
Docker安装elasticsearch
启动注意2点,1是内存,2是线程数(此处进行简单安装,后面会详细补充es文档)
1 [root@topcheer ~]# docker images
2 REPOSITORY TAG IMAGE ID CREATED SIZE
3 elasticsearch latest 874179f19603 12 days ago 771 MB
4 springbootdemo4docker latest cd13bc7f56a0 2 weeks ago 678 MB
5 docker.io/tomcat latest ee48881b3e82 4 weeks ago 506 MB
6 docker.io/rabbitmq latest a00bc560660a 4 weeks ago 147 MB
7 docker.io/centos latest 67fa590cfc1c 7 weeks ago 202 MB
8 docker.io/redis latest f7302e4ab3a8 8 weeks ago 98.2 MB
9 docker.io/rabbitmq 3.7.16-management 3f92e6354d11 2 months ago 177 MB
10 docker.io/elasticsearch 6.8.0 d0b291d7093b 4 months ago 895 MB
11 docker.io/hello-world latest fce289e99eb9 9 months ago 1.84 kB
12 docker.io/java 8 d23bdf5b1b1b 2 years ago 643 MB
13 [root@topcheer ~]# docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 --name myES d0b291d7093b
14 5c4e5ffac1630f57260f739d200050535daf3ab10b1256441400a04fef70434b
15 [root@topcheer ~]# docker ps -l
16 CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
17 5c4e5ffac163 d0b291d7093b "/usr/local/bin/do..." 6 seconds ago Up 5 seconds 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp myES
18 [root@topcheer ~]# docker ps -l
19 CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
20 5c4e5ffac163 d0b291d7093b "/usr/local/bin/do..." About a minute ago Exited (78) 34 seconds ago myES
21 [root@topcheer ~]# docker logs -tf --tail 200 5c4e5ffac163
22 2019-10-11T15:33:21.335717000Z OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
发现ES容器停止了
1 2019-10-11T15:34:04.379276000Z [2019-10-11T15:34:04,372][INFO ][o.e.t.TransportService ] [om43m7F] publish_address {172.17.0.4:9300}, bound_addresses {[::]:9300}
2 2019-10-11T15:34:04.432432000Z [2019-10-11T15:34:04,393][INFO ][o.e.b.BootstrapChecks ] [om43m7F] bound or publishing to a non-loopback address, enforcing bootstrap checks
3 2019-10-11T15:34:04.441501000Z ERROR: [1] bootstrap checks failed
4 2019-10-11T15:34:04.441844000Z [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
5 2019-10-11T15:34:04.497725000Z [2019-10-11T15:34:04,454][INFO ][o.e.n.Node ] [om43m7F] stopping ...
6 2019-10-11T15:34:04.559075000Z [2019-10-11T15:34:04,557][INFO ][o.e.n.Node ] [om43m7F] stopped
7 2019-10-11T15:34:04.559461000Z [2019-10-11T15:34:04,557][INFO ][o.e.n.Node ] [om43m7F] closing ...
8 2019-10-11T15:34:04.580693000Z [2019-10-11T15:34:04,577][INFO ][o.e.n.Node ] [om43m7F] closed
9 2019-10-11T15:34:04.584525000Z [2019-10-11T15:34:04,581][INFO ][o.e.x.m.p.NativeController] [om43m7F] Native controller process has stopped - no new native processes can be started
解决:
在宿主机执行:
sysctl -w vm.max_map_count=262144
原因:
vm.max_map_count参数,是允许一个进程在VMAs拥有最大数量(VMA:虚拟内存地址, 一个连续的虚拟地址空间),当进程占用内存超过时, 直接OOM。
elasticsearch占用内存较高。官方要求max_map_count需要配置到最小262144。
重新启动:
http://192.168.180.113:9200/_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1570808429 15:40:29 docker-cluster green 1 1 0 0 0 0 0 0 - 100.0%
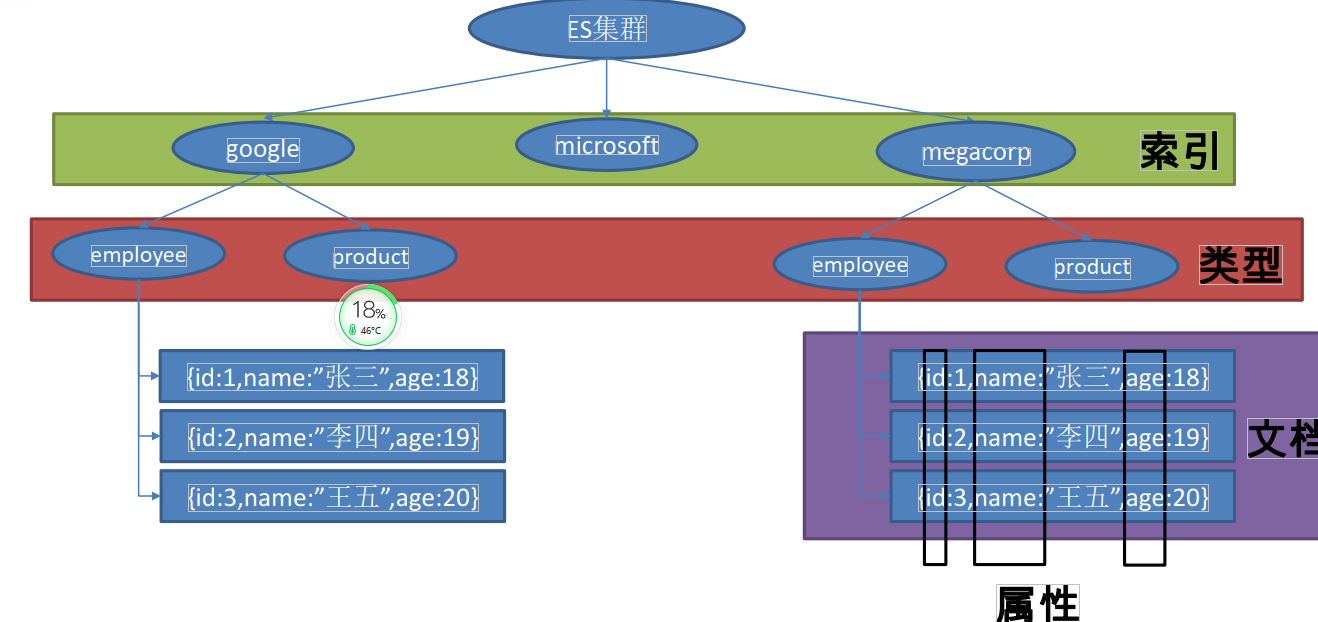
Springboot整合
pom.xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
配置文件
1 spring
2 data:
3 elasticsearch:
4 cluster-nodes: 192.168.180.113:9300
5 cluster-name: docker-cluster
启动类(采用第二种)
1 /**
2 * SpringBoot默认支持两种技术来和ES交互;
3 * 1、Jest(默认不生效)
4 * 需要导入jest的工具包(io.searchbox.client.JestClient)
5 * 2、SpringData ElasticSearch【ES版本有可能不合适】
6 * 版本适配说明:https://github.com/spring-projects/spring-data-elasticsearch
7 * 如果版本不适配:2.4.6
8 * 1)、升级SpringBoot版本
9 * 2)、安装对应版本的ES
10 *
11 * 1)、Client 节点信息clusterNodes;clusterName
12 * 2)、ElasticsearchTemplate 操作es
13 * 3)、编写一个 ElasticsearchRepository 的子接口来操作ES;
14 * 两种用法:https://github.com/spring-projects/spring-data-elasticsearch
15 * 1)、编写一个 ElasticsearchRepository
16 */
17 @SpringBootApplication
18 public class Springboot03ElasticApplication {
19
20 public static void main(String[] args) {
21 SpringApplication.run(Springboot03ElasticApplication.class, args);
22 }
23 }
发现启动项目报错:
nested exception is java.lang.IllegalStateException: availableProcessors is already set to [4], rejecting [4]
我网上查询了一下,有人是是因为整合了Redis的原因。但是我把Redis相关的配置去掉后,问题还是没有解决,最后有人说是因为netty冲突的问题。 也有人给出了解决方式就是在项目初始化钱设置一下一个属性。在初始化之前加上System.setProperty("es.set.netty.runtime.available.processors", "false");
1 @Configuration
2 public class ElasticSearchConfig {
3 @PostConstruct
4 void init() {
5 System.setProperty("es.set.netty.runtime.available.processors", "false");
6 }
7 }
Bo类
1 @Document(indexName = "topcheer",type = "book" )
2 @Slf4j
3 @Data
4 @Builder
5 public class Book implements Serializable {
6
7 private Integer id;
8 private String name;
9 private String author;
10
11 public Book(String name, String author) {
12 this.name = name;
13 this.author = author;
14 }
15
16 public Book(Integer id, String name, String author) {
17 this.id = id;
18 this.name = name;
19 this.author = author;
20 }
21
22 public Book() {
23 }
24 }
Repository类
1 public interface BookRepository extends ElasticsearchRepository<Book,Integer> {
2
3 //参照
4 // https://docs.spring.io/spring-data/elasticsearch/docs/3.0.6.RELEASE/reference/html/
5 public List<Book> findByNameLike(String name);
6
7 }
测试类:
1 @Autowired
2 BookRepository bookRepository;
3
4 @Test
5 public void test02() {
6 Book book = new Book();
7 book.setId(1);
8 book.setName("西游记");
9 book.setAuthor("吴承恩");
10 bookRepository.index(book);
11
12
13 for (Book book1 : bookRepository.findByNameLike("游")) {
14 System.out.println(book1);
15 };
16
17 }
结果:
1 2019-10-12 00:27:03.827 INFO --- [ main] Oss6ApplicationTests : Started Oss6ApplicationTests in 17.532 seconds (JVM running for 19.428)
2 2019-10-12 00:27:03.829 DEBUG --- [ main] ls.restart.Restarter : Creating new Restarter for thread Thread[main,5,main]
3 Book(id=1, name=西游记, author=吴承恩)
4 2019-10-12 00:27:04.851 DEBUG --- [ Thread-3] ebApplicationContext : Closing org.springframework.web.context.support.GenericWebApplicationContext@20f5281c, started on Sat Oct 12 00:26:47 CST 2019
5 2019-10-12 00:27:04.859 INFO --- [ Thread-3] ageListenerContainer : Waiting for workers to finish.
6 http://192.168.180.113:9200/topcheer/book/_search
7 {"took":7,"timed_out":false,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0},"hits":{"total":1,"max_score":1.0,"hits":[{"_index":"topcheer","_type":"book","_id":"1","_score":1.0,"_source":{"id":1,"name":"西游记","author":"吴承恩"}}]}}











