
原文:Elasticsearch7.X 入门学习第一课笔记----基本概念
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接: https://blog.csdn.net/qq_36697880/article/details/100316518
一、ElasticSearch介绍
- 一个采用RESTful API标准的高扩展性的和高可用性的实时性分析的全文搜索工具
- 基于Lucene[开源的搜索引擎框架]构建
- ElasticSearch是一个面向文档类型的数据库
- es为非关系型数据,存储非结构化的数据
二、ElasticSearch概念
version:7.x
Near Realtime [准实时]
ES 是一个准实时的搜索平台,从一个索引创建到可搜索会有轻微的延迟,一般在1秒以内。
Cluster [集群]
集群由一到多个节点组成,这些节点共同存储了所有数据,并提供了跨节点的联合索引和搜索功能。
集群由一个唯一的名称指定(默认为 elasticsearch ),节点可以被设置为通过名字加入集群,所以集群名称比较重要。
确保不要在同一个网络环境中为不同的集群使用听一个名字(跟ES的服务发现机制有关),否则你的节点可能会加入到错误的集群中。例如对于日志服务来说,可以使用log-dev,log-pre, log-prod 来简历不同的集群环境。
ES 的集群环境是自动组织的,只需要指定相同的集群名即可。
请注意,拥有一个只包含单个节点的集群是完全正常的。此外,您还可以拥有多个独立的集群,每个集群都有自己唯一的集群名称。
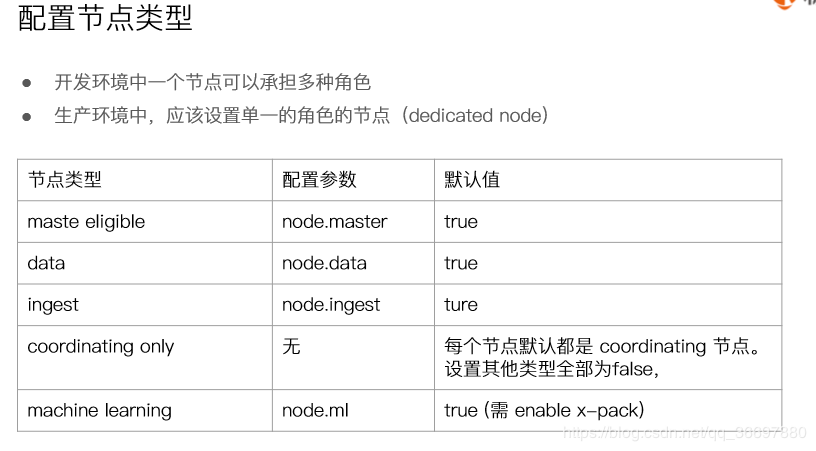
Node [节点]
Node 是组成集群的一个单独的服务器,用于存储数据并提供集群的搜索和索引功能。与集群一样,节点也有一个唯一名字,默认在节点启动时会生成一个uuid作为节点名,该名字也可以手动指定。此名称对于项目管理非常重要,用来在网络中标识哪个服务器与哪个节点对应。
节点可以按照配置的集群名加入集群。默认情况下(假设各个节点可以相互发现),节点会加入到名为elasticsearch的集群中。
单个集群可以由任意数量的节点组成。如果只启动了一个节点,则会形成一个单节点的集群。



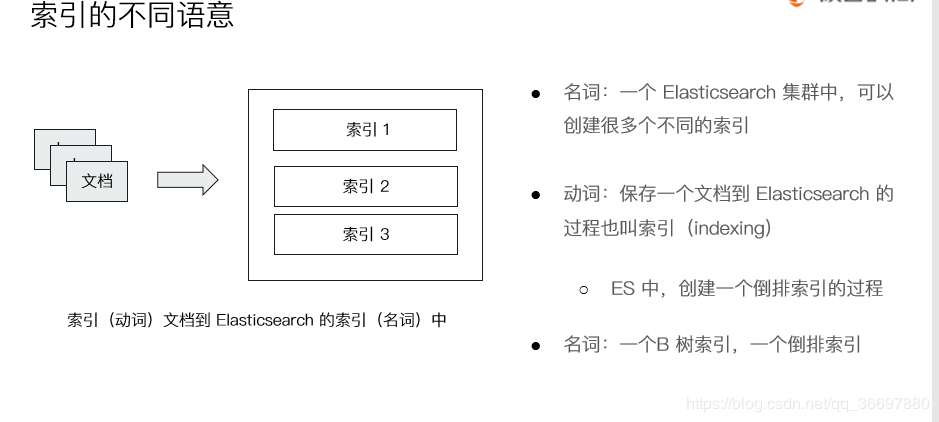
Index [索引]
Index 有两层意思,作为动词表示建立索引 ,名次表示建立好的索引文件。
索引时具有某些类似特征的文档集合。例如客户索引、产品索引、订单索引等。
索引由一个全小写的名称标识,对数据的添加、删除、更新、搜索等操作,均需指定索引名称。
单个集群中可以创建任意数量的索引。

Mapping Type [类型]
之前的版本中,索引和文档中间还有个类型的概念,每个索引下可以建立多个类型,文档存储时需要指定index和type。从6.0.0开始单个索引中只能有一个类型,7.0.0以后将将不建议使用,8.0.0 以后完全不支持。
类型用于定义文档属性,包括类型、分词器等。
弃用该概念的原因:
在之前的版本中把Index比作 RDB 的 Database,Type 比作 RDB 的 Table。这种不太恰当,RDB 中,Table 之前相互独立,同名的字段在两个表中毫无关系。但是在ES中,同一个 Index 下不同的 Type 如果有同名的字段,他们会被 luncene 当作同一个字段 ,并且他们的定义必须相同。所以,实际上之前的说法是不对的。因此 ES 官方将逐渐弃用 Type 的概念,每个Index只能定义一个 Mapping Type。
Document [文档]
文档是构建索引的基本单元。例如一条客户数据、一条产品数据、一条订单数据都可以是一个文档。文档以json格式表示,json是一种普遍使用的互联网数据格式。
在index中可以存储任意数量的文档。虽然文档在物理上存储在索引文件中,但是必须在存储文档时将其分配给索引中特定的类型。


Shard and Replicas [分片和副本]
Shard
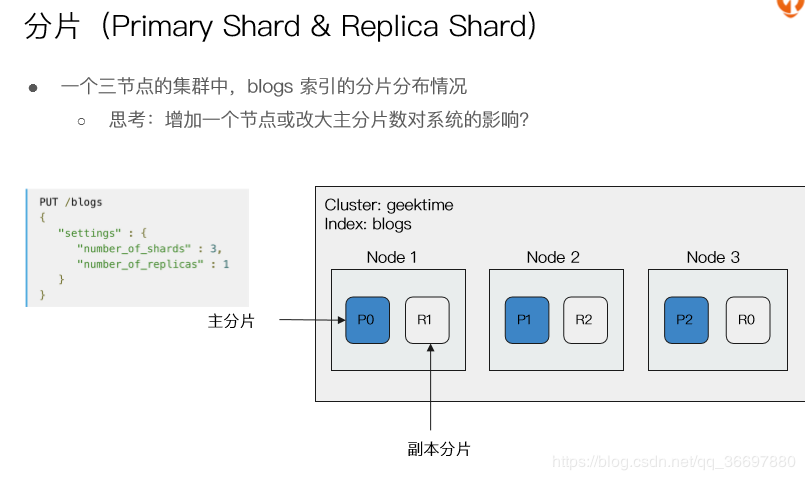
一个索引可以存储大量的数据,甚至超出单个节点的磁盘存储空间。例如一个索引存储了数十亿文档,这些文件占用超过1T的磁盘空间,单台机器无法存储或者由于太多而无法提供搜索服务。
为了解决这个问题,ES 提供了将单个索引分割成多个分片的功能。创建索引时,可以指定任意数量的分片。每个分片都是一个功能齐全且独立的“index”,且可以被托管到集群中的任意节点上。
分片有两个重要作用:
- 提供了容量水平扩展的能力;
- 多个分片云允许分布式并发操作,可以大大提高性能;
数据存储在哪个分片和搜索时文档聚合的机制完全由ES负责,这点对于用户来说是透明的。
Replicas:
在网络/云环境中随时可能发生故障,如果能在这些异常(不管什么原因导致分片下线或丢失)发生时有一定的容错机制,那真真是极好的。因此,ES 允许我们为分片生成一个或多个副本。
副本有两个重要作用:
- 服务高可用:分片异常时,可以通过副本继续提供服务。因此分片副本不会与主分片分配到同一个节点;
- 扩展性能:由于查询操作可以在分片副本上执行,因此可以提升系统的查询吞吐量;
数据层面,一个索引可以被分割为多个分片。一个索引可以指定零到多个副本,一旦指定副本,就会存在主分片和副本分片的概念。分片数和副本数可以在创建索引时指定,也可以动态修改。
通过_shrink 或_split API 可以修改分片数量,但是这种操作比较困难,最好在创建时指定。
默认情况下,7.0以前一个索引有5个分片,1个副本(单节点时即使指定副本为1也不会创建副本),所以一个索引共10个分片。
7.0以后一个索引只有1个分片
每个分片都是一个Lucence索引。Lucence 对单个索引有最大文档数的限制,在 LUCENE-5843规范中,最大数量为2,147,483,519(int.MAX_VALUE - 128)。可以通过/_cat/shards?v 查看分片状态。

三、ElasticSearch和关系型数据库对比

四、ElasticSearch架构图
1.Gateway
- gateway是ES数据存储的格式
- 可以使用hdfs,本地,亚马逊的s3等多种存储方式
- 存储索引信息,集群信息,mapping, 索引碎片信息,以及transaction logs
2.Distributed Lucene Directory
- Lucene框架 es就是基于Lucene框架开发的
- Lucene框架服发现等
3.Index Module
- 创建索引的模块
4.Search Module
- 搜索模块
5.Mapping
- 相当于mysql里的schema
6.river
- 从外部获取异构数据 来创建索引
7.Discovery
- 节点启动后会互相ping 根据在es.yml配置文件里找到对应的端口
- 进行开始选举,从各个节点任务的master中选,进行id字典排序,选择第一个
- 如果各个节点上都没有认为的master, 那么就从所有节点中选择
- 如果就一个节点 那么master就是她自己
- ES支持任意数目的集群,通过一个规则,只要所有的节点都遵循同样的规则,得到的信息都是对等的,选出来的主节点肯定是一致的. 但分布式系统的问题就出在信息不对等的情况,这时候很容易出现脑裂(Split-Brain)的问题,大多数解决方案就是设置一个quorum值,要求可用节点必须大于quorum(一般是超过半数节点),才能对外提供服务。而 Elasticsearch 中,这个quorum的配置就是 discovery.zen.minimum_master_nodes
8.Scriptsing
- 脚本执行功能 对查询出来的数据进行处理
- 支持多种语言
9.3rdplugins
- 支持安装第三方插件
10. transport
- 是支持的协议类型 默认使用http进行交互











