
前言
主从复制,即主机数据更新后根据配置和策略,自动同步到备机的master/slave机制,Master以写为主,Slave以读为主。主要用于读写分离和容灾恢复
一. 如何使用
1. “一主二仆”
1.1 修改配置文件
"一主二仆"是指一台主机,两台从机,我们在虚拟机中模拟这三台机器(即让redis服务在三个不同的端口运行),先拷贝两份redis配置文件,并重命名以便启动时区分

再在每份配置文件中修改如下配置项(此处以redis6380.conf为例):
a). 指定端口(重要)
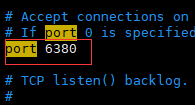
b). pidfile
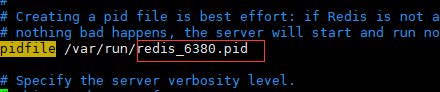
c). logfile
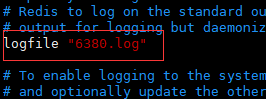
d). dbfilename
e). 开启daemonize yes
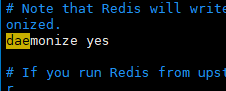
*以上配置项按照配置文件不同做相应修改
因为是在一台CentOS虚拟机上模拟了三个redis服务器,因此需要在开启客户端命令的后面加上端口号加以区别,否则默认会进入到6379端口的客户端。例如,要进入6380端口的客户端,使用命令
redis-cli -p 6380
三个客户端同时启动如下:
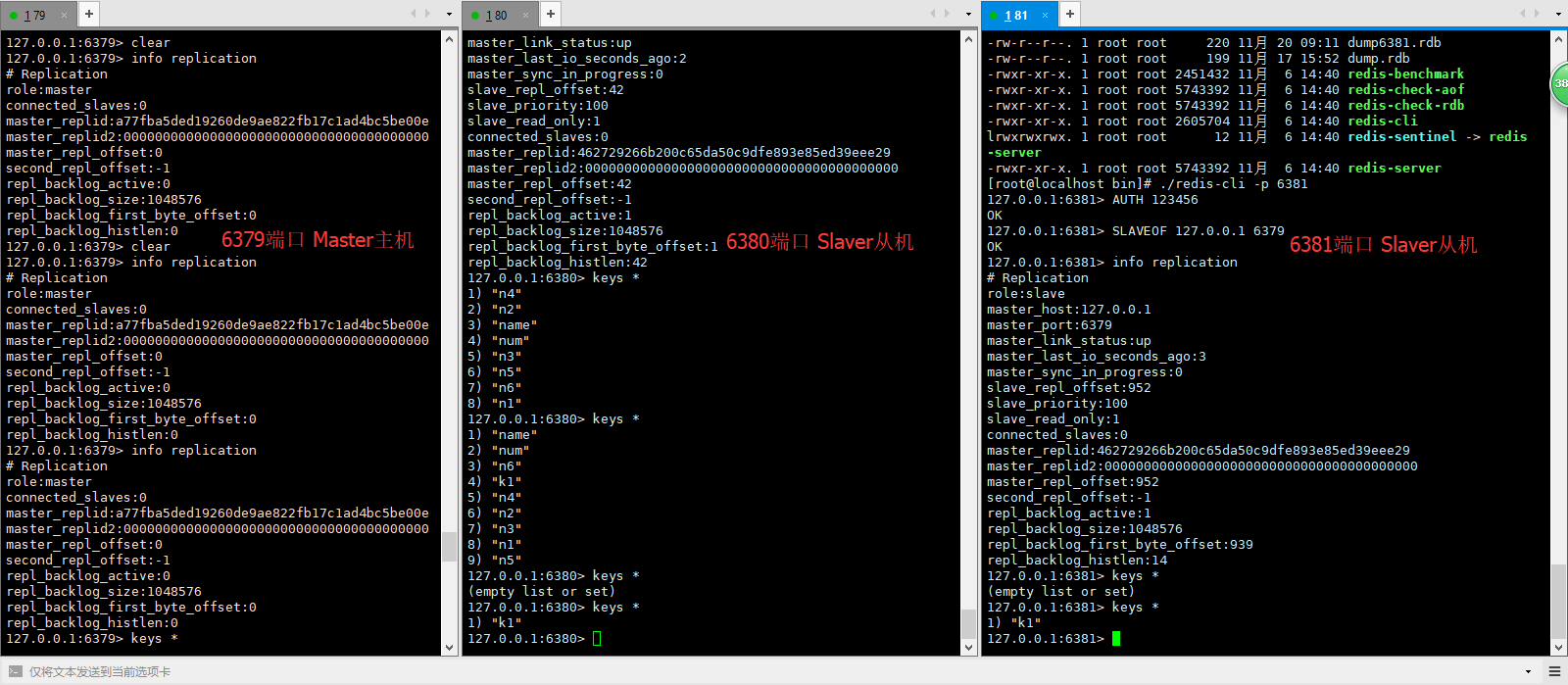
在6379端口Master主机输入info replication,可以查看主机与从机之间的连接情况
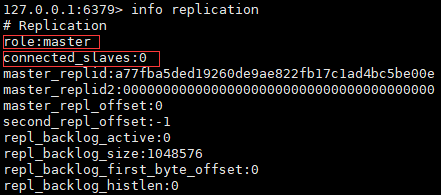
可以看到,现在6379端口的role是master,connected_slave如同其字面意思,代表连接上的从机,此时是0个。Slave从机在进行连接之前,输入info replication得到的结果和上面是一样的。
1.2 从机连接主机
在两个从机中使用如下命令,或者将如下命令写到配置文件中
slaveof <主机IP> <主机端口>
提示ok后,再在两个从机中输入info replication命令应该会得到如下结果:
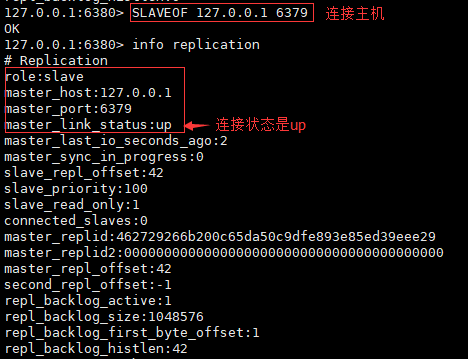
此时,主机中info replication命令执行后得到
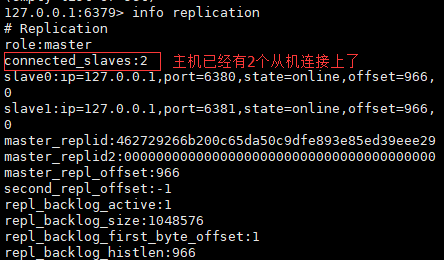
此时,主从连接就已经建立了。如果在主机中set了字段,两个从机会立即各自复制一份,保持和主机的数据同步,因此,在从机中也可以get到该字段的值。另外,从机会开启只读模式,里面的数据不能手动删除或更改,只能跟随主机中的数据的变化而变化。从机一旦连接上主机,就会把主机中所有数据都拷贝过来(并不是只复制连接上主机后,主机中后来添加的数据)。
但是这里连接还可能遇到一些小问题,就是如果主机设置了连接校验密码(具体可以参看jedis初探的第三节),直接按照上面slaveof命令操作的话虽然也会返回ok,但实际上并没有连接成功(可以自行用info replication命令测试),遇到这样的问题可以采用如下解决办法:
修改从机配置文件,将masterauth的注释取消,并将主机的连接校验密码填上,如下图
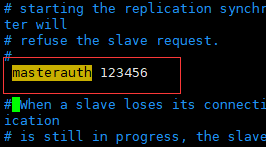
保存文件后,重启redis服务,再进行slaveof连接主机,就可以成功了。
1.3 总结
- 配从(库)不配主(库)
- 从库配置:slaveof 主库ip 主库端口(每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件)
- 可以使用info replication查看连接情况
2. “薪火相传”
2.1 什么意思
在上面的“一主二仆”中,是1台主机连接了2台从机,但实际情况中,主机连接的从机数量可能有多台,如下图,连接的从机数量越多,主机的负担越重
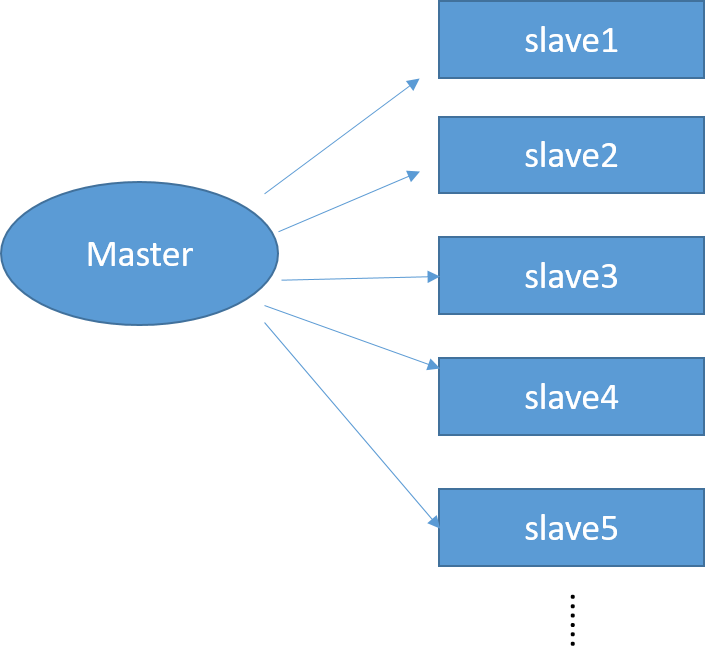
下图这种模式就是一种“去中心化”的模式,从机不再是集中从Master复制数据,而是可以从其他从机中复制,减轻了主机的负担。如下图中slave2就是从slave1中复制的数据

因此,所谓的“薪火相传”指的是:上一个slave可以是下一个slave的master,slave同样可以接收其他slaves的连接和同步请求,该slave作为了链条中下一个的master,可以有效减轻master的写压力。
2.2 一个例子
6379端口的作为master机,6380端口的作为slave1,连接master,6381端口的作为slave2,连接slave1。连接图示和上面相同。连接成功后,master写入数据,slave1马上就会复制一份,而slave2也会马上从slave1中复制一份。此时,slave1的身份信息如下:
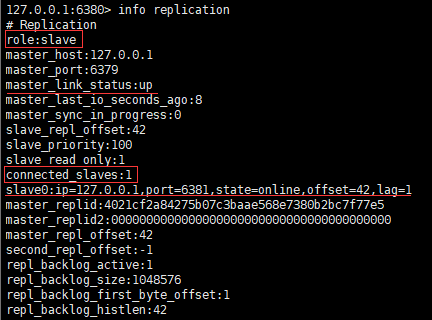
它虽然担当了slave2的master,但它本身还是要从6379端口的master机中复制数据,所以它的role为slave,同时,因为slave2连在它身上,所以connected_slaves显示连接的从机数为1。
这种“薪火相传”的使用方法也很简单,slave2之前连接的是6379端口的master,现在要改连接到6380端口的slave1,只需要使用如下命令:
slaveof 127.0.0.1 6380
#slaveof <从机ip> <从机端口>
需要注意的是:中途变更转向,会清除之前的数据,重新建立拷贝最新的。什么意思呢?slave2原来连接的是6379端口的master,其数据库中就有master机的全部数据,改变连接后,就会删除这些数据,重新建立对slave1的数据拷贝
3. “反客为主”
使当前数据库停止与其他数据库的同步,转成主数据库
使用命令:slaveof no one
举个例子:
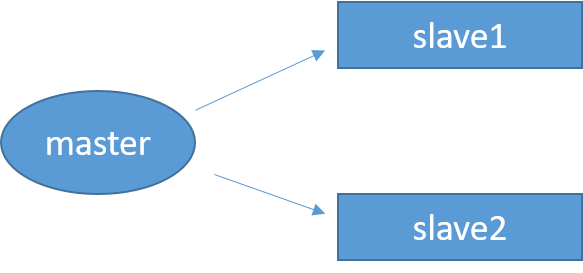
在上图的主从关系中,如果master主机突然“挂了”,这时,slave1和slave2所采取的操作是“原地待命”,一直等待master重新回来。此时,可以在一个从机中使用slaveof no one 命令,让从机变成主机,继续担当master的任务。这时,其他从机可以转连接到该主机上,重新组成一个主从体系。
4. 使用jedis进行主从复制
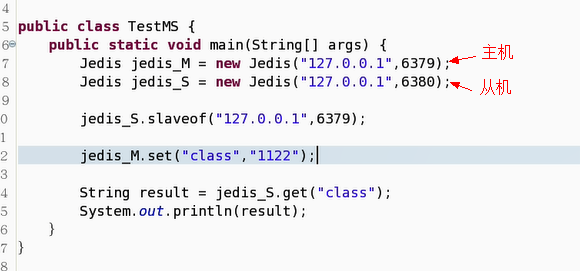
但是程序执行中可能出现下面这种情况:
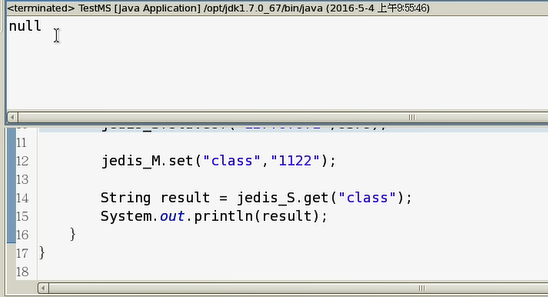
结果为null值,这里并不是程序出了什么错,而是内存数据库太快了,导致没有取到值(程序慢于内存,redis中已经有值了,而程序还没取到)。如果你在redis客户端使用get命令(或者再运行一遍程序),就会发现其实是有值的。
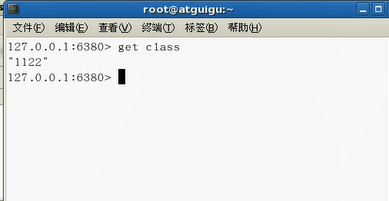
注意:主从的配置(slaveof)一般不在代码中控制,而是由架构/技术经理规定好主从关系,并在后台使用unix命令配好,开发人员需要关注的是谁是主谁是从,以及主从的读写操作即可。
二. 复制原理
- Slave启动成功连接到master后会发送一个sync命令
- Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集的命令, 在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
- 全量复制:slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步。
- 只要是重新连接master,一次完全同步(全量复制)将被自动执行。首次是全量复制,之后是增量复制。
三. 复制的缺点
复制延时:由于所有写操作都是先在master上操作,然后同步更新到slave上,所以从master同步到slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重。slave机器数量的增加也会使这个问题更加严重
四. 哨兵模式(常用)
1. 是什么
哨兵巡逻,能够后台监控主机是否故障,若主机发生故障就会自动在剩余的从机中通过投票的方式选出新的主机,并自动进行切换。简单来说是上面“反客为主”的自动版,但是也有些不同的地方。
2. 使用步骤
2.1 在redis安装目录下新建sentinel.conf文件,名字绝对不能错
2.2 配置哨兵,填写内容。在sentinel.conf中填写如下内容
sentinel monitor 被监控的主机的名字(名字自己起)127.0.0.1 6379 1
#上面最后一个数字1,表示最低通过票数(主机挂掉后投票看让谁接替成为主机)
2.3 启动哨兵
如上图所示,我们需要用到redis/bin目录下的redis-sentinel工具,启动时还需要带上我们刚才设置的配置文件,启动命令及启动效果如下:
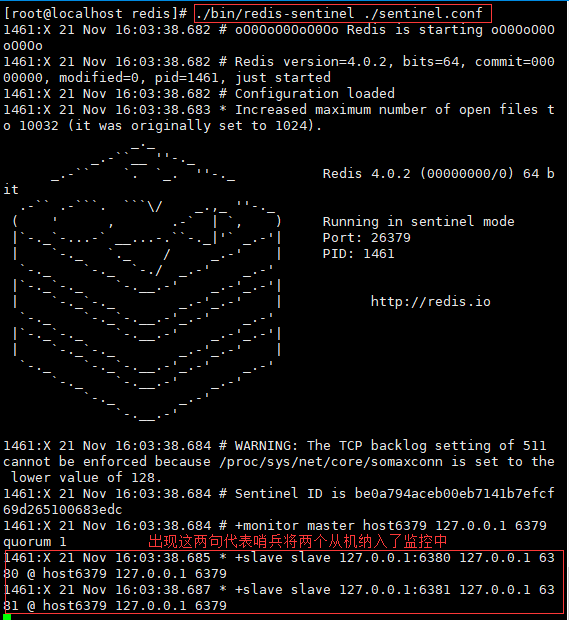
3. 遇到的问题
学习过程中遇到主机挂掉后,哨兵自动切换出现故障的问题,具体表现为:主机挂掉后,重新启动连接不上新的主机;且有的时候,从机也连不上新的主机。为此十分苦恼,在查阅了相关资料并进行了一些试验后发现,原来是因为我的redis是设置了校验密码的,这里的配置中需要增加一些内容,具体如下:
1). 在哨兵的配置文件sentinel.conf中,增加主机校验密码,改成如下内容:
sentinel monitor mymaster 127.0.0.1 6381 1
sentinel auth-pass mymaster 123456 #增加主机校验密码
2). 在redis配置文件中(包括主机和从机),都添加requirepass和masterauth配置
requirepass "123456"
masterauth "123456"
需要注意的是,主机从机都尽量设置一样的密码!并且主机中要添加masterauth,这点很容易被忽略,因为主机在挂掉后重新启动,它将作为从机去连接新的主机,如果没有这项就会导致连接不上新的主机。
在这个过程中,哨兵日志是“滞后”的,比如有时候重新启动主机,查看其info replication显示它连接的是另一个从机而不是新主机,且连接状态是down,过一会儿,日志中才更新消息,将其连接改为连接到新主机
五. 参考资料
https://www.cnblogs.com/qlong8807/p/5893422.html(redis哨兵配置详解)
http://blog.csdn.net/a67474506/article/details/50435498(解读redis哨兵日志内容)












