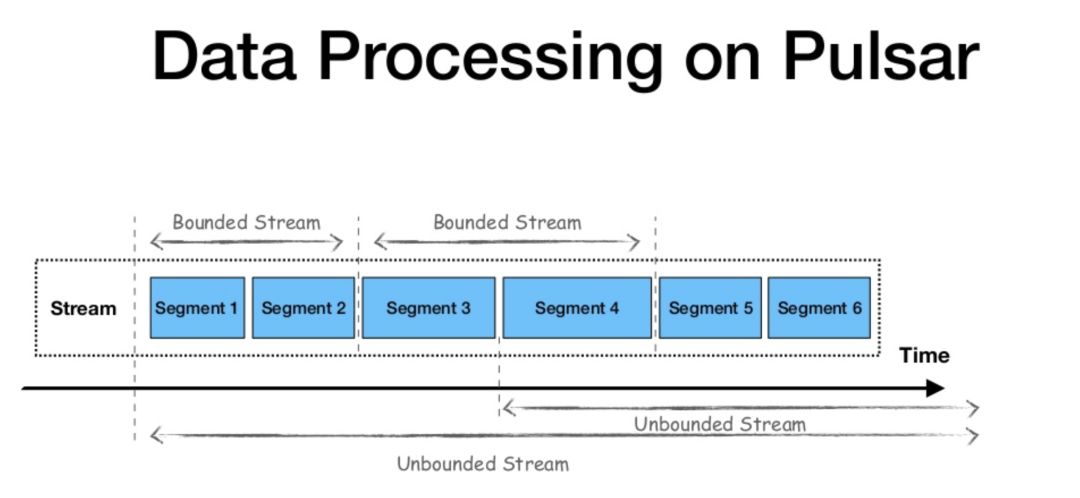
如下图所示,为了并行处理数据,生产者向主题发送数据后,Pulsar 根据数据流量对主题进行分区,再在每个分区中进行分片,并使用 Apache BookKeeper 进行分片存储。这一模式允许在同一个框架中集成传统的发布-订阅消息系统和分布式并行计算。
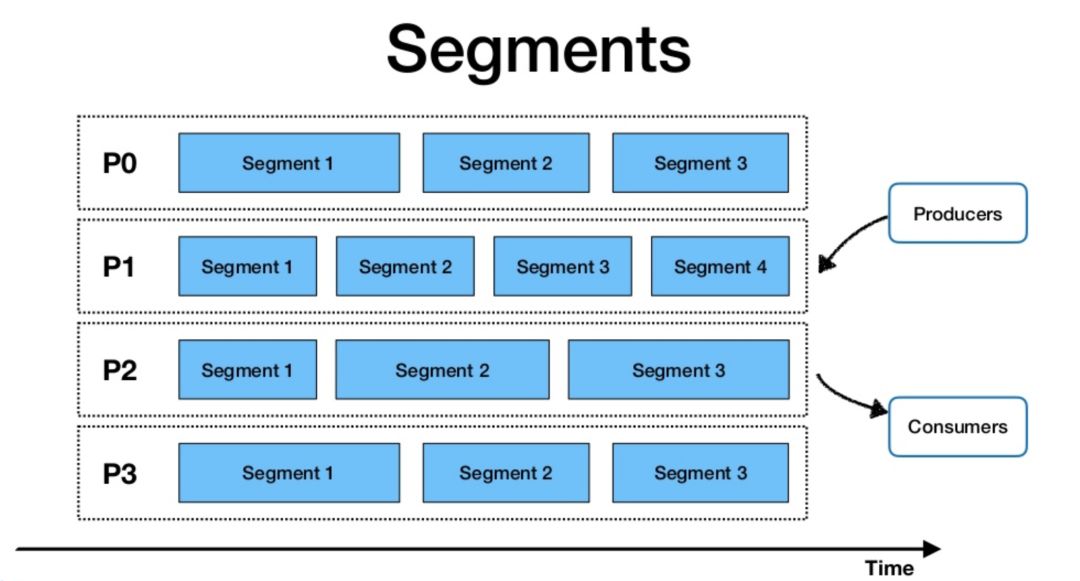
Flink + Pulsar 的融合
Apache Flink 和 Apache Pulsar 已经以多种方式融合。在以下内容中,我会介绍两个框架间未来一些可行的融合方式,并分享一些融合使用两个框架的示例。
未来融合方式:
Pulsar 能以不同的方式与 Apache Flink 融合,一些可行的融合包括,使用流式连接器(Streaming Connectors)支持流式工作负载,或使用批式源连接器(Batch Source Connectors)支持批式工作负载。Pulsar 还提供了对 Schema 的原生支持,可以与 Flink 集成并提供对数据的结构化访问,例如,使用 Flink SQL 在 Pulsar 中查询数据。另外,还能将 Pulsar 作为 Flink 的状态后端。由于 Pulsar 具有分层架构(Apache Bookkeeper 支持下的 Streams 和 Segmented Streams),因此可以将 Pulsar 作为存储层并存储 Flink 状态。
从架构的角度来看,我们可以想象两个框架之间的融合,使用 Apache Pulsar 作为统一的数据层视图,使用 Apache Flink 作为统一的计算、数据处理框架和 API。
现有融合方式
两个框架之间的融合正在进行中,开发人员已经可以通过多种方式融合使用 Pulsar 和 Flink。例如,在 Flink DataStream 应用程序中,Pulsar 可以作为流数据源和流接收器。开发人员能使 Flink 作业从 Pulsar 中获取数据,再进行计算并处理实时数据,最后将数据作为流接收器发送回 Pulsar 主题。示例如下:
PulsarSourceBuilder
.serviceUrl(serviceUrl)
.topic(inputTopic)
.subscriptionName(subscription);
SourceFunction
DataStream
DataStream
.flatMap((FlatMapFunction<String, WordWithCount>) (line, collector) -> {
for (String word : line.split("\\s")) {
collector.collect(new WordWithCount(word, 1));
}
})
.returns(WordWithCount.class)
.keyBy("word")
.timeWindow(Time.seconds(5))
.reduce((ReduceFunction
new WordWithCount(c1.word, c1.count + c2.count));
if (null != outputTopic) {
wc.addSink(new FlinkPulsarProducer<>(
serviceUrl,
outputTopic,
new AuthenticationDisabled(),
wordWithCount -> wordWithCount.toString().getBytes(UTF_8),
wordWithCount -> wordWithCount.word
)).setParallelism(parallelism);
} else {
// print the results with a single thread, rather than in parallel
wc.print().setParallelism(1);
}
另一个开发人员可利用的框架间的融合,已经包括将 Pulsar 用作 Flink 应用程序的流式源和流式表接收器,代码示例如下:
PulsarSourceBuilder
.serviceUrl(serviceUrl)
.topic(inputTopic)
.subscriptionName(subscription);
SourceFunction
DataStream
DataStream
.flatMap((FlatMapFunction<String, WordWithCount>) (line, collector) -> {
for (String word : line.split("\\s")) {
collector.collect(
new WordWithCount(word, 1)
);
}
})
.returns(WordWithCount.class)
.keyBy(ROUTING_KEY)
.timeWindow(Time.seconds(5))
.reduce((ReduceFunction
new WordWithCount(c1.word, c1.count + c2.count));
tableEnvironment.registerDataStream("wc",wc);
Table table = tableEnvironment.sqlQuery("select word, `count` from wc");
table.printSchema();
TableSink sink = null;
if (null != outputTopic) {
sink = new PulsarJsonTableSink(serviceUrl, outputTopic, new AuthenticationDisabled(), ROUTING_KEY);
} else {
// print the results with a csv file
sink = new CsvTableSink("./examples/file", "|");
}
table.writeToSink(sink);
最后,Flink 融合 Pulsar 作为批处理接收器,负责完成批处理工作负载。Flink 在静态数据集完成计算之后,批处理接收器将结果发送至 Pulsar。示例如下:
// create PulsarOutputFormat instance
final OutputFormat pulsarOutputFormat =
new PulsarOutputFormat(serviceUrl, topic, new AuthenticationDisabled(), wordWithCount -> wordWithCount.toString().getBytes());
// create DataSet
DataSet
// convert sentences to words
textDS.flatMap(new FlatMapFunction<String, WordWithCount>() {
@Override
public void flatMap(String value, Collector
String[] words = value.toLowerCase().split(" ");
for(String word: words) {
out.collect(new WordWithCount(word.replace(".", ""), 1));
}
}
})
// filter words which length is bigger than 4
.filter(wordWithCount -> wordWithCount.word.length() > 4)
// group the words
.groupBy(new KeySelector<WordWithCount, String>() {
@Override
public String getKey(WordWithCount wordWithCount) throws Exception {
return wordWithCount.word;
}
})
// sum the word counts
.reduce(new ReduceFunction
@Override
public WordWithCount reduce(WordWithCount wordWithCount1, WordWithCount wordWithCount2) throws Exception {
return new WordWithCount(wordWithCount1.word, wordWithCount1.count + wordWithCount2.count);
}
})
// write batch data to Pulsar
.output(pulsarOutputFormat);
总结
Pulsar 和 Flink 对应用程序在数据和计算级别如何处理数据的视图基本一致,将“批”作为“流”的特殊情况进行“流式优先”处理。通过 Pulsar 的 Segmented Streams 方法和 Flink 在一个框架下统一批处理和流处理工作负载的几个步骤,可以应用多种方法融合两种技术,提供大规模的弹性数据处理。欢迎订阅 Apache Flink 和 Apache Pulsar 邮件,及时了解领域最新发展,或在社区分享您的想法和建议。
更多 Pulsar 干货和动态分享,请关注微信公众号StreamNative,我们将在后续文章中推送更多优质内容。

本文分享自微信公众号 - 浪尖聊大数据(bigdatatip)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











