

从微服务框架到微服务生态,这是微服务发展的必然趋势,也是Dubbo社区满足开发者更高效的构建微服务体系期望的使命和担当。
近期,Apache Dubbo PPMC 望陶(社区昵称:ralf0131)做了主题为《首次直播揭秘 Apache Dubbo Ecosystem:从微服务框架到微服务生态》的直播分享。本文整理自此次分享,通过该内容,您将了解到Apache Dubbo Ecosystem的:
- 产生背景
- 生态定位和组件选择原则
- 体系总览和层次结构
- 和Spring Cloud之间的联系
- 直播问答精选
产生背景
微服务的流行,使得越来越多的用户选择从单体应用向分布式应用进行转型。在这个过程中,有许多企业选择了Dubbo作为分布式应用开发的基础组件。但是随着微服务化的逐渐深入,我们也发现,Dubbo目前提供的能力逐渐的无法满足开发者构建完整微服务的需求。开发者缺少一套完整的围绕Dubbo的微服务解决方案,例如API gateway、熔断限流、分布式监控和分布式事务等方面。开发者需要自研,或者调研各类开源的框架。这耗费了大量的时间和精力,且在整合的过程中,各类兼容和适配问题也影响到微服务的落地。
因此,我们决定围绕Dubbo打造一整套微服务的解决方案,涵盖微服务开发过程中的各方面。这里面的项目都是会经过Dubbo社区共同评估,和Dubbo高度集成,且在生产中得到过验证的项目(这里的项目不仅仅是阿里巴巴开源的),我们把这个生态称之为Apache Dubbo Ecosystem。希望通过这个生态帮助用户降低微服务实施的难度,加快业务创新进程。
Dubbo作为一款高性能RPC框架,通过良好的扩展机制,已经形成了丰富的核心RPC生态。
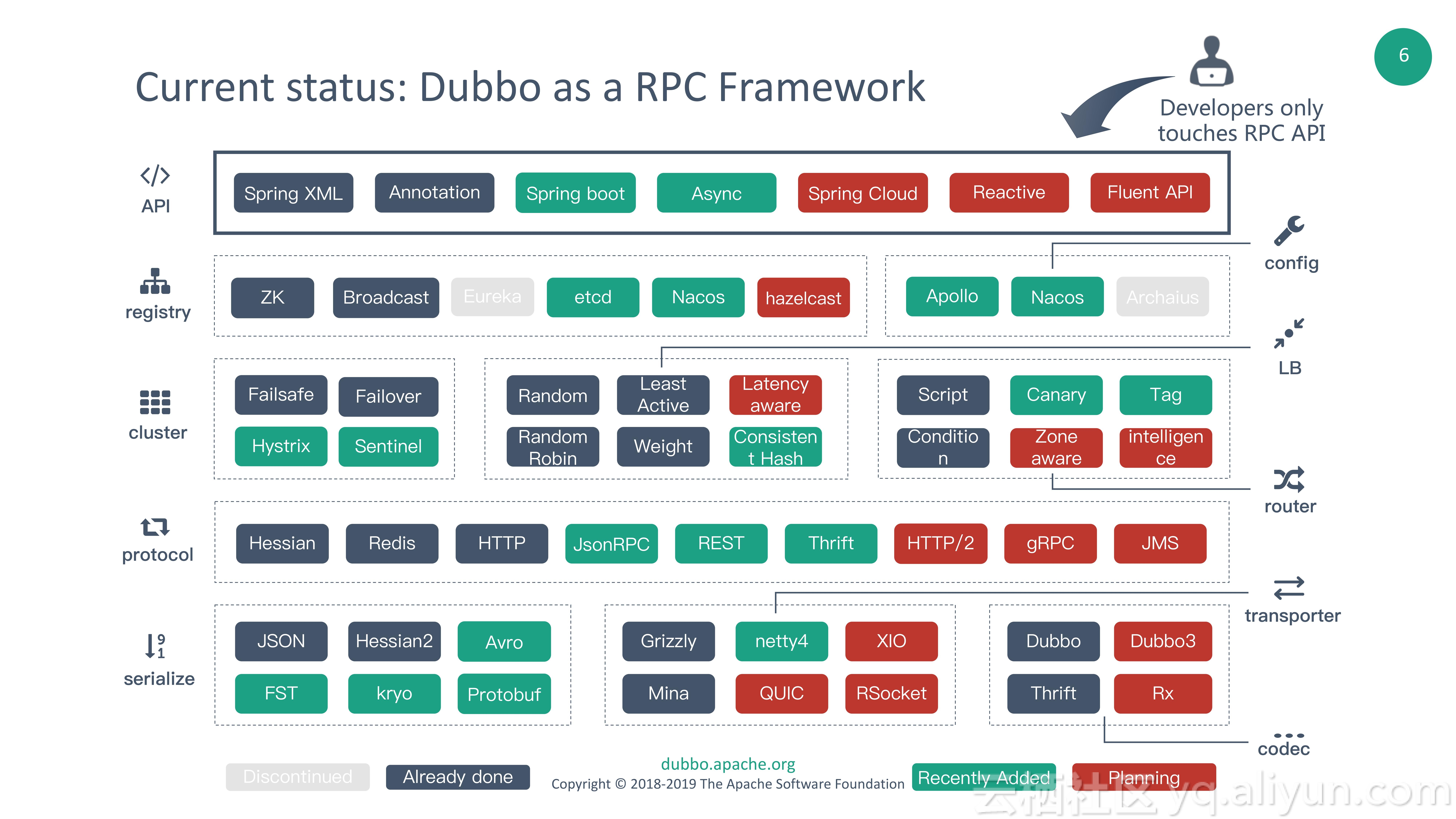
从上图中可以看到,图中黑色部分为Dubbo重启之前的RPC生态,绿色代表重启维护以来新增的生态,红色是未来计划添加的模块。这里面主要包括:
- 编程模型支持Spring-boot方式
- 服务注册中心发现支持Nacos,etcd
- 配置中心支持Apollo,Nacos
- 系统高可用支持Sentinel,Hystrix
- 负载均衡支持一致性Hash
- 路由规则支持标签路由
- 协议层支持REST, JsonRPC, Avro, Thrift
- 序列化层支持fst, kyro
- 传输层支持Netty4
但这里面有一些问题,开发者只接触到API,以及服务注册和配置这一层,接触不到大部分底层生态的组件,因此无法直接享受到这些底层组件的技术能力。
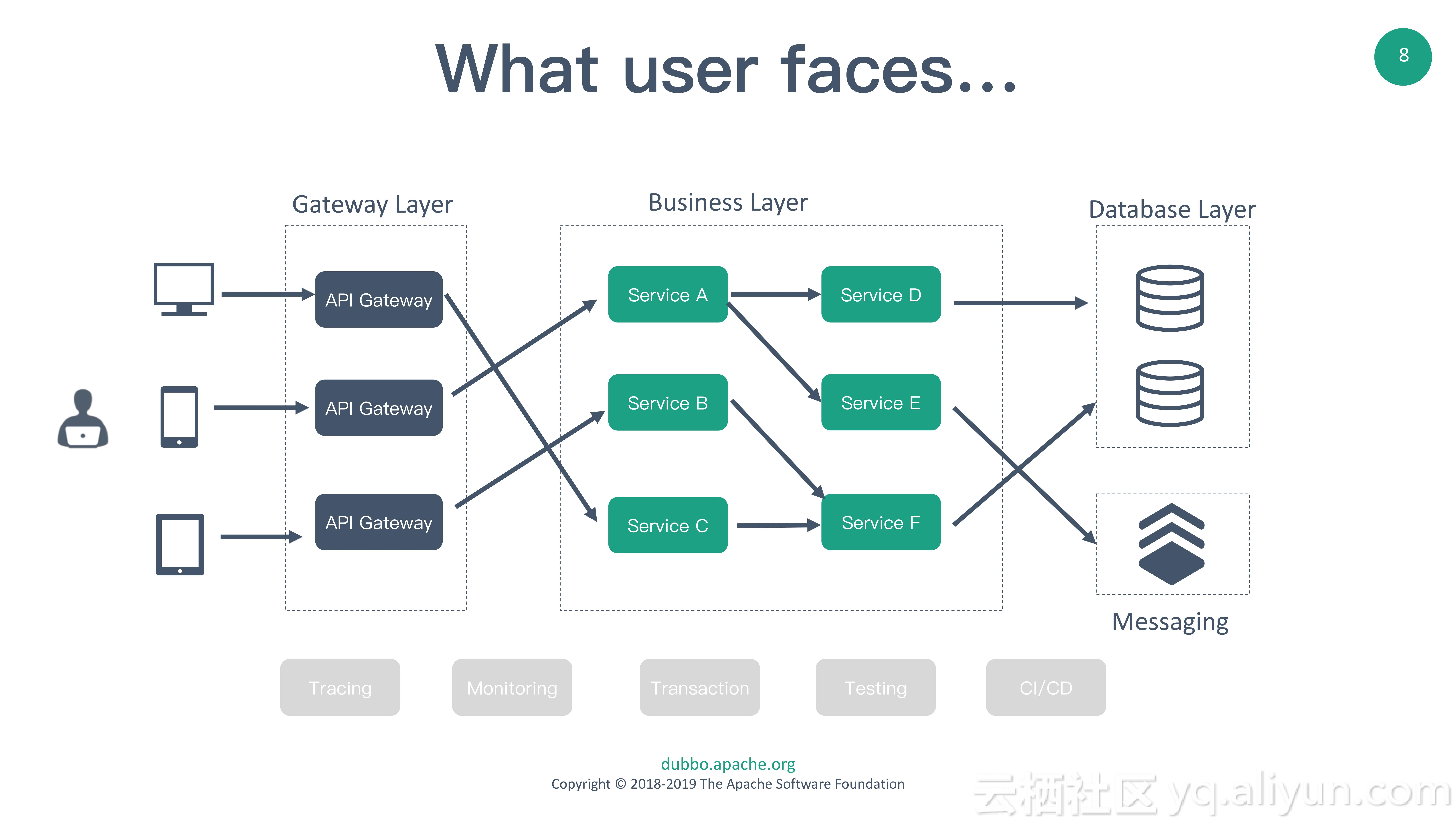
但是,开发者在实际的微服务开发过程中,需要的不仅仅是RPC和服务注册发现,而是需要一整套的微服务能力,例如API gateway、熔断限流、分布式监控和分布式事务等。但在这些方面,开发者由于没有事实上的推荐方案,调研和选型都比较痛苦,甚至会遇到个别开源项目不再继续维护给现有架构带来影响的窘境。所以如何通过Dubbo把这些微服务领域的其他能力整合起来,形成一套完整的解决方案,成为Dubbo社区一个亟待解决的问题。
生态定位和组件选择原则
起初,Dubbo这个品牌我们定义为一款RPC框架,而事实上,从业界开发者的反馈和调研来看,Dubbo的使用者早已脱离了单纯的RPC层面,而是将其作为一个微服务的架构基础来对待。
因此,我们对Dubbo的定位做过一次更新,Dubbo is more than a RPC framwork. Dubbo不仅仅是RPC框架,而是一个微服务框架,以帮助开发者快速构建高性能的微服务应用。

在此基础之上,我们做了进一步的演进,即从微服务框架演进到微服务生态。但Dubob不可能把微服务领域的所有能力重新再实现一遍,一是资源上无法保证,二是即便完成了,开发者也不一定会采用。最重要的是Dubbo已经社区化,Dubbo Ecosystem也应该由社区的方式来实现。因此,通过和开源的成熟方案做集成,形成一套完成的微服务领域生态,组成Dubbo Ecosystem,开发者无需为现有的系统做出过的的修改,就能快速开发微服务应用。
关于组件选择的原则,和哪些组件进行集成,并不是大而全的照单全收,而是经过社区挑选,符合以下三点:
- 已经具备很好的开发者群体和影响力的组件
- 在生产领域下得到过验证的组件
- 在某一方面成为标准或者事实标准的组件
只有满足上述条件,才会被纳入Dubbo Ecosystem。一方面用于减少用户选型的成本,另一方面Dubbo Ecosystem的组件也不会因为太过庞大而失去意义。总而言之,Apache Dubbo Ecosystem 是围绕 Apache Dubbo 打造的微服务生态,是经过生产验证的微服务的最佳实践组合。
体系总览和层级结构
作为一个微服务生态,它需要各个方面的组件共同组成。首先,我们需要明确一个微服务生态包含哪些组件才能称得上生态,以及各自的分工和重要程度。经过梳理,有了以下的Dubbo Ecosystem的层级结构图,包含从L0、L1、L2和L3的4个层级。
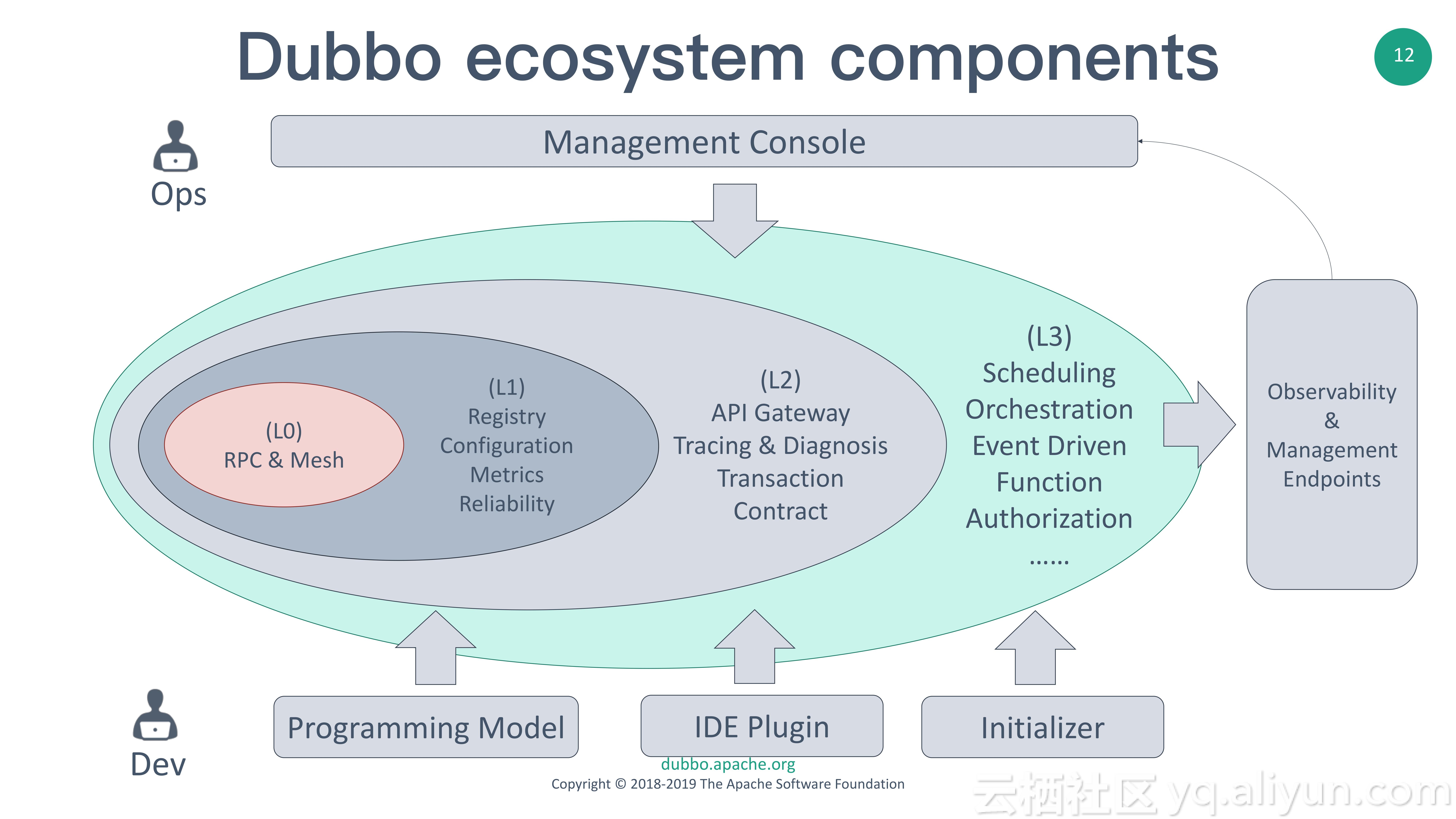
L0层包括了Dubbo的核心RPC和Service Mesh的能力。
RPC的核心能力方面,主要的演进方向是支持Reative,提供响应式编程的能力,提升系统整体的吞吐率,并基于一些先进的框架,例如RSocket来实现。
Service Mesh在解决多语言开发维护成本方面具有很大的优势,另外通过把通用逻辑下沉,把业务逻辑做薄做轻,开发者将释放更多精力专注到微服务业务逻辑开发中,并且不被语言所限制,因此Service Mesh也是L0层需要支持的一个重点。Dubbo Mesh最新的进展是data plane基于Envoy进行了扩展,已经能够识别到Dubbo的调用数据,并且能够上报Istio,然后基于这些数据执行后续一系列的动作,例如通过K8S进行自动扩容。
L1层包含了服务的注册发现、配置管理、系统高可用Reliability和Metrics的数据统计。
在服务注册发现层面,ZooKeeper一直是默认的配置,但是我们也发现,Dubbo目前的URL设计使得注册到ZooKeeper上的信息越来越多,里面有非常多的重复,随着集群规模的扩大,ZooKeeper逐渐成为瓶颈。在Dubbo 2.7中,已经支持了注册中心和配置中心的分离,使得Dubbo拥有了支持主流注册中心和配置中心的能力,注册中心的支持列表包括ZooKeeper、Nacos和Etcd,配置中心的支持列表包括Apollo和Nacos,后续还将对接更多主流的注册发现和配置管理产品。
在系统高可用Reliability层面,阿里巴巴开源的熔断限流组件Sentinel已经在阿里内部广泛使用多年,在熔断限流,流量控制,过载保护等都有非常优秀的表现,并且已经和Dubbo有了非常好的集成。同时,也支持Hystrix。
在Metrics层面,当前Dubbo的统计数据,还没有标准化,这块迫切需要一个标准Metrics统计实现。据了解,阿里巴巴内部流行的Metrics度量库(内部名称:Ali-Metrics)将会在2019年对外开源,作为集团Java应用埋点的事实标准,已经支持的集团内部业务包括:Sunfire监控、流量调度、Ali360、应用中心、菜鸟棱镜和无人值守发布等项目,待通过评估,它将成为Dubbo默认的Metrics度量实现。有了标准的Metrics实现,Dubbo接下来还会对接主流的开源监控系统,例如Prometheus。
如果说L0和L1是RPC领域的核心组件,那么L2层开始则更加贴近微服务领域。L2层包含API Gateway、分布式跟踪Tracing、分布式诊断Diagnosis和分布式事务Transaction等。
- API Gateway:协议转换是Dubbo作为一个微服务框架最被诟病的地方。API Gateway除了负载均衡和熔断限流等能力外,其最核心的能力是协议转换。例如,一个客户端如何通过HTTP能够请求一个Dubbo服务。无论是在内部服务迁移、跨语言调用,还是开发给外部第三方接口等场景,这都是比较明显的需求。业界有Spring Cloud Gateway、Zuul2和Kong等方案,目前倾向于和主流的方案进行集成。
- 分布式跟踪:现在已经支持的系统有Zipkin、Spring Cloud Sleuth和Skywalking等,后续会向业内标准靠拢,支持OpenTracing。
- 分布式诊断:未来会结合Arthas+Tracing的能力,进行分布式应用的快速问题诊断,通过分布式追踪系统,快速定位到某台单机,然后结合Arthas的能力对单点问题进行快速诊断。另外,Arthas 4.0将会演进到一个字节码框架,为第三方系统提供无侵入的、自定义埋点的能力。
总的来说,L2层的组件的思路将是由Dubbo社区主导,联合其他社区共建。
L3层的组件则更加开放一些。Scheduling、Event Driven、Authenthentication和Function等方面都还没有特别明确的方案出来,将会由第三方社区主导,形成开放生态。以Event Driven为例,社区主导使用的是RocketMQ,RocketMQ已经发布了C、C++、Python和Go客户端,并支持在Spring Boot中快速集成RocketMQ,同时支持Spring Message规范,方便开发者从其它MQ快速切换到RocketMQ。
在运维侧,Dubbo Ecosystem的数据会互相打通,各组件统一暴露Observability能力,最终通过Dubbo OPS进行展示和管控。例如,可以通过Dubbo OPS看到Dubbo Ecosystem中的熔断限流组件提供的熔断和限流数据,并对限流阈值进行管控等。
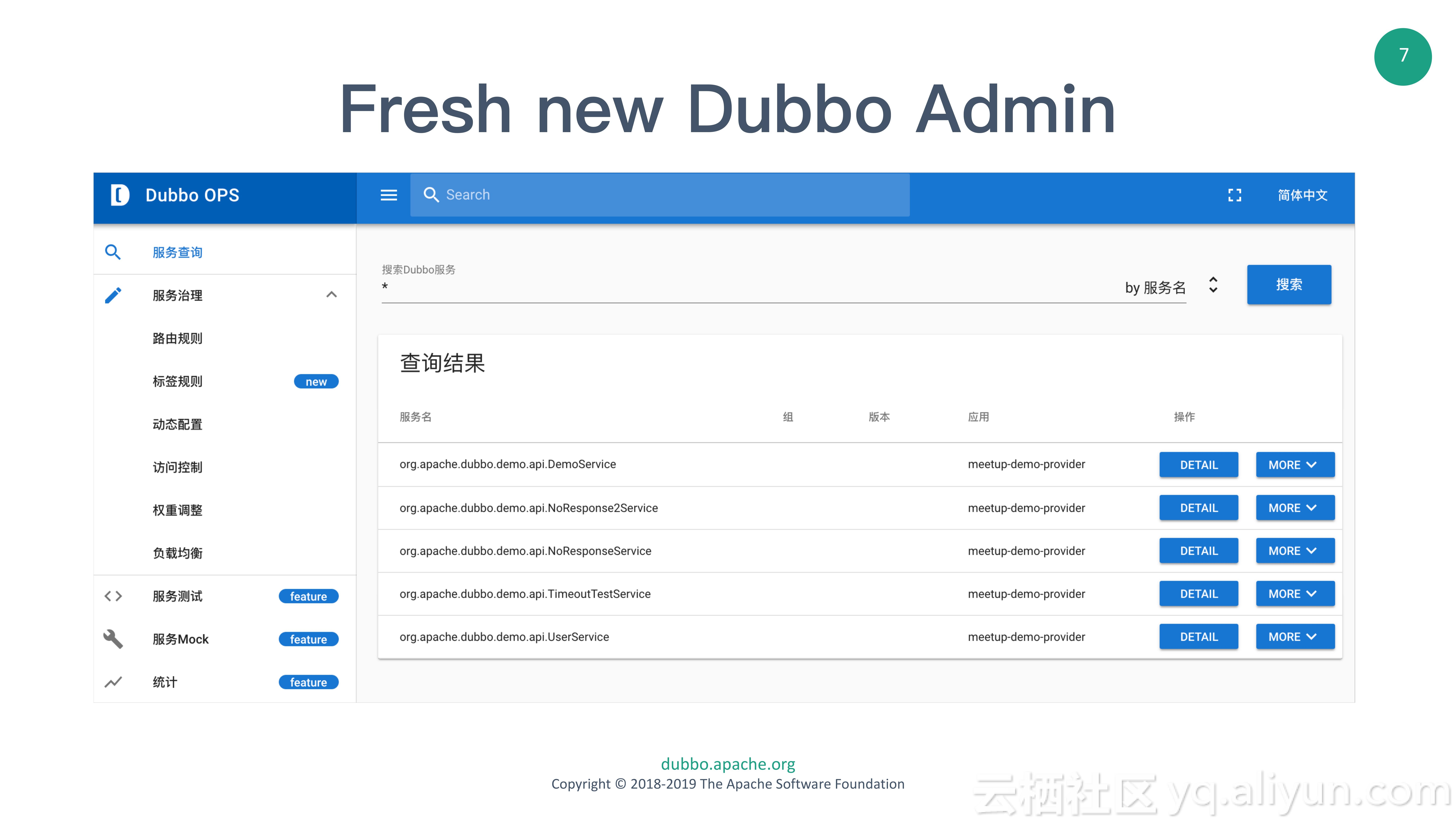
在开发侧,通过深度融入当前流行的编程模型,例如Spring Cloud/Spring Boot,帮助开发者快速上手,进行微服务开发。同时考虑提供IDE插件等,轻松构建脚手架,进一步优化开发体验。
通过上述层次结构的拆解,叠加上开发和运维侧提供的能力,逐步形成了一套完善的微服务体系。
在微服务开发中,多语言共存是一个常态,Dubbo社区一直重视多语言客户端的支持,目前已经实现了Node.js、PHP、Python和Go 4类语言,详细的支持列表可以参照上图。在Dubbo Ecosystem中,除了支持Java 微服务开发外,其他语言会继续由社区来主导建设。为了评估多语言实现的成熟度,我们计划提供一个多语言成熟度评估能力矩阵,通过标准的TCK测试用例,来对各种语言的能力进行验证,通过TCK意味着已经达到了一定成熟度,可以放心的使用。
和Spring Cloud之间的关系
经常会有开发者会拿Dubbo和Spring Cloud进行对比,在这里我们再次强调一下二者之前并没有竞争关系。Dubbo可以通过纯API、Spring容器启动(XML)和Spring-boot启动(注解)等多种方式启动,从Dubbo开源以来,和Spring一直有着紧密的集成。Spring Cloud也是开发者们赖以进行微服务开发的编程方式,帮助开发者快速搭建微服务应用是Dubbo的宗旨,因此Dubbo会尽可能的集成到Spring Cloud开发模式当中,开发者可以使用Spring Cloud轻松开发Dubbo微服务应用。
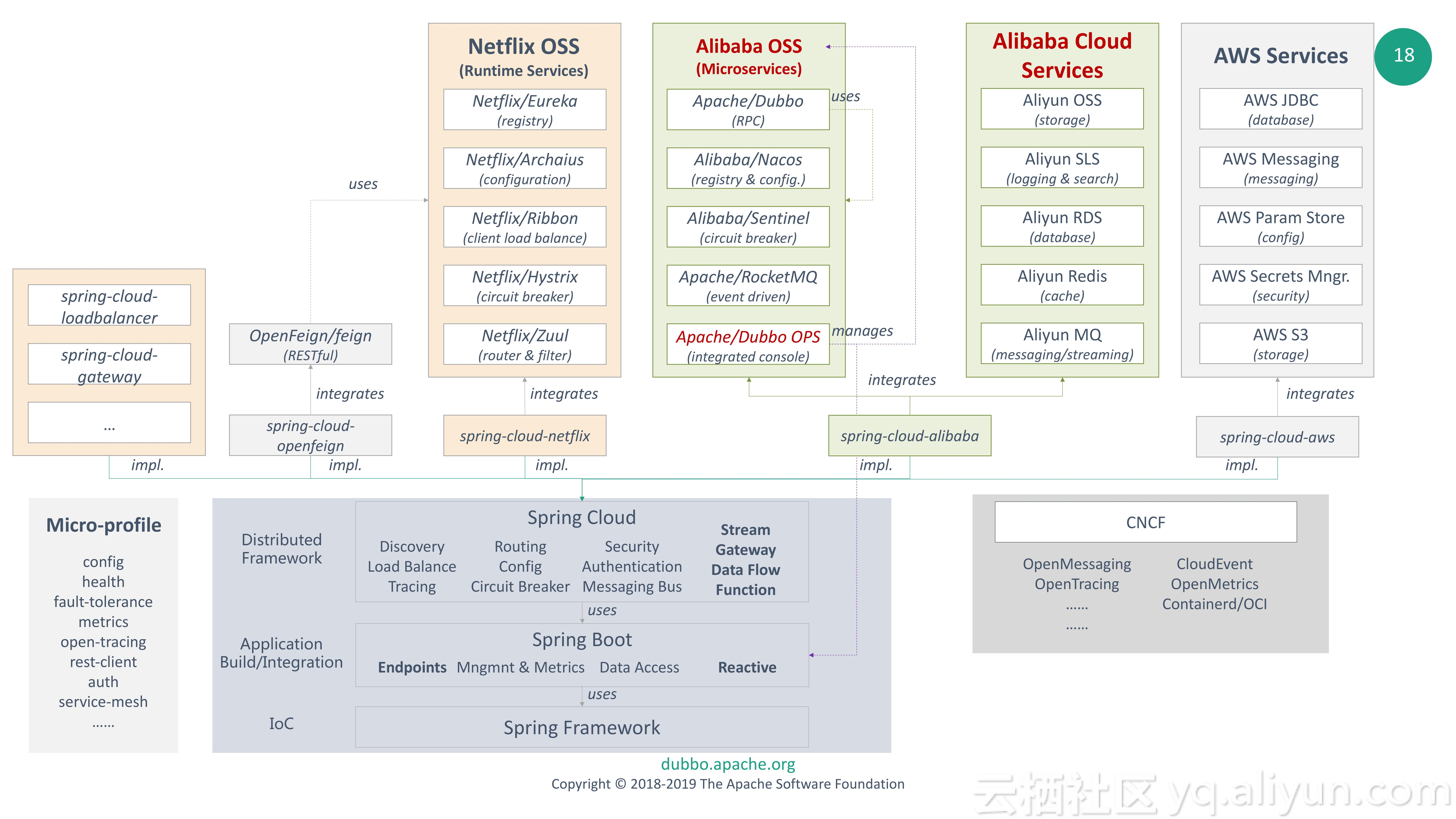
具体而言,阿里巴巴的开源套件将以Spring Cloud Alibaba的形式和Spring Cloud编程模型进行深度对接,而Dubbo的RPC将作为核心RPC组件被集成,同时,Dubbo Ecosystem中的组件包括服务发现和配置Nacos、熔断限流Sentinel和消息组件RocketMQ等都会被集成进Spring Cloud Alibaba中。另一方面,Spring Cloud Alibaba支持对接阿里云上的服务例如OSS、ACM和SchedulerX等等。
这里的深度集成主要包括两个方面,一方面Dubbo自身的服务通过REST协议暴露,自动和Spring Cloud中的组件,例如Feign和Ribbon等的集成。另一方面,Dubbo框架中的组件可以被进一步抽象,变成Spring Cloud生态中的一环,例如Dubbo的load balance组件可以单独抽出来,提供类似Ribbon负载均衡同样的能力。
总结
1、Apache Dubbo Ecosystem 是围绕 Apache Dubbo 打造的微服务生态,是经过生产验证的微服务的最佳实践组合,将把微服务领域中具备很好影响力的,在生产领域下得到过验证的,或在某一方面成为事实标准的组件纳入生态。
2、Apache Dubbo Ecosystem将围绕Dubbo打造4层体系,L0和L1专注RPC核心,L2专注微服务核心,L3围绕微服务周边打造丰富生态。
3、Apache Dubbo和Spring Cloud没有竞争关系,Apache Dubbo Ecosystem中的组件将以Spring Cloud Alibaba的形态深度集成到Spring Cloud体系当中,帮助用户提升微服务开发体验。
直播问答精选
Q1:Dubbo Ecosystem会有独立的官网么?
A1:Dubbo Ecosystem目前不会单独设立官网,我们会在 http://dubbo.apache.org 上线一个入口,介绍Dubbo Ecosystem的所有组件、各自的关系及推荐的整合方案。
Q2:请介绍下Dubbo Ecosystem的roadmap?
A2:Dubbo Ecosystem的发展将分为4个阶段,第一阶段是补全生态内的组件、Spring Cloud Alibaba对Dubbo 的支持、在官网建立入口、建立Dubbo OPS对微服务进行统一管控,第二阶段支持云原生,第三阶段引入Rsocket框架,第四阶段支持更多语言,不仅在RPC层提供多语言的支持,也会在整个微服务层提供多语言支持。
Q3:Dubbo2.7什么时候发布,Dubbo2.7是否兼容2.6和Dubbox(2.8.4),Dubbo3.0什么会有预览版?
A3:Dubbo2.7目前还在测试中,测试通过后会发到社区进行讨论和投票,然后再发布,预计1月会发布。Dubbo2.7会对2.6进行兼容,Dubbox已经合并到Dubbo,所以也是兼容的。在Github社区,Dubbo3.0的分支已经开出来了,Dubbo3.0会聚焦在Reative的实现,目前在调研的是RSocket框架,现在还没有确定的发布计划。
Q4:Dubbo in Action的书什么时候出版?
A4:这个问题是社区的issue之一,并被置顶。该书的章节已经确定了,但各章节的内容还没写完,我们希望社区的同学可以参与进来一起来写,认领相关的章节,提交PR,成为该书的作者之一。该书的出版目的是为了帮助开发者更好的使用Dubbo来构建微服务体系。












