
原文出处:https://bohutang.me/2020/07/25/clickhouse-and-friends-parser/
现实生活中的物品一旦被标记为“纯手工打造”,给人的第一感觉就是“上乘之品”,一个字“贵”,比如北京老布鞋。
但是在计算机世界里,如果有人告诉你 ClickHouse 的 SQL 解析器是纯手工打造的,是不是很惊讶!这个问题引起了不少网友的关注,所以本篇聊聊 ClickHouse 的纯手工解析器,看看它们的底层工作机制及优缺点。
枯燥先从一个 SQL 开始:
EXPLAIN SELECT a,b FROM t1
token
首先对 SQL 里的字符逐个做判断,然后根据其关联性做 token 分割:
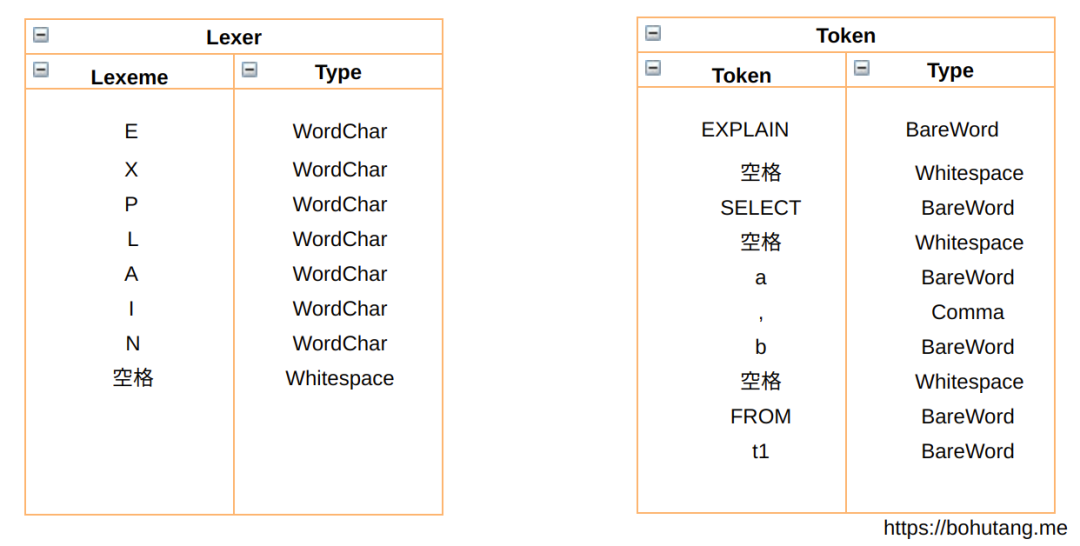
比如连续的 WordChar,那它就是 BareWord,解析函数在 Lexer::nextTokenImpl(),解析调用栈:
DB::Lexer::nextTokenImpl() Lexer.cpp:63DB::Lexer::nextToken() Lexer.cpp:52DB::Tokens::operator[](unsigned long) TokenIterator.h:36DB::TokenIterator::get() TokenIterator.h:62DB::TokenIterator::operator->() TokenIterator.h:64DB::tryParseQuery(DB::IParser&, char const*&, char const*, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> >&, bool, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, bool, unsigned long, unsigned long) parseQuery.cpp:224DB::parseQueryAndMovePosition(DB::IParser&, char const*&, char const*, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, bool, unsigned long, unsigned long) parseQuery.cpp:314DB::parseQuery(DB::IParser&, char const*, char const*, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, unsigned long, unsigned long) parseQuery.cpp:332DB::executeQueryImpl(const char *, const char *, DB::Context &, bool, DB::QueryProcessingStage::Enum, bool, DB::ReadBuffer *) executeQuery.cpp:272DB::executeQuery(DB::ReadBuffer&, DB::WriteBuffer&, bool, DB::Context&, std::__1::function<void (std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&)>) executeQuery.cpp:731DB::MySQLHandler::comQuery(DB::ReadBuffer&) MySQLHandler.cpp:313DB::MySQLHandler::run() MySQLHandler.cpp:150
ast
token 是最基础的元组,他们之间没有任何关联,只是一堆生冷的词组与符号,所以我们还需对其进行语法解析,让这些 token 之间建立一定的关系,达到一个可描述的活力。
ClickHouse 在解每一个 token 的时候,会根据当前的 token 进行状态空间进行预判(parse 返回 true 则进入子状态空间继续),然后决定状态跳转,比如:
EXPLAIN -- TokenType::BareWord
逻辑首先会进入Parsers/ParserQuery.cpp 的 ParserQuery::parseImpl 方法:
bool res = query_with_output_p.parse(pos, node, expected) || insert_p.parse(pos, node, expected) || use_p.parse(pos, node, expected) || set_role_p.parse(pos, node, expected) || set_p.parse(pos, node, expected) || system_p.parse(pos, node, expected) || create_user_p.parse(pos, node, expected) || create_role_p.parse(pos, node, expected) || create_quota_p.parse(pos, node, expected) || create_row_policy_p.parse(pos, node, expected) || create_settings_profile_p.parse(pos, node, expected) || drop_access_entity_p.parse(pos, node, expected) || grant_p.parse(pos, node, expected);
这里会对所有 query 类型进行 parse 方法的调用,直到有分支返回 true。
我们来看第一层 query_with_output_p.parse Parsers/ParserQueryWithOutput.cpp:
bool parsed = explain_p.parse(pos, query, expected) || select_p.parse(pos, query, expected) || show_create_access_entity_p.parse(pos, query, expected) || show_tables_p.parse(pos, query, expected) || table_p.parse(pos, query, expected) || describe_table_p.parse(pos, query, expected) || show_processlist_p.parse(pos, query, expected) || create_p.parse(pos, query, expected) || alter_p.parse(pos, query, expected) || rename_p.parse(pos, query, expected) || drop_p.parse(pos, query, expected) || check_p.parse(pos, query, expected) || kill_query_p.parse(pos, query, expected) || optimize_p.parse(pos, query, expected) || watch_p.parse(pos, query, expected) || show_access_p.parse(pos, query, expected) || show_access_entities_p.parse(pos, query, expected) || show_grants_p.parse(pos, query, expected) || show_privileges_p.parse(pos, query, expected
跳进第二层 explain_p.parse ParserExplainQuery::parseImpl状态空间:
bool ParserExplainQuery::parseImpl(Pos & pos, ASTPtr & node, Expected & expected){ ASTExplainQuery::ExplainKind kind; bool old_syntax = false; ParserKeyword s_ast("AST"); ParserKeyword s_analyze("ANALYZE"); ParserKeyword s_explain("EXPLAIN"); ParserKeyword s_syntax("SYNTAX"); ParserKeyword s_pipeline("PIPELINE"); ParserKeyword s_plan("PLAN"); ... ... else if (s_explain.ignore(pos, expected)) { ... ... } ... ... ParserSelectWithUnionQuery select_p; ASTPtr query; if (!select_p.parse(pos, query, expected)) return false; ... ...
s_explain.ignore 方法会进行一个 keyword 解析,解析出 ast node:
EXPLAIN -- keyword
跃进第三层 select_p.parse ParserSelectWithUnionQuery::parseImpl状态空间:
bool ParserSelectWithUnionQuery::parseImpl(Pos & pos, ASTPtr & node, Expected & expected){ ASTPtr list_node; ParserList parser(std::make_unique<ParserUnionQueryElement>(), std::make_unique<ParserKeyword>("UNION ALL"), false); if (!parser.parse(pos, list_node, expected)) return false;...
parser.parse 里又调用第四层 ParserSelectQuery::parseImpl 状态空间:
bool ParserSelectQuery::parseImpl(Pos & pos, ASTPtr & node, Expected & expected){ auto select_query = std::make_shared<ASTSelectQuery>(); node = select_query; ParserKeyword s_select("SELECT"); ParserKeyword s_distinct("DISTINCT"); ParserKeyword s_from("FROM"); ParserKeyword s_prewhere("PREWHERE"); ParserKeyword s_where("WHERE"); ParserKeyword s_group_by("GROUP BY"); ParserKeyword s_with("WITH"); ParserKeyword s_totals("TOTALS"); ParserKeyword s_having("HAVING"); ParserKeyword s_order_by("ORDER BY"); ParserKeyword s_limit("LIMIT"); ParserKeyword s_settings("SETTINGS"); ParserKeyword s_by("BY"); ParserKeyword s_rollup("ROLLUP"); ParserKeyword s_cube("CUBE"); ParserKeyword s_top("TOP"); ParserKeyword s_with_ties("WITH TIES"); ParserKeyword s_offset("OFFSET"); ParserNotEmptyExpressionList exp_list(false); ParserNotEmptyExpressionList exp_list_for_with_clause(false); ParserNotEmptyExpressionList exp_list_for_select_clause(true); ... if (!exp_list_for_select_clause.parse(pos, select_expression_list, expected)) return false;
第五层 exp_list_for_select_clause.parse ParserExpressionList::parseImpl状态空间继续:
bool ParserExpressionList::parseImpl(Pos & pos, ASTPtr & node, Expected & expected){ return ParserList( std::make_unique<ParserExpressionWithOptionalAlias>(allow_alias_without_as_keyword), std::make_unique<ParserToken>(TokenType::Comma)) .parse(pos, node, expected);}
... ... 写不下去个鸟!
可以发现,ast parser 的时候,预先构造好状态空间,比如 select 的状态空间:
expression list
from tables
where
group by
with ...
order by
limit
在一个状态空间內,还可以根据 parse 返回的 bool 判断是否继续进入子状态空间,一直递归解析出整个 ast。
总结
手工 parser 的好处是代码清晰简洁,每个细节可防可控,以及友好的错误处理,改动起来不会一发动全身。缺点是手工成本太高,需要大量的测试来保证其正确性,还需要一些fuzz来保证可靠性。好在ClickHouse 已经实现的比较全面,即使有新的需求,在现有基础上修修补补即可。
文内链接
延伸阅读
全文完。
Enjoy ClickHouse :)
叶老师的「MySQL核心优化」大课已升级到MySQL 8.0,扫码开启MySQL 8.0修行之旅吧

本文分享自微信公众号 - 老叶茶馆(iMySQL_WX)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。













