
Batch Norm可谓深度学习中非常重要的技术,不仅可以使训练更深的网络变容易,加速收敛,还有一定正则化的效果,可以防止模型过拟合。在很多基于CNN的分类任务中,被大量使用。
但我最近在图像超分辨率和图像生成方面做了一些实践,发现在这类任务中,Batch Norm的表现并不好,加入了Batch Norm,反而使得训练速度缓慢,不稳定,甚至最后发散。
以下是我对这一现象的个人看法,并不严格,还需继续检验。
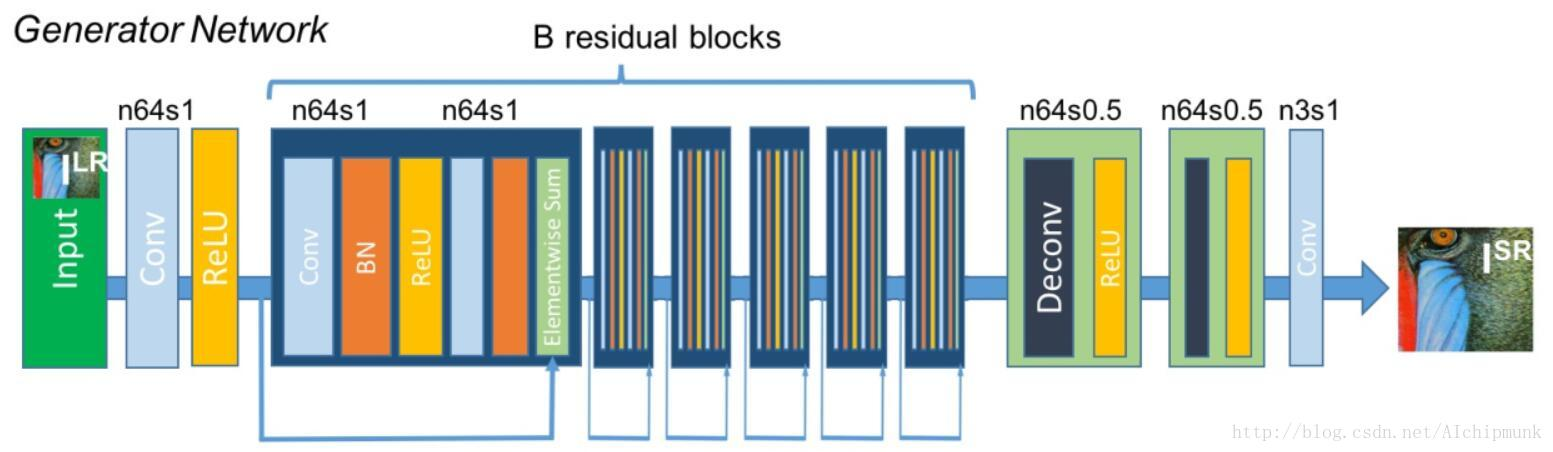
首先,以图像超分辨率来说,网络输出的图像在色彩、对比度、亮度上要求和输入一致,改变的仅仅是分辨率和一些细节,而Batch Norm,对图像来说类似于一种对比度的拉伸,任何图像经过Batch Norm后,其色彩的分布都会被归一化,也就是说,它破坏了图像原本的对比度信息,所以Batch Norm的加入反而影响了网络输出的质量。虽然Batch Norm中的scale和shift参数可以抵消归一化的效果,但这样就增加了训练的难度和时间,还不如直接不用。不过有一类网络结构可以用,那就是残差网络(Residual Net),但也仅仅是在residual block当中使用,比如SRResNet,就是一个用于图像超分辨率的残差网络。为什么这类网络可以使用Batch Norm呢?我个人理解是,因为图像的对比度信息可以通过skip connection直接传递,所以也就不必担心Batch Norm的破坏了。
---------------------
基于这种想法,也可以从另外一种角度解释Batch Norm为何在图像分类任务上如此有效。图像分类不需要保留图像的对比度信息,利用图像的结构信息就可以完成分类,所以,将图像都通过Batch Norm进行归一化,反而降低了训练难度,甚至一些不明显的结构,在Batch Norm后也会被凸显出来(对比度被拉开了)。
而对于照片风格转移,为何可以用Batch Norm呢?原因在于,风格化后的图像,其色彩、对比度、亮度均和原图像无关,而只与风格图像有关,原图像只有结构信息被表现到了最后生成的图像中。因此,在照片风格转移的网络中使用Batch Norm或者Instance Norm也就不奇怪了,而且,Instance Norm是比Batch Norm更直接的对单幅图像进行的归一化操作,连scale和shift都没有。
说得更广泛一些,Batch Norm会忽略图像像素(或者特征)之间的绝对差异(因为均值归零,方差归一),而只考虑相对差异,所以在不需要绝对差异的任务中(比如分类),有锦上添花的效果。而对于图像超分辨率这种需要利用绝对差异的任务,Batch Norm只会添乱。
原文:https://blog.csdn.net/AIchipmunk/article/details/54234646











