
持久化
Redis 如同其他的存储组件一样,提供了两类持久化方式:快照,和全量追加日志。
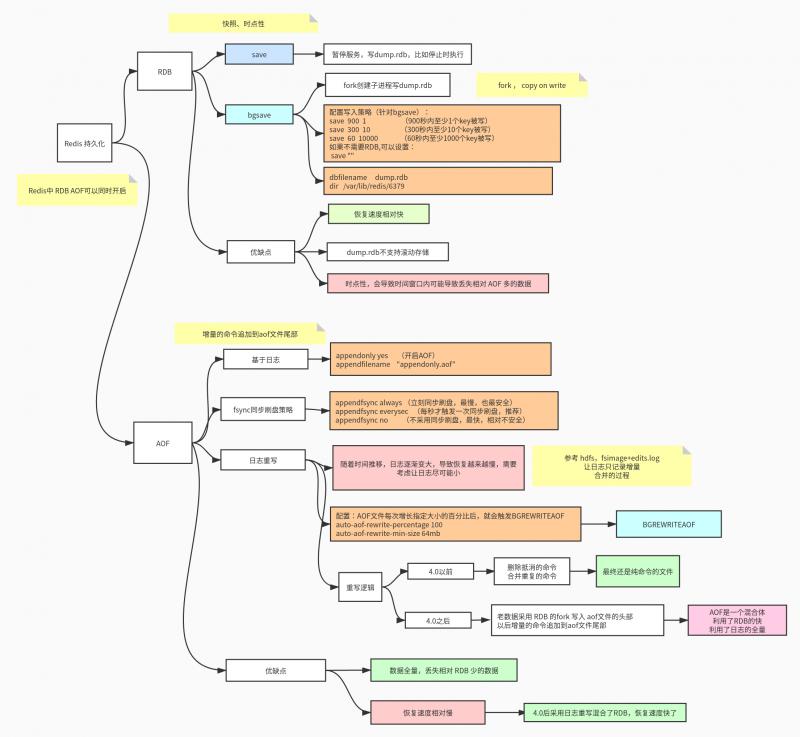
RDB - 快照
在默认情况下, Redis 将数据库快照保存在名字为dump.rdb的二进制文件中。 你可以对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动保存一次数据集。 你也可以通过调用 SAVE或者 BGSAVE , 手动让 Redis 进行数据集保存操作。 这种持久化方式被称为快照 snapshotting.
SAVE:暂停服务,写dump.rdb,比如停止时执行BGSAVE:通过fork系统调用创建子进程写 dump.rdb配置写入策略(针对bgsave):
save 900 1 #(900秒内至少1个key被写) save 300 10 #(300秒内至少10个key被写) save 60 10000 #(60秒内至少1000个key被写)
如果不需要RDB,可以设置:
save ""
设置 rdb 文件名称 和 存储目录
dbfilename dump.rdb dir /var/lib/redis/6379
AOF - 只追加操作的文件(Append-only file,AOF)
快照功能并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。 从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方式: AOF 持久化。
appendonly yes #(开启AOF)
appendfilename "appendonly.aof"
每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文件的末尾。 这样的话, 当 Redis 重新启时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的。
fsync 同步刷盘策略
你可以配置 Redis 多久才将数据 fsync 到磁盘一次。有三种方式:
每次有新命令追加到 AOF 文件时就执行一次 fsync :非常慢,也非常安全
每秒 fsync 一次:足够快(和使用 RDB 持久化差不多),并且在故障时只会丢失 1 秒钟的数据。
从不 fsync :将数据交给操作系统来处理。更快,也更不安全的选择。
推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
fsync同步刷盘策略
appendfsync always #(立刻同步刷盘,最慢,也最安全)
appendfsync everysec #(每秒才触发一次同步刷盘,推荐)
appendfsync no # (不采用同步刷盘,最快,相对不安全)
日志重写
因为 AOF 的运作方式是不断地将命令追加到文件的末尾, 所以随着写入命令的不断增加, AOF 文件的体积也会变得越来越大。 举个例子, 如果你对一个计数器调用了 100 次 INCR , 那么仅仅是为了保存这个计数器的当前值, AOF 文件就需要使用 100 条记录(entry)。 然而在实际上, 只使用一条 SET 命令已经足以保存计数器的当前值了, 其余 99 条记录实际上都是多余的。
为了处理这种情况, Redis 支持一种有趣的特性: 可以在不打断服务客户端的情况下, 对 AOF 文件进行重建(rebuild)。 执行 BGREWRITEAOF 命令, Redis 将生成一个新的 AOF 文件, 这个文件包含重建当前数据集所需的最少命令。
# 配置:AOF文件每次增长指定大小的百分比后,就会触发BGREWRITEAOF
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
从 Redis 4.0 开始,AOF重写逻辑变动了:
- 老数据采用 RDB 的
fork写入 aof文件的头部 - 以后增量的命令追加到aof文件尾部 这样的方式,AOF是一个混合体,利用了RDB的快,利用了日志的全量,使得 Redis 持久化更加安全和完善。
@SvenAugustus(https://www.flysium.xyz/)
更多请关注微信公众号【编程不离宗】,专注于分享服务器开发与编程相关的技术干货:












