
Django对各种数据库提供了很好的支持,Django为这些数据库提供了统一的调用API,可以根据不同的业务需求选择不同的数据库。
- 模型、属性、表、字段间的关系
一个模型类在数据库中对应一张表,在模型类中定义的属性,对应该模型对照表中的一个字段。
- \*\*Object Relational Mapping(ORM)对象-关系-映射\*\* 作用:根据对象的类型生成表结构,将对象、列表的操作转换为sql语句,将sql语句查询到的结果转换为对象、列表,极大的减轻了开发人员的工作量,不需要面对因数据库的变更而修改代码。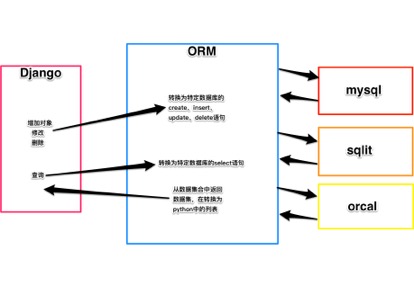
####
定义模型
django会为表增加自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后,则django不会再生成默认的主键列。
由于django的查询方式,不允许使用连续的下划线。
定义属性时,需要字段类型,字段类型被定义在\`\`\`django.db.models.fields\`\`\`目录下,为了方便使用,被导入到\`\`\`django.db.models\`\`\`中,定义模型时先导入\`\`\`from django.db import models\`\`\`,通过models.Field创建字段类型的对象,赋值给属性。注意:对于重要数据都做逻辑删除,不做物理删除,实现方法是定义isDelete属性,类型为BooleanField,默认值为False
####
字段类型
AutoField:一个根据实际ID自动增长的IntegerField,通常不指定如果不指定,一个主键字段将自动添加到模型中。CharField(max_length=字符长度):字符串,默认的表单样式是TextInput。TextField:大文本字段,一般超过4000使用,默认的表单控件是Textarea。IntegerField:整数DecimalField(max_digits=None, decimal_places=None):使用python的Decimal实例表示的十进制浮点数,DecimalField.max_digits(位数总数),DecimalField.decimal_places(小数点后的数字位数)。FloatField:用Python的float实例来表示的浮点数。BooleanField:true/false 字段,此字段的默认表单控制是CheckboxInput。NullBooleanField:支持null、true、false三种值。DateField([auto_now=False, auto_now_add=False]):使用Python的datetime.date实例表示的日期,DateField.auto_now,每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false,DateField.auto_now_add,当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false。
注意:auto\_now\_add, auto\_now, and default 这些设置是相互排斥的,他们之间的任何组合将会发生错误的结果
TimeField:使用Python的datetime.time实例表示的时间,参数同DateField。DateTimeField:使用Python的datetime.datetime实例表示的日期和时间,参数同DateField。FileField:一个上传文件的字段。ImageField:继承了FileField的所有属性和方法,但对上传的对象进行校验,确保它是个有效的image。
####
字段参数
说明:通过字段选项,可以实现对字段的约束,在字段对象时通过关键字参数指定。
null:如果为True,Django 将空值以NULL 存储到数据库中,默认值是 False。blanke:如果为True,则该字段允许为空白,默认值是 False。
注意:null是数据库范畴的概念,blank是表单验证证范畴的。
db_column:字段的名称,如果未指定,则使用属性的名称。db_index:若值为 True, 则在表中会为此字段创建索引。default:默认值。primary_key:若为 True, 则该字段会成为模型的主键字段。unique:如果为 True, 这个字段在表中必须有唯一值。upload_to='article':图片、文件字段的参数,表示文件上传到某个文件夹。
####
模型间关系
一对一关系 : OneToOneField
class Student(models.Model): name = models.CharField() info = OneToOneField(B) class StudentInfo(models.Model): tel = models.CharField() addr = models.CharField() stu = Student() meta = StudentInfo() stu.info # 正向查询-通过学生查询信息 meta.student # 反向查询,通过信息查询学生
一对多关系 : ManyToManyField
class Student(models.Model): name = models.CharField() grade = ForeignKey(Grade) class Grade(models.Model): gname = models.CharField() stu = Student() grade = Grade() stu.grade # 正向查询,通过学生查询班级名 grade.student_set # 反向查询,通过班级名查询学生
多对多关系 : ManyToManyField
class Student(models.Model): name = models.CharField() course = ManyToManyField(Course) class Curse(models.Model): cname = models.CharField() stu = Student() course = Course() stu.course_set # 正向 查询学生选修的课程 course.student_set # 反向 查询选修课程的学生名
####
模型元选项
在模型类中定义Meta类,用于设置元信息
class A(models.Model):
pass
class Meta:
db_table = 'a' # 定义数据表名,推荐使用小写字母,数据表名默认为项目名小写_类名小写
ordering = ['id'] # 对象的默认排序字段,获取对象的列表时使用,'id'-升序,‘-id’降序
####
模型成员
类属性
objects:是Manager类型的一个对象,作用是与数据库进行交互,当定义模型类是没有指定管理器,则Django为模型创建一个名为objects的管理器。
自定义管理器
class Students(models.Model):
# 自定义模型管理器
# 当自定义模型管理器,objects就不存在了
stuObj = models.Manager()
当为模型指定模型管理器,Django就不在为模型类生成objects模型管理器。
- 自定义管理器Manager类
模型管理器是Django的模型进行与数据库进行交互的接口,一个模型可以有多个模型管理器,作用是向管理器类中添加额外的方法,修改管理器返回的原始查询集(重写get_queryset()方法)。
class StudentsManager(models.Manager):
def get_queryset(self):
return super(StudentsManager,self).get_queryset().filter(isDelete=False) # 重写get_queryset()方法对查询集进行过滤
class Students(models.Model):
stuObj2 = StudentsManager()
- 创建对象的方法
(1).在模型类中增加一个类方法
class Students(models.Model):
#定义一个类方法创建对象
@classmethod
def createStudnet(cls, name, age, gender, contend, grade, lastT, createT, isD=False):
stu = cls(sname = name, sage = age, sgender = gender, scontend = contend, sgrade = grade, lastTime = lastT, createTime = createT, isDelete=isD)
return stu
# 调用
Students.createStudent()
(2). 在定义管理器中添加一个方法
class StudentsManager(models.Manager):
def get_queryset(self):
return super(StudentsManager,self).get_queryset().filter(isDelete=False)
def createStudnet(self, name, age, gender, contend, grade, lastT, createT, isD=False):
stu = self.model()
# print(type(grade))
stu.sname = name
stu.sage = age
stu.sgender = gender
stu.scontend = contend
stu.sgrade = grade
stu.lastTime = lastT
stu.createTime = createT
return stu
####
模型查询
查询集表示从数据库获取的对象集合,查询集可以有多个过滤器,过滤器就是一个函数,基于所给的参数限制查询集结果,创建查询集不会带来任何数据的访问,直到调用数据时,才会访问数据。
创建学生模型
class Student(models.Model):
s_name = models.CharField(max_length=10,unique=True) # 指定学生名唯一
s_age = models.IntegerField() # 学生姓名
s_gender = models.BooleanField(default=True) # 学生性别默认为True
isDelete = models.BooleanField(default=false) # 设置逻辑删除字段
grade = models.ForeignKey(Grade) # 关联班级
class Meta:
db_table = 'student' # 指定表名
ordering = ['id'] # 以id排序
def __str(self)__:
return self.s_name # 查询集的返回显示学生姓名
class StudentManager(models.Manager):
def get_queryset(self):
return super(StudentsManager,self).get_queryset().filter(isDelete=False) # 自定义模型管理器,重写父类get_queryset()方法,过滤查询集
创建班级模型
class Grade(models.Model):
g_name = models.CharField(max_length=10,unique=True) # 创建班级名指定唯一
class Meta:
db_table = 'grade'
ordering = ['id']
def __str(self)__:
return self.g_name
创建课程模型
class Course(models.Model):
c_name = models.CharField(max_length=10) # 课程名
start_date = models.DateField(auto_now_add) # 开课日期
end_date = models.DateField(auto_now_add) # 结束日期
stu = models.ManyToManyField(Student)
class Meta:
db_table = 'course'
ordering = ['start_date']
def __str(self)__:
return self.c_name
创建学生信息模型
class StudentInfo(models.Model):
phone = models.IntegerField() # 手机号
address = models.CharField(max_length=20) # 地址
stu = OneToOneField(Student)
class Meta:
db_table = 'studentinfo'
过滤器
Student.objects.all() # 返回查询集中的所有数据
Student.objects.filter(pk=3) # 返回符合条件的数据
Student.objects.filter(s_age=20).filter(s_gender=True) # 满足两种条件的查询方式一
Studen.objects.filter(s_age=20,s_gender=False) # 满足两种条件的查询方式二
Studen.objects.exclude(s_name='tom') # 过滤掉符合条件的数据,查询不满足条件的其他数据
Studen.objects.order_by('s_age') # 以年龄排序,升序
Studen.objects.order_by('-s_age') # 以年龄排序,降序
Studen.objects.values() # 将所有对象及属性返回
Studen.objects.values('s_name') # 返回所有对象的名字
返回单个数据
Studen.objects.get(pk=1) # 返回一个满足条件的对象,如果没有找到符合条件的对象,会引发"模型类.DoesNotExist"异常,如果找到多个对象,会引发"模型类.MultipleObjectsReturned"异常
Studen.objects.filter(s_gender=True).count() # 返回当前查询集中的对象个数
Studen.objects.filter(s_gender=True).first() # 返回查询集中的第一个对象
Studen.objects.filter(s_gender=True) # 返回查询集中的最后一个对象
Studen.objects.filter(s_name='tom').exists() # 判断查询集中是否有数据,如果有数据返回True
限制查询集
studentsList = Student.objects.all()[0:5] # 注意:下标不能是负数
查询集的缓存:在新建的查询集中,缓存首次为空,第一次对查询集求值,会发生数据缓存,django会将查询出来的数据做一个缓存,并返回查询结构,以后的查询直接使用查询集的缓存。
####
字段查询
比较运算符
Studen.objects.filter(s_name__contains='王') # 查询名字包含王的学生,大小写敏感
Studen.objects.filter(s_name__startswith='孙') # 查询名字以开头的学生,大小写敏感
Studen.objects.filter(s_name__endswith='雨') # 查询名字以结尾的学生,大小写敏感
以上四个在前面加上i,就表示不区分大小写iexact、icontains、istartswith、iendswith
StudenInfo.objects.filter(address isnull) # 查询地址是空的学生信息
StudenInfo.objects.filter(address isnotnull) # 查询地址不是空的学生信息
Studen.objects.filter(pk in (2,4,6)) # 查询pk在(2,4,6)的学生
Studen.objects.filter(s_age__gt=20) # 查询年龄大于20的学生
Studen.objects.filter(s_age__gte=20) # 查询年龄大于等于20的学生
Studen.objects.filter(s_age__lt=30) # 查询年龄小于30的学生
Studen.objects.filter(s_age__lte=30) # 查询年龄小于等于30的学生
Course.objects.filter(start_date__year=2016) # 查询开课课程在2016年的课程
Course.objects.filter(start_date__year=2016,start_date__month=10) # 查询开课课程在2016年10月的课程
# year-month-day-week_day-hour-minute-second
跨关联查询
Studen.objects.filter(course__c_name__contains='程序设计') # 查询课程中带有程序设计的课程被选择的学生
聚合函数
使用
aggregate()
函数返回聚合函数的值。使用哪个聚合函数就导入。from django.db.models import Max,Min,Sum,Avg,Count
maxAge = Student.objects.aggregate(Max('s_age'))
minAge = Studen.objects.aggregate(Min('s_age'))
sumAge = Studen.objects.aggregate(Sum('s_age'))
avgAge = Studen.objects.aggregate(Avg('s_age'))
countAge = Studen.objects.aggregate(Count('s_age'))
F对象
可以使用模型的A属性与B属性进行比较。
from django.db.models import F
Studen.objects.filter(pk__gte=F('s_age')) # 查询学生中主键大于年龄的学生
Studen.objects.filter(pk__gt=F('s_age')+20) # 查询学生中主键大于年龄加20的学生
Q对象
过滤器的方法中的关键字参数,条件为And模式
from django.db.models import Q对象
Studen.objects.filter(Q(pk__lt=5) | Q(s_age__gt=20)) # 查询主键小于5或年龄大于20的学生
Studen.objects.filter(~Q(pk__lt=5)) # 取反,查主键大于5的学生。










