
有一个应用程序充斥着技术债,严重的过时了,或者只是对用户服务不足,因此,我们需要了解我们的最佳选择是什么——是继续艰难地探索并逐步进行重构更有意义,还是把它全部摧毁并从头开始重写更有意义呢?这就是我们将在本文中探讨的基本难题。所以让我们开始吧……
但是没有那么快!在我们进一步研究之前,需要解决一个大家“避而不谈”的问题,即:对于任何需要改进的遗留应用程序,下一步要做什么并不是一个这样或那样就可以了的简单决定。我们通常会将我们的选项框定为重写或重构,但这些术语,正如我们将要看到的那样,实际上只是摆在我们面前的一系列选项的替代品。
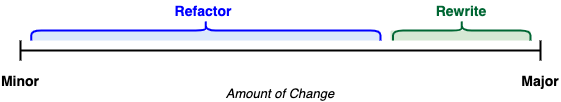
通过重构,在现代化遗留应用程序的场景中,通常意味着我们将会保持应用程序基本不变,但会进行一些微小的内部改进以解决特定的问题(如可维护性、可扩展性等)。另一方面,通过重写,则意味着我们打算“从头开始”,或者换句话说,进行重大的变更。
但这只会引出下一个问题!较小变更(Minor)和重大变更(Major)到底是什么意思?如果我们打算将前端框架从 AngularJS 升级为 React,但保留后端服务不变,这是重构还是重写呢?或者,如果我们想要将一个单体应用拆分成三个不同的微服务,但只是复制粘贴业务逻辑到新的版本控制存储库中,那这是重写、重构还是其他什么呢?我们真的在乎吗?给我们的努力贴上标签真的很重要吗?
是的,确实是。虽然我们的工作是构建可运行的软件,而不是对语义进行哲学思考,但我们使用的词汇确实会产生影响。当我们提议走重写或重构的道路时,业务和技术涉众应该能够准确地理解我们的意思,以及需要付出什么样的努力。换句话说,我们措辞的精确性将有助于我们更好地设定预期。此外,当我们穿过一些概念上的迷雾并找到更清晰的定义时,也会让我们对这个决定有一个更细致的看法,并能使我们脱离狭隘的重写或重构框架。
所以,就像任何一次长途旅行一样,在我们跳上车出发之前,让我们花点时间整理行李。我们不想出现在海滩上才发现自己忘了带泳衣。
功能改进
一个好的起点是定义重写和重构不是什么,它们是改进应用程序功能的策略。这种类型的工作,无论是修复缺陷,交付新特性,还是清理用户界面,我们都可以称之为增强。它是关于改进应用程序为用户所做的事情的,正如我们稍后将看到的那样,它是正常的开发状态。

但在某些情况下,功能增强的范围可能相当大。例如,企业可能想要确定某应用程序是为正确的用户群提供服务的,但所有的功能都需要彻底检查。这种情况也可能被称为重写,但是在这里我们要做一个区分。因为这种类型的工作需要构建所有新的功能,所以它与新建项目基本上没有区别。当需要定义新的功能需求时,从零开始开发一个独立的系统,并且不能继承原逻辑或代码,我们会将其视为新开发的应用程序,而不是重写。
重构是什么
向应用程序添加功能并不是本文的重点。我们的场景是:应用程序通常会执行预期的操作,但缺少如何执行的能力,换句话说,即缺少系统的非功能或质量属性。例如,用户可能对这些功能感到满意,但应用程序可能过于难以维护,或者可能频繁崩溃,或者在峰值负载下性能很差。当这些非功能属性缺失时,我们才会考虑重写或重构。
关于重构,我们经常使用这个术语来指代不同的工作范围。 Martin Fowler 在他的《重构》一书中是这样定义重构:
重构是一种用于重组现有代码主体,在不更改其外部行为的情况下更改其内部结构的规范技术。
从这种纯粹的意义上讲,重构主要是为了使代码更易于维护。这可能是分解冗长的或复杂的函数,修复不一致的命名,添加单元测试,或者重组类的层次结构、数据结构或模式。请注意,没有更改任何对用户可见的内容,但是修改了内部的代码结构,使其更容易为开发人员所使用,从而提高了我们的工作效率(和幸福感!)。
然而,在我们做重写或重构决策的场景中,这个定义过于严格。在我们的场景中,当我们谈论重构时,我们通常不会区分内部和外部,而是会区分功能和非功能。例如,我们可能会说,我们选择重构现有的代码库,以提高应用程序的可靠性或性能。从技术上讲,这些质量属性不是系统的内部属性(用户可以明显感知到它们,因为它们直接影响用户),它们只是非功能性的。这可能是一个过于学术的区别,但本着精确的精神,我认为有必要指出来。在本文中,我们将使用更广泛的重构定义:
重构是一种方法,通过这种方法对现有的代码主体进行增量重组,以提高系统的质量属性。
最后,需要注意的是重构是关于迭代变更的。它会对应用程序进行细微的调整,将其交付,然后冲洗并重复。在功能增强的基础上,重构可以使我们的用户满意,使我们的代码库保持健康,并能最大限度地减少技术债和功能缺陷。然而,如果被忽略,我们可能需要考虑更重的替代方案。
重写是什么
与重构一样,重写也有着相同的基本目标:改善应用程序的非功能性。区别在于更改了多少。简单地说,如果重构是管道胶带,那么重写就是一个大锤或一个反铲。它不是要对现有的功能进行渐进式的改进,而是要摧毁它,重新构建。对应于我们讨论过的其他类型的开发工作,我们可以这样可视化地展示重写:
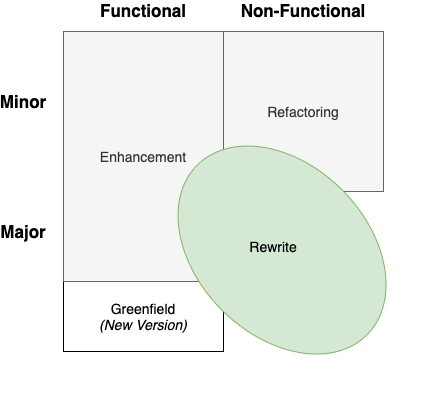
可以说,重写是一项涉及到对系统进行重大更改的工作,以便对其质量属性进行根本性的改进。但也有灰色区域。重写工作通常会扩散到其他象限。例如,一个应用程序可能会因为技术债而瘫痪,以至于几乎不可能再添加新特性。我们可能会选择重写然后建立一个新的基础来提高可维护性和可扩展性(质量属性),但是在重写的过程中,我们也可能会加入一些新的特性来满足业务需求。它基本上是重写的,但也进行了一些增强。
同样地,在重写和重构的边界上也存在一些模糊性。在一些“平移”(lift-and-shift)的情况下,系统被迁移到一个新的平台上,使得它在本质上成为了一个不同的应用程序,但其中的代码实现基本相同,即没有重构。这感觉像是重写了,但真的是这样吗?需要做多少更改才能被视为是重写呢?
再次,让我们看看是否可以增加一些精度。在本书中,我们使用以下定义:
重写就是重新构建存在于遗留应用程序中的相同功能,但使用不同的语言 / 框架,在新的代码库(不仅仅是分支)中维护,并作为一个全新的构件进行部署(可能部署到不同的平台上,如服务器、硬件、无服务器、客户端等)。
换句话说,我们要画一些明确的界限。例如,如果我们要重写一个重要的函数、类甚至模块,但是我们的工作是在代码库主线的分支上完成的,那么这就不是重写。同样地,如果我们重新实现了应用程序的一部分,但是系统本身仍作为同一构件(二进制文件、WAR 等)部署,这也不是重写。在我们的场景中,重写是很大的(BIG)。它们是涉及需要构建和部署全新应用程序的重大更改。是的,在实现这一目标的过程中可能会有一些渐进的步骤,我们稍后将会看到,但这是一种与重构根本不同的工作。
为了帮助自己梳理具体的情况,你可以把它画出来。即对于可能现代化或改进应用程序的不同途径,究竟要更改些什么?这里有一个例子:
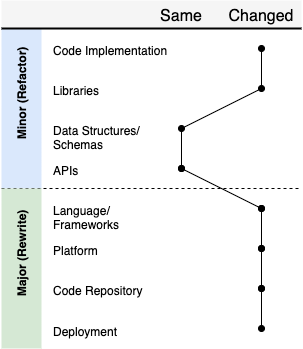
实际上,变更的性质可能与重写或重构的定义不一致,但这没有关系。例如,上图可能表示了这样一种情况:我们提议使用一组更现代化的技术来重新实现某个服务,但同时保持公开的 API 和底层持久层结构不变。这是一个较小变更和重大变更的混合体,所以应该如何确切地标记它可能仍然不清楚。然而,重要的是,我们已经了解了更深层次的细节,这将有助于我们更好地思考和证明这个决定。
现在我们的准备工作已经差不多完成了,但是在我们开始我们的旅程之前,让我们先把它们放在一起,看看这些不同类型的开发工作是如何适应给定应用程序生命周期的。换言之,让我们探究一下起源故事,以便重写。
重写的起源故事
这一切都是从新建开发阶段开始的,在这个阶段我们有了一个想法,并开始从中构建一个功能强大的应用程序。经过数周或数月的不懈努力,某些产品最终被投放到“市场”(可能是实际的付费客户,或只是一组内部业务用户,等等)。如果该应用程序很受欢迎,它将会在一段时间内处于增强的平衡阶段,在此阶段会添加新功能并修复缺陷。每个人都很开心。但最终,技术债会累积起来,我们开始看到努力的回报在递减,虽然在过去一周的开发足以添加一个全新的功能,但现在一周却不足以改变一个按钮的颜色。
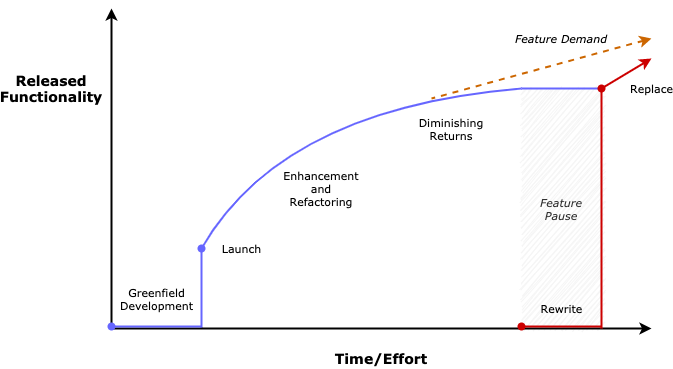
在这一点上,我们可能会质疑是否值得投入更多的时间和金钱。此外,自从应用程序首次发布以来,可能已经出现了一些令人兴奋的新技术,我们可能会对如何利用这些技术来使我们的应用程序更具弹性、更易于使用、更具性能等抱有一些宏伟的设想,因此我们开始制定重写计划。其想法是在短时间内冻结现有系统的开发,然后将资源转移到替换系统上。我们将首先构建基础(使用更现代化的模式、工具、语言等等),然后将现有的功能迁移到该基础中。用户只需要安然度过“暂停”(即不需要任何新的更新),但当重写系统就位时,工作效率就会是之前的两倍(或更多!)。
虽然这个计划看起来很直接,但它掩盖了一些关键的风险:技术、组织和心理因素,所有这些因素都会导致重写阶段是极不稳定的。随着这一阶段的拖延,我们成功替换的机会会越来越渺茫。在接下来的文章中,我们将探讨一些隐藏在重写工作中的危险,以及为什么我们总是不顾这些危险勇往直前的原因。











